LOD函数的全称是详细级别表达式(Level Of Detail Expressisons)。它主要是为了克服一些表达式之间计算粒度不一致的问题,本文将详细为您介绍如何使用LOD函数。
使用场景
详细级别表达式,其中详细级别指数据聚合粒度的层次,不同的级别代表着数据不同的聚合度和粒度,能够处理在一个可视化视图中包含多个数据详细级别的问题。
如果分析过程中需要添加一个维度,其明细程度高于或者低于已有视图的可视化明细程度,但又不希望改变现有图形展示内容,就可采用详细级别表达式功能。
操作步骤
数据集编辑页面单击新建计算字段,进入配置弹窗页面。
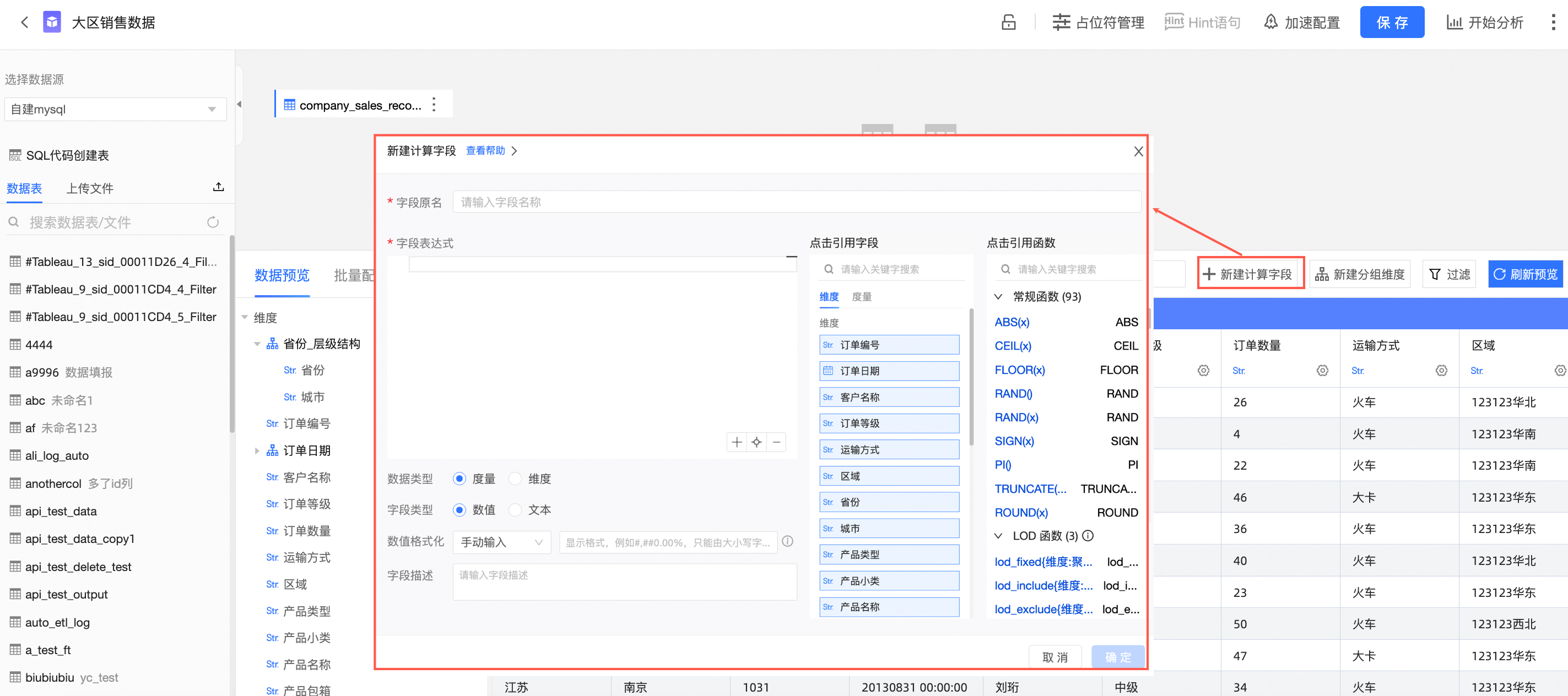
填写字段名称(①),在字段表达式中选择需要引用的LOD函数及字段(②),并配置字段类型等配置项(③)。
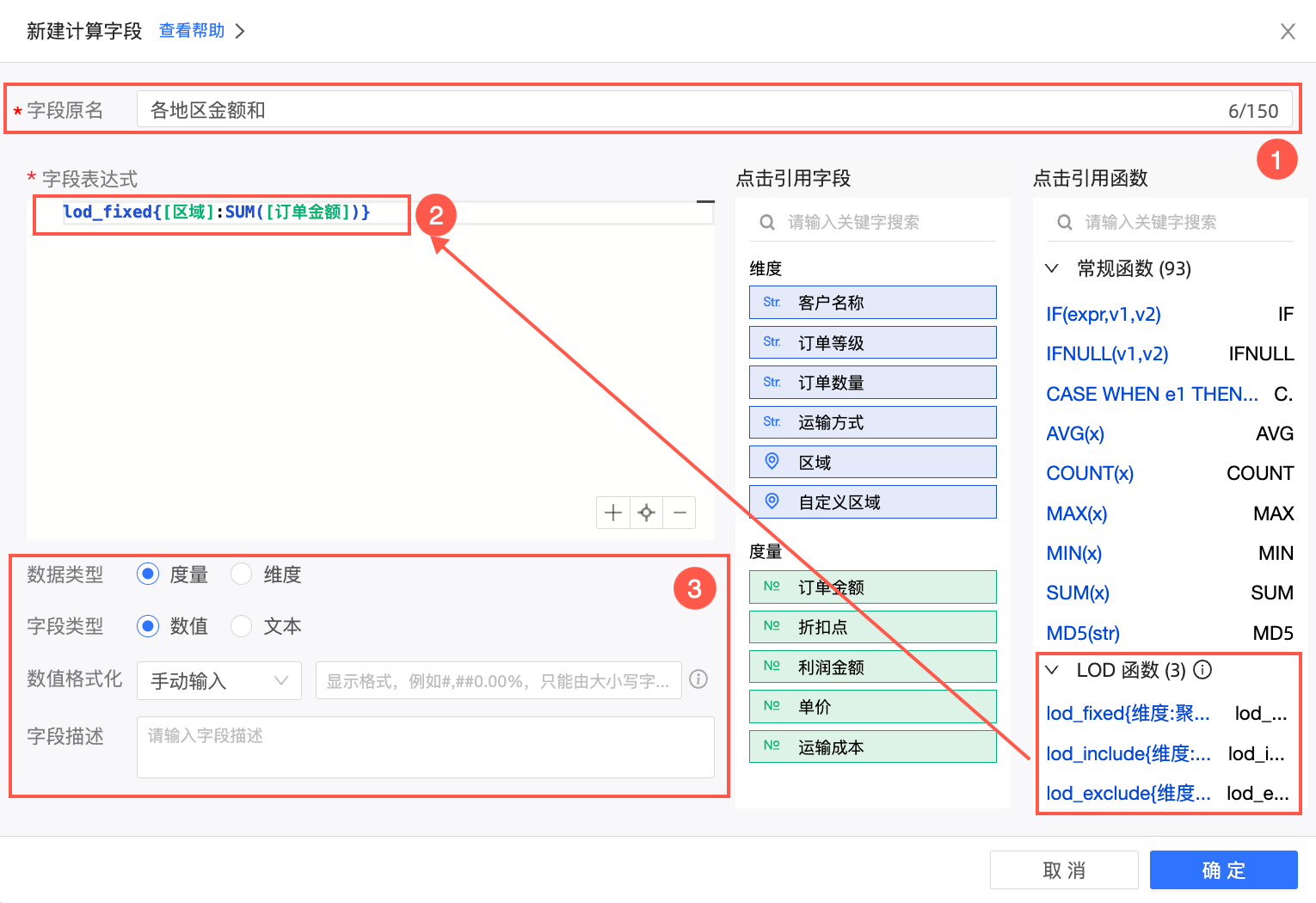
新建完成后,单击确定按钮。使用新增字段创建仪表板图表时,可以看到相同区域的订单金额总额,不受产品类型影响而变化。
表达式说明
基本公式
三种LOD表达式的使用结构和语法分别如下:
使用结构
lod_ fixed{<维度声明> : <聚合表达式>}
lod_ include{<维度声明> : <聚合表达式>}
lod_ exclude{<维度声明> : <聚合表达式>}
示例:lod_fixed{ [订单日期]:sum([订单金额])}
语法说明
fixed |include|exclude :定界关键字,制定了LOD的范围。
<维度声明>:指定聚合表达式要连接到的一个或多个维度。使用逗号分隔各个维度。
<聚合表达式>:聚合表达式是所执行的计算,用于定义目标维度。
过滤条件
在Quick BI中除了基本的公式外,还支持写过滤条件,具体表达式如下,以冒号隔开维度声明、聚合表达式和过滤条件。
lod_fixed{维度1,维度2...:聚合表达式:过滤条件}
lod_include{维度1,维度2...:聚合表达式:过滤条件}
lod_exclude{维度1,维度2...:聚合表达式:过滤条件}
过滤条件非必填。
除了表达式内的过滤条件之外,其他过滤条件不对lod_fixed函数生效,包括过滤器、查询控件等。
fixed函数应用
fixed详细级别表达式使用指定的维度进行计算,而不引用其他任何维度。
应用场景一:计算每个区域的销售金额总和
场景描述
当您在分析地区分布下销售订单情况时,数据表中存在维度区域和省份,需要用fixed计算区域对应的金额总和,因为fixed详细级别表达式不考虑其他维度级别,只计算表达式中引用的维度,故可以计算出对应区域的销售金额和。
操作步骤
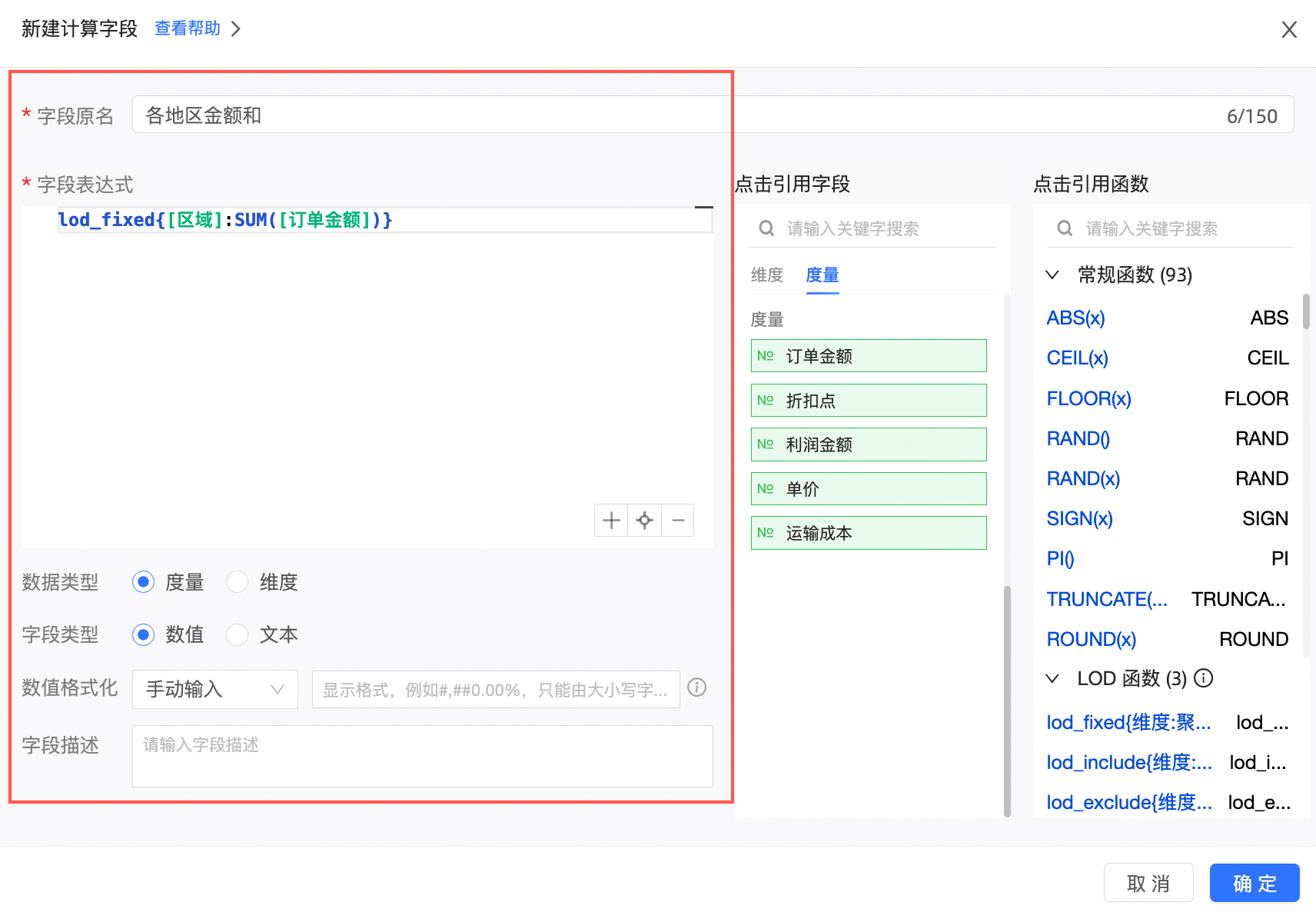
新建计算字段
字段表达式:lod_fixed{[区域]:SUM([订单金额])}
含义:按照区域求出订单金额的和。
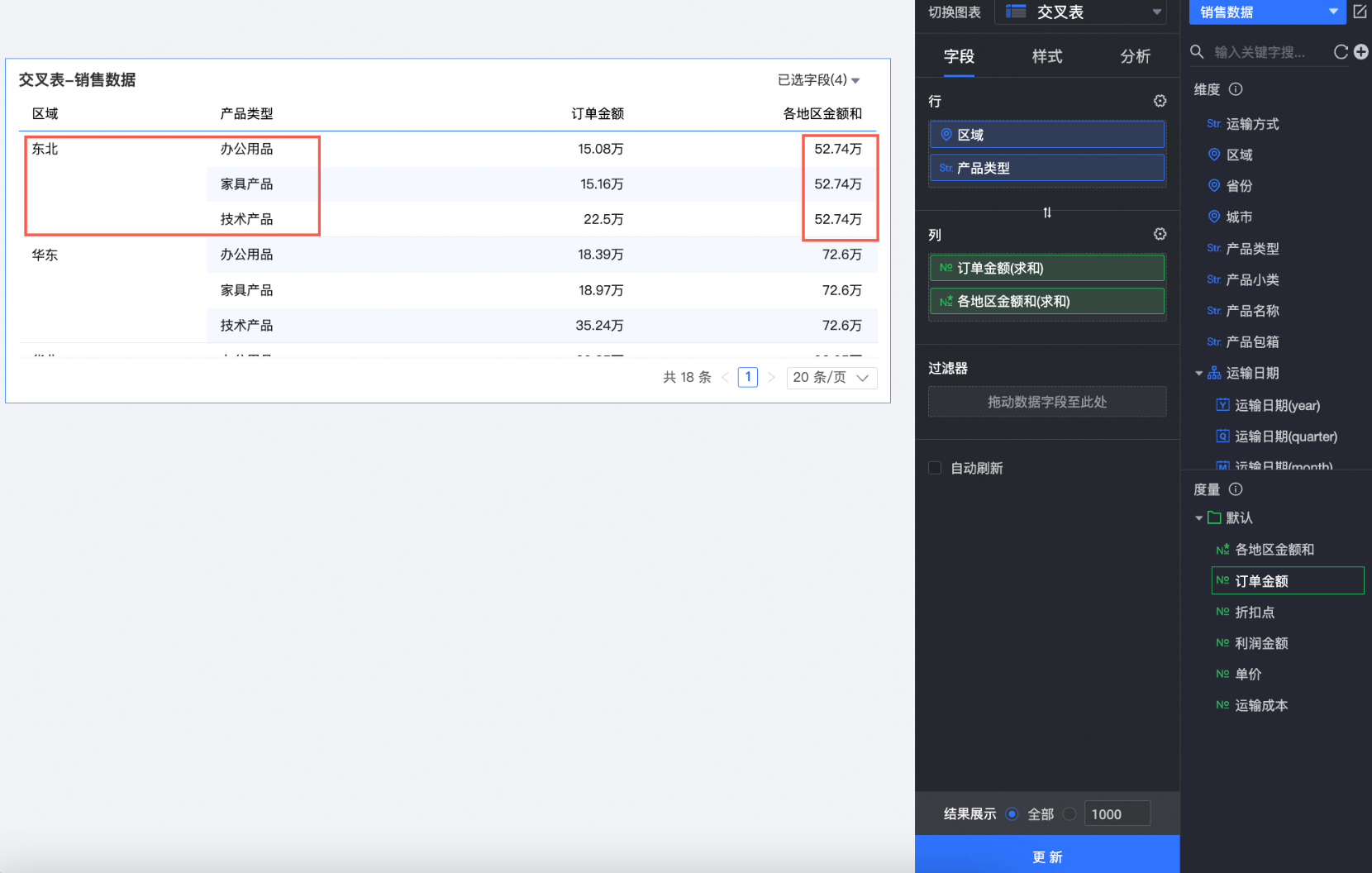
创建图表。
本例中,我们创建一个交叉表。
将上一步创建的各地区金额和字段拖入列区域,将区域、省份字段拖入行区域,单击更新后系统自动更新图表。
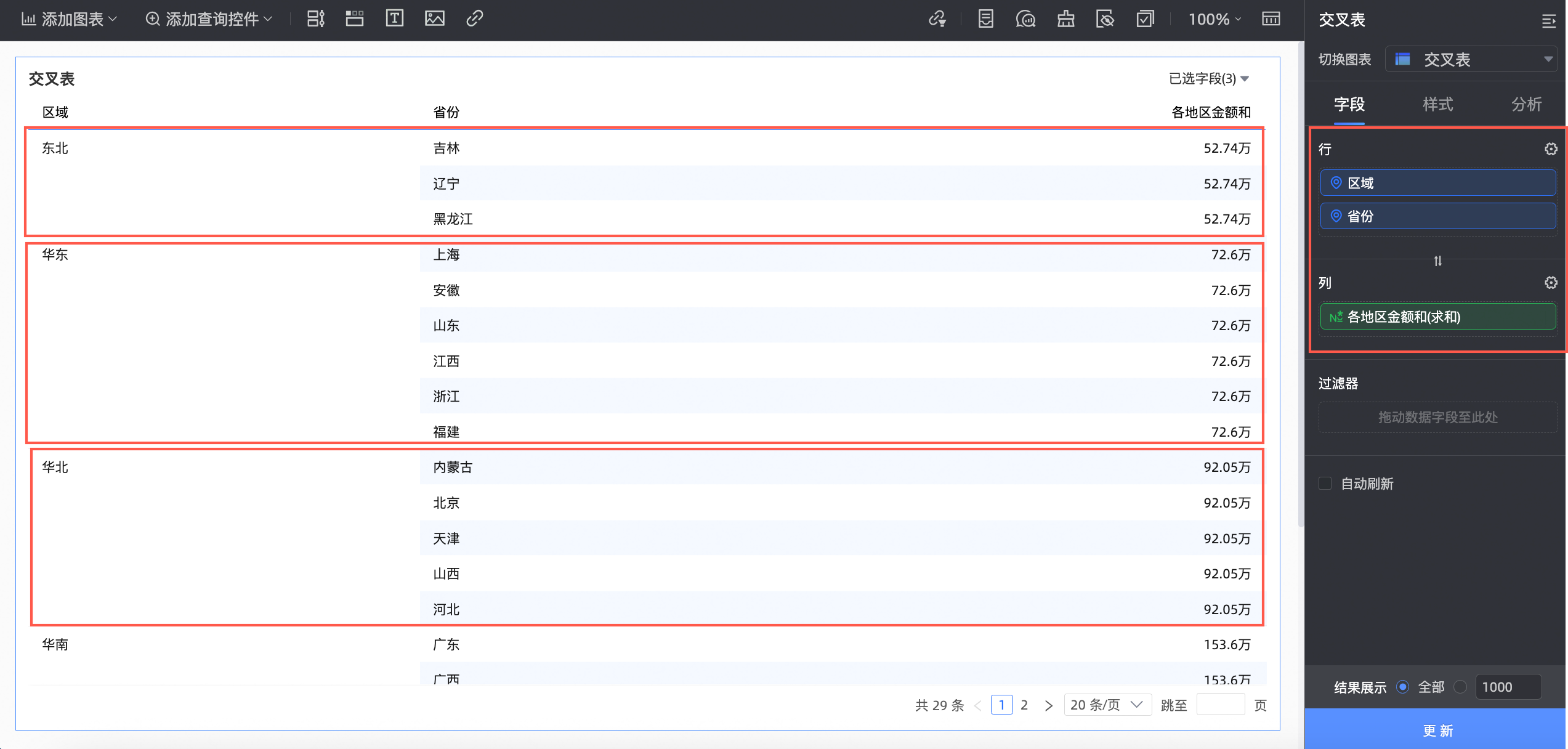
此时,我们可以同个区域的金额和是一样的,不受省份的影响。
应用场景二:客户订单频率
场景描述
某公司销售经理想了解订购过一个订单、两个订单、三个订单(依次类推)的客户数目,通过查看客户购买次数的数量和分布,来分析客户的复购黏性。该场景下,我们可以使用详细级别表达式(LOD函数)实现按照某一度量划分另一度量的目的。
本例中,我们使用lod_fixed函数,将订单数转变为按客户数划分的维度,求出客户订单频率。
操作步骤
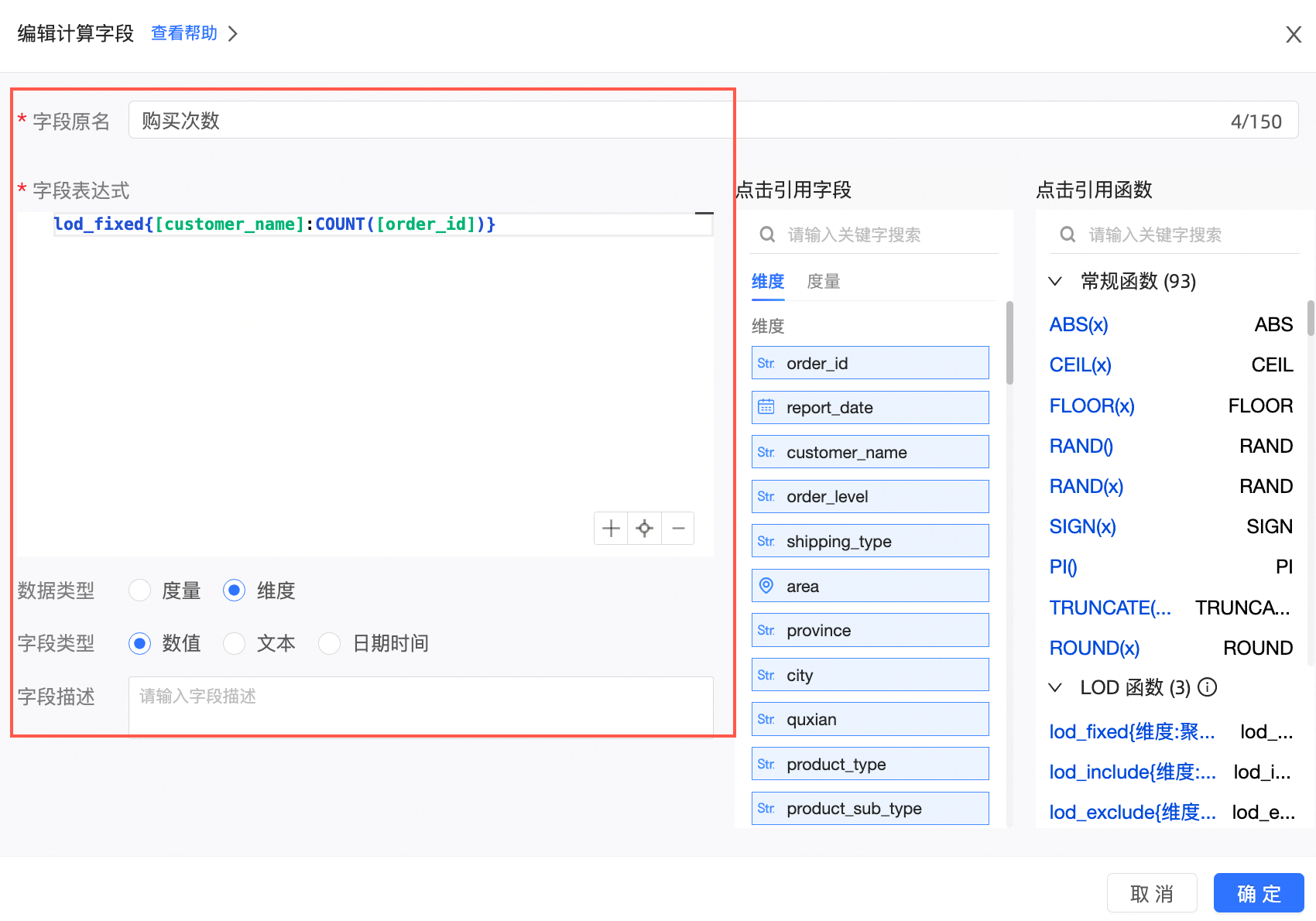
新建计算字段。
字段表达式:lod_fixed{[customer_name]:COUNT([order_id])}
含义:根据用户名称求出每个用户的购买的次数。
创建图表
本例中,我们创建一个柱图。
将上一步创建的购买次数字段拖入类别轴/维度轴区域,将customer_name字段拖入轴值/度量区域并设置去重计数,单击更新后系统自动更新图表。
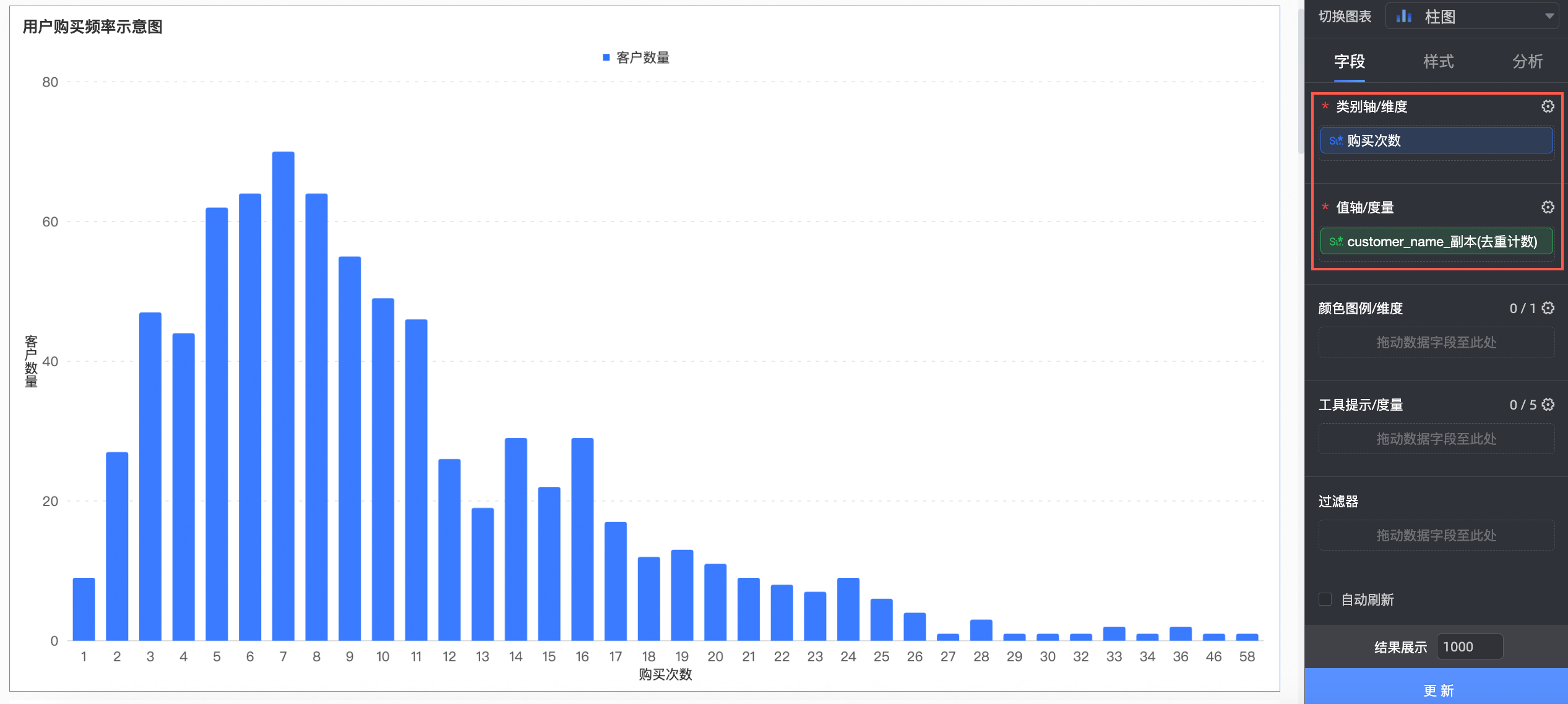
此时,我们可以看到购买7次的客户数量最多,最多的一个客户购买了58次。
应用场景三:各地区利润百分比排行榜
场景描述
某公司区域销售总监想知道每个地区对总利润的占比,并一目了然地看出哪些地区的贡献度最大。该场景下,我们可以使用高级计算 -> 占比来实现,也可以使用详细级别表达式(LOD函数)来更灵活的实现。
本例中,我们使用lod_fixed函数求出各地区利润百分比排行榜。
操作步骤
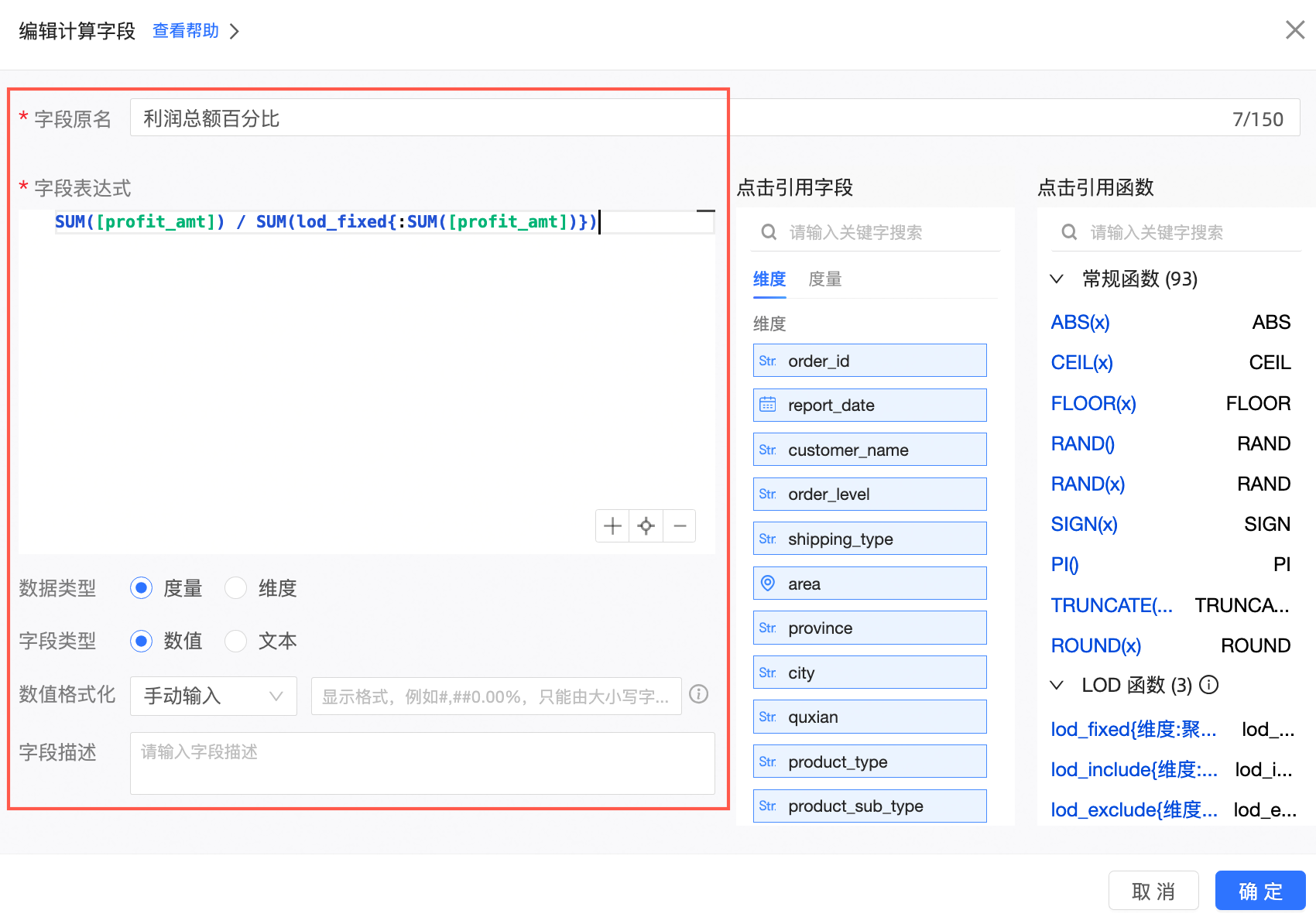
新建计算字段。
字段表达式:lod_fixed{:SUM([profit_amt])}
含义:在本例中,fixed的写法更特殊一些,该表达式并没有指定维度,因此它的含义是不根据任何粒度进行聚合,直接求出利润额的总和。
再用SUM([profit_amt])来除以之前的LOD函数,如表达式所示:SUM([profit_amt]) / SUM(lod_fixed{:SUM([profit_amt])}),得到的就是各个区域的利润占比。
创建图表。
本例中,我们创建一个排行榜。
将上一步创建的利润总额百分比字段拖入指标/度量区域,将area字段拖入类别/维度区域,单击更新,系统自动更新图表。
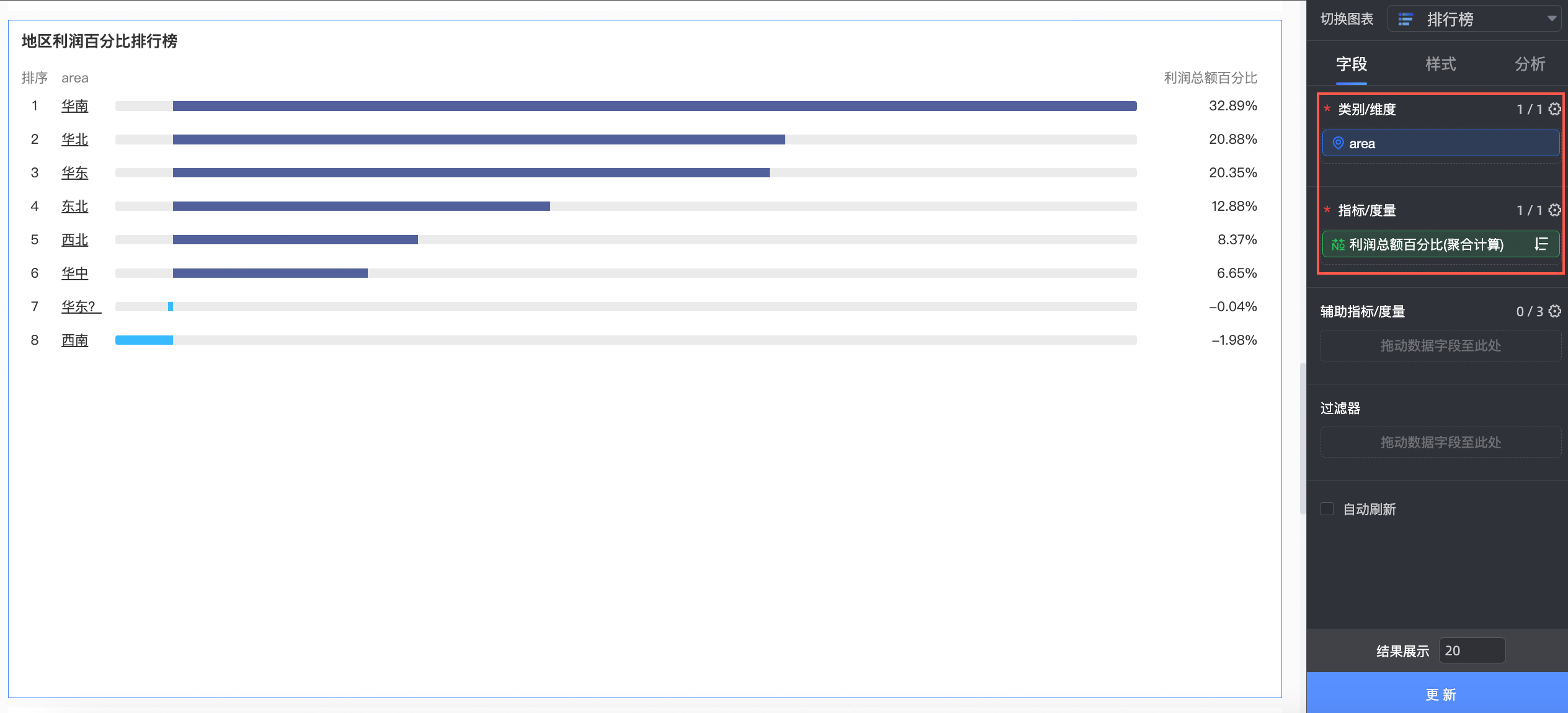
此时,我们可以看到,华南和华北的贡献度排名前二,而华东?和西南的贡献度最低,而且利润额甚至是负数,当然华东?这个数据看起来更像是脏数据。
应用场景四:年度新增用户统计
场景描述
在一个产品中,如何判断我们的产品是否在正向增长?除了日常使用的PV和UV之外,我们还可以统计用户的忠诚率,比如使用了很久的用户,依然在使用我们的产品并做出下单等贡献时,我们就可以认为我们的产品是有粘性的。为了实现这种效果,我们可以使用详细级别表达式(LOD函数)。
本例中,我们使用lod_fixed函数实现年度新增用户统计。
操作步骤
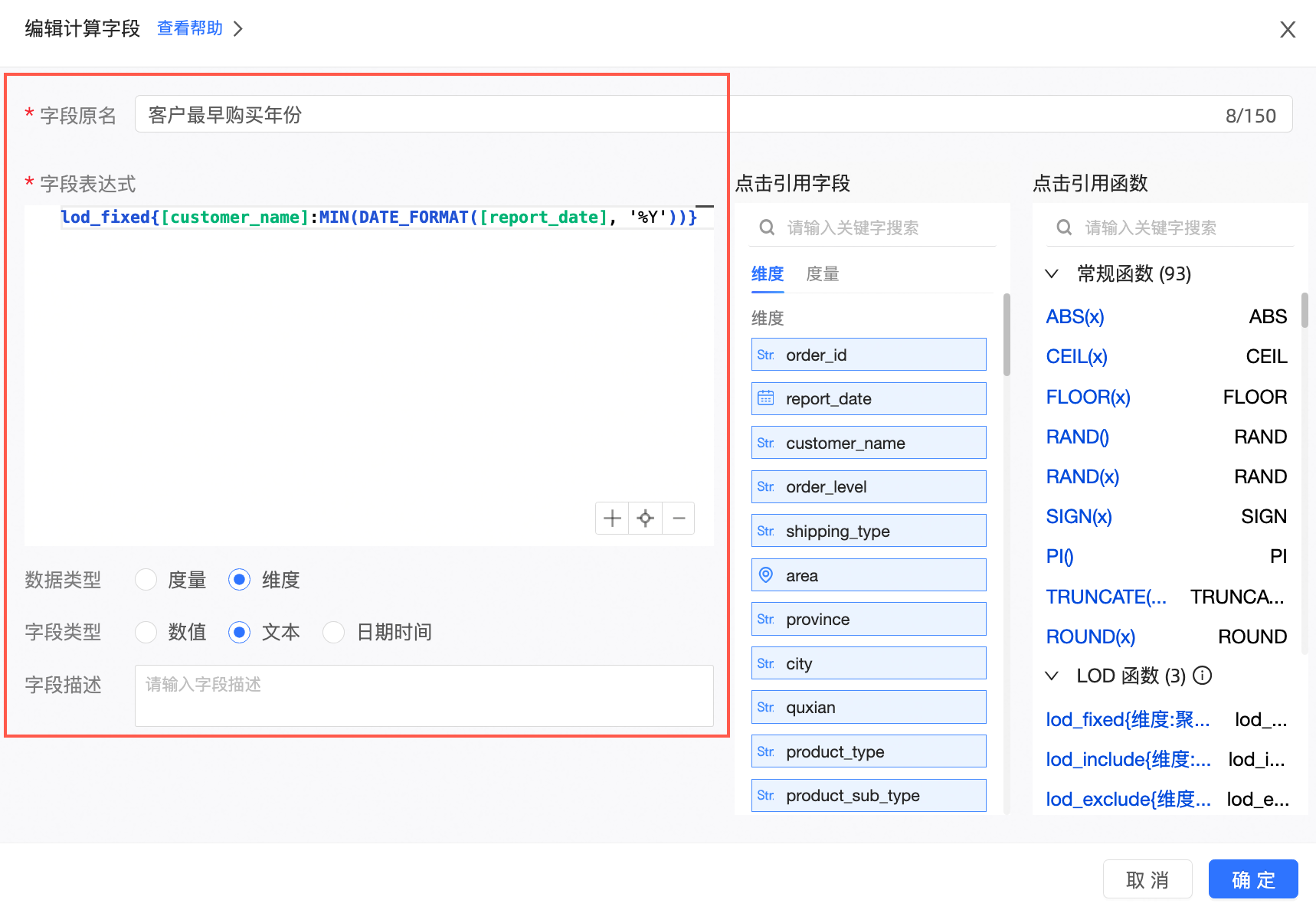
新建计算字段。
字段表达式:lod_fixed{[customer_name]:MIN(DATE_FORMAT([buy_date], '%Y'))}
含义:求出每个用户最早的下单时间,粒度为年,粒度可以随意调整,只要使用符合您的数据库的语法的日期函数就可以。
创建图表。
本例中,我们创建一个线图。
将上一步创建的客户最早购买年份字段拖入类别轴/维度区域,将销售额拖入轴值/度量区域,单击更新,系统自动更新图表。
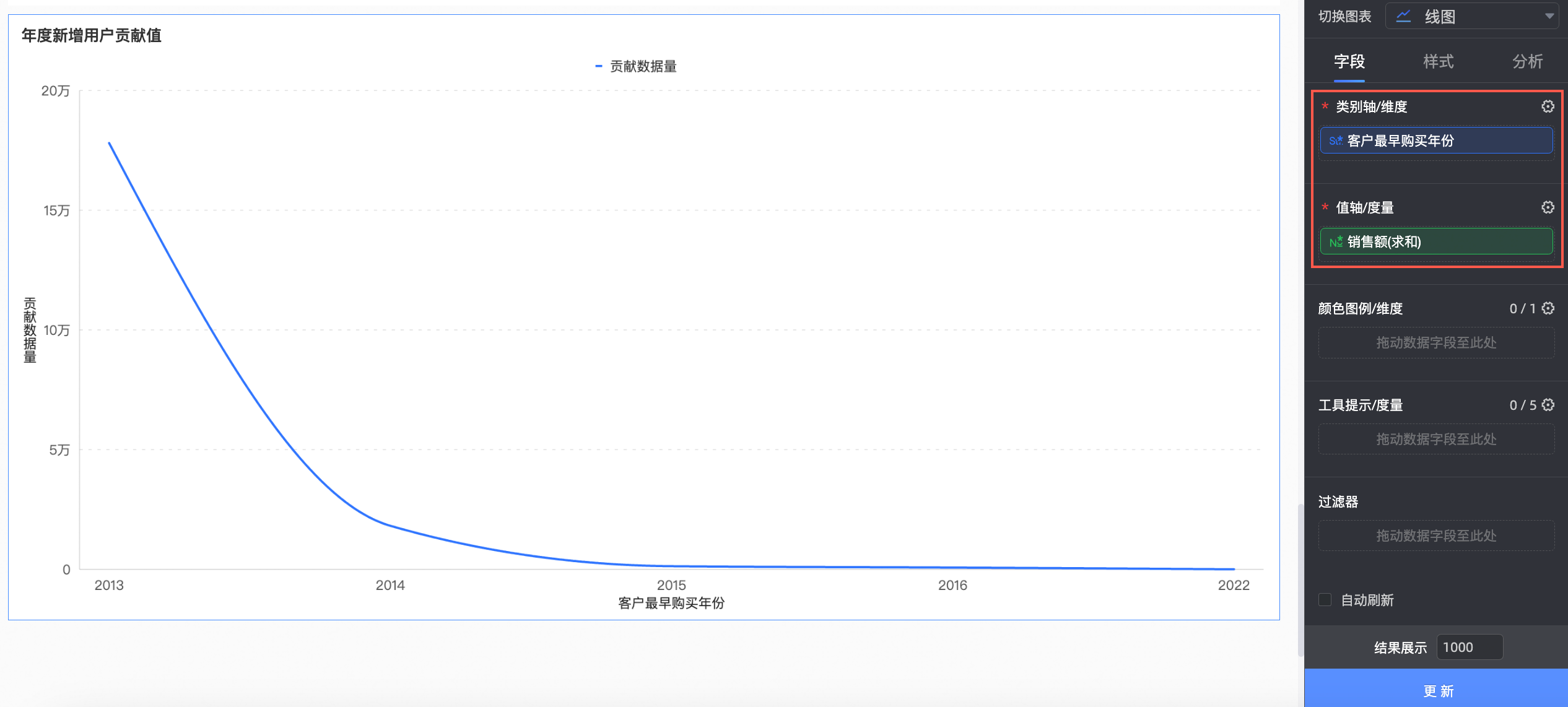
此时,我们可以看到,2013年开始使用的用户,在整个的贡献度当中依然是非常高的,看来我们的产品粘性还是很高的。
include函数应用
include详细级别表达式将指定的维度作为分组依据进行计算。include的作用是在已有的聚合粒度基础上,再深入一层进行分析。
应用场景一:计算平均客户销售额
场景描述
当您在分析各种产品的销售情况时,需要查看平均客户销售额,可以通过include先计算每个客户的总订单销售金额,再通过平均值的聚合方式计算展示。
操作步骤
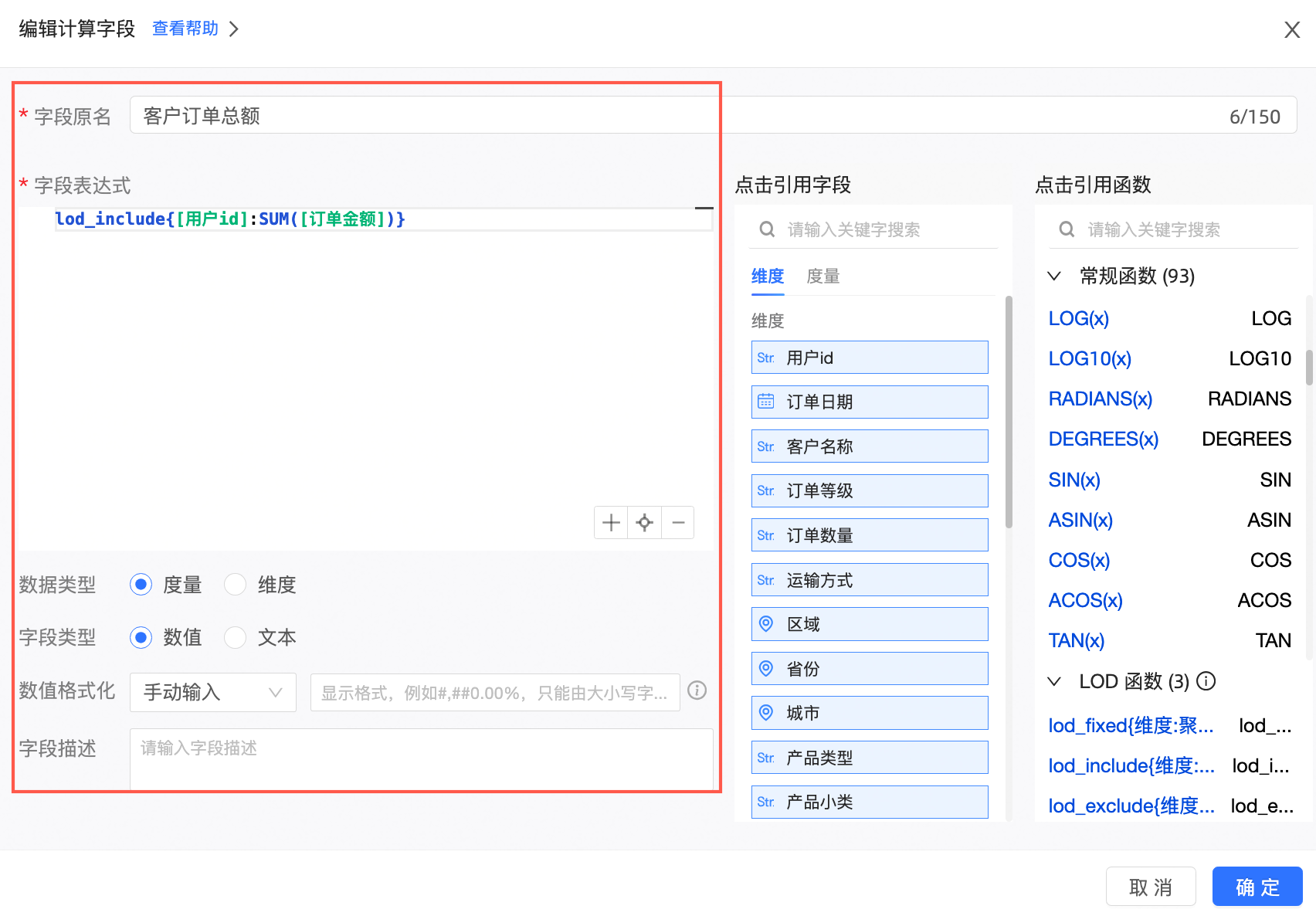
新建计算字段
字段表达式:lod_include{[用户id]:SUM([订单金额])}
含义:按照用户id计算每个客户的总订单金额。
创建图表
本例中,我们创建一个交叉表。
将订单金额、客户订单总额字段拖入列区域,将产品类型字段拖入行区域。并将客户订单总额的聚合方式设置为平均值,单击更新后系统自动更新图表。
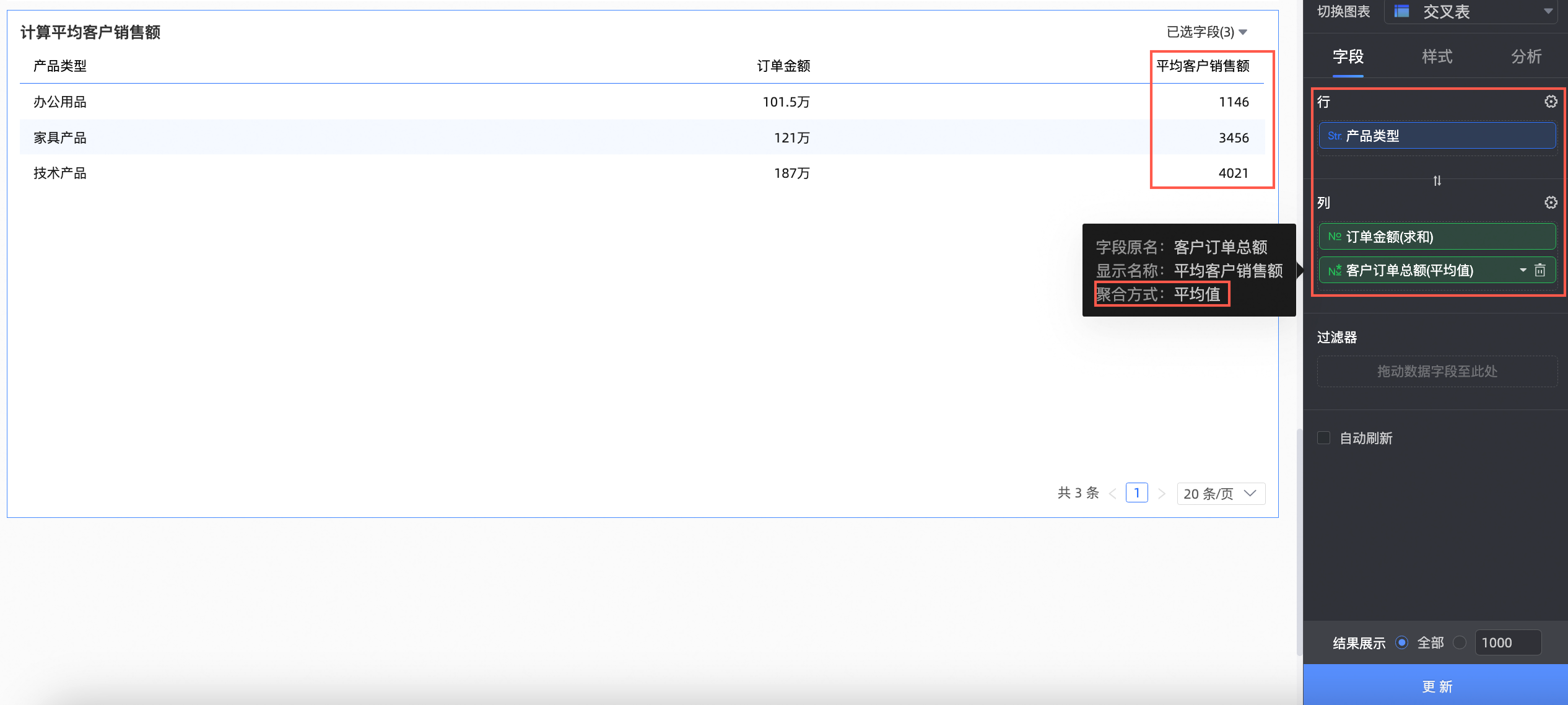
此时,我们可以看到不同产品类型对应的平均客户销售额。
应用场景二:各个销售代表的平均最大额交易数额
场景描述
某公司销售总监需要了解每个销售代表达成的最大额交易数额按地区计算的平均值,并且在地图上进行展示。该场景下,我们可以利用详细级别表达式(LOD表达式),使数据按照地区级别直观显示,我们也可以向下查看销售代表详细级别,直观地看到哪个战区的销售数据较好,哪些较差,从而对各地区的销售代表进行不同的目标规划。
本例中,我们使用lod_include函数求出各个销售代表的平均最大额交易数额。
操作步骤
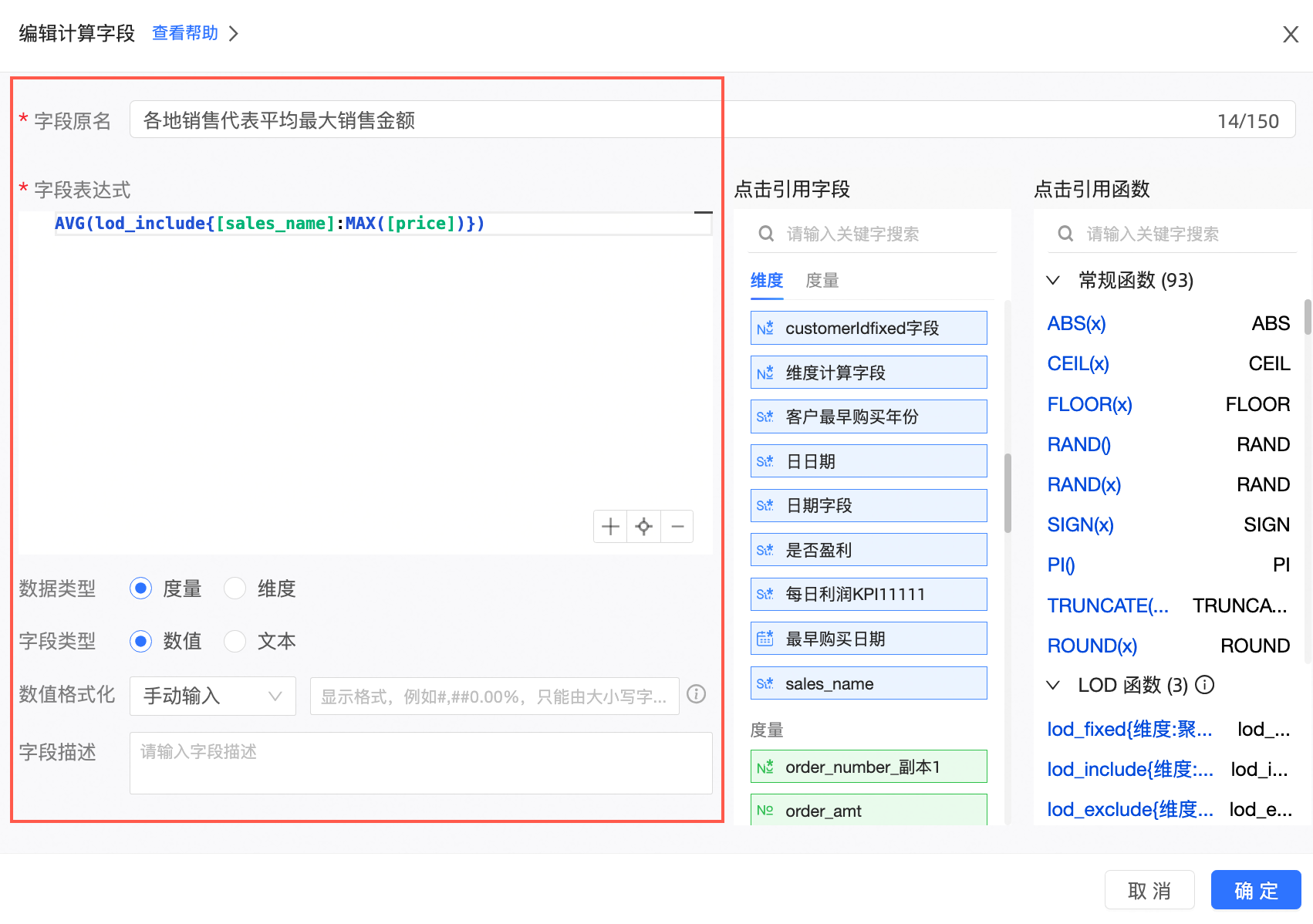
新建计算字段。
字段表达式:AVG(lod_include{[sales_name]:MAX([price])})
含义:在原有的基础上,额外增加销售代表名字为分析粒度,并求出销售额的最大值的平均值。
创建图表
本例中,我们创建一个色彩地图。
将上一步创建的各地销售代表平均最大销售金额字段拖入色彩饱和度/度量中,将area字段拖入地理区域轴/维度轴中。
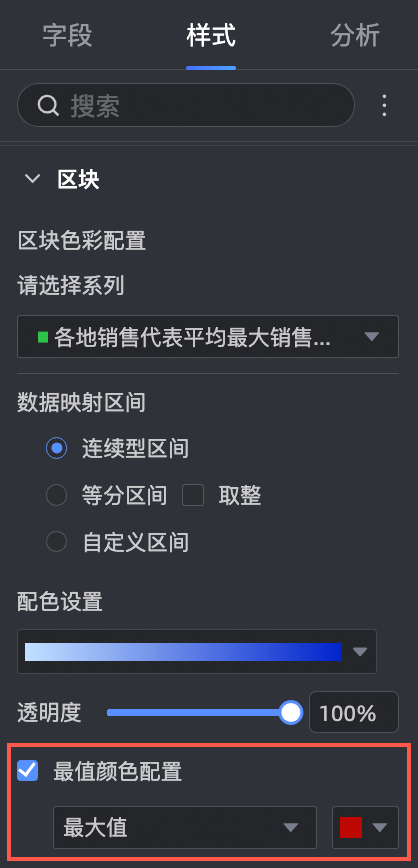
在样式->区块里,将该字段最大值的区域标红。
单击更新,系统自动更新图表。
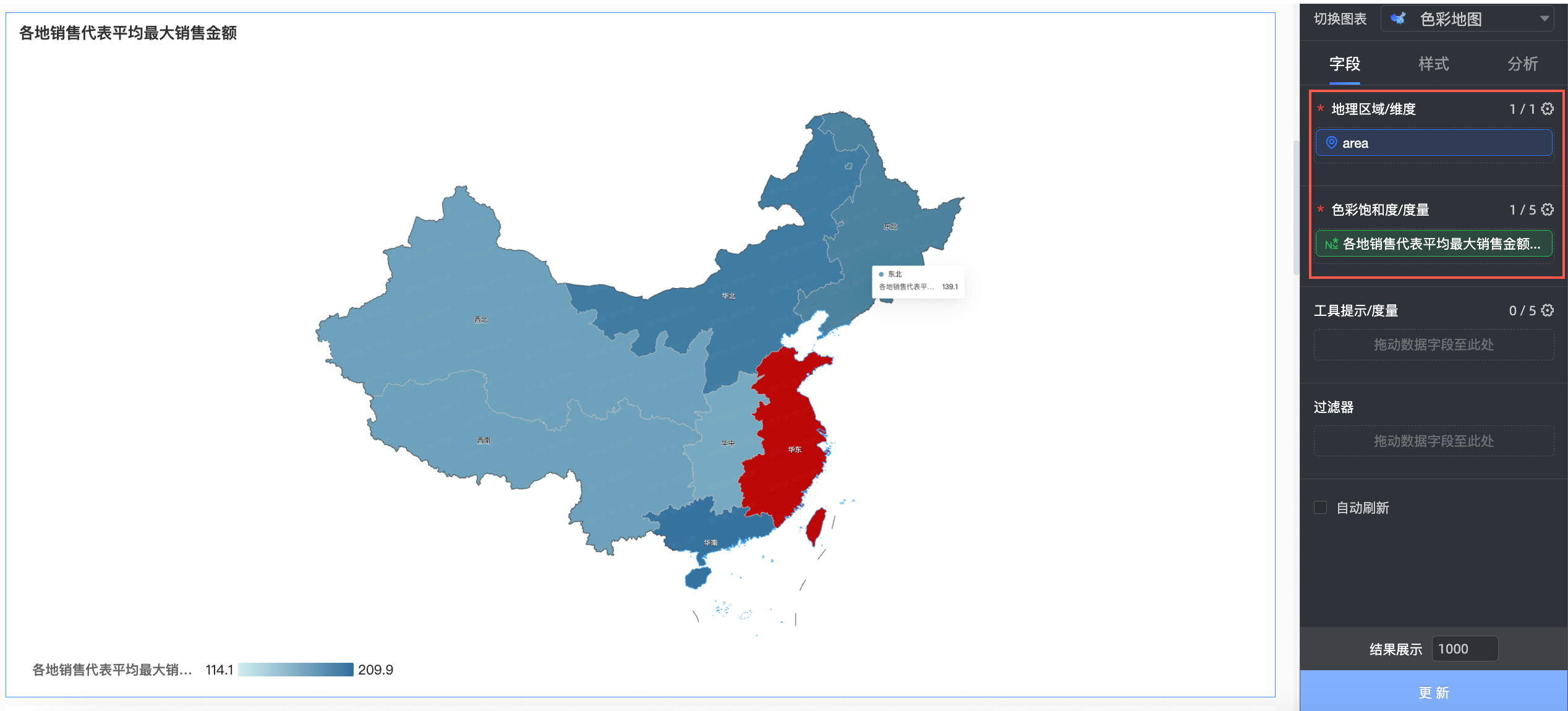
此时,我们可以看到,华东地区的销售最大额较大,西北/西南地区的则较小。
exclude函数应用
exclude详细级别表达式将去除表达式中指定的维度后进行计算。
应用场景一:计算区域下各省份销售额占比
场景描述
当您在分析区域下各省份的销售额数据情况时,同时还需要查看该区域的总销售数据、以及省份与其的销售额占比时,可以通过exclude函数先计算出除去当前省份后该地区的销售额,再通过聚合方式求和计算出该区域的总额。
操作步骤
新建计算字段
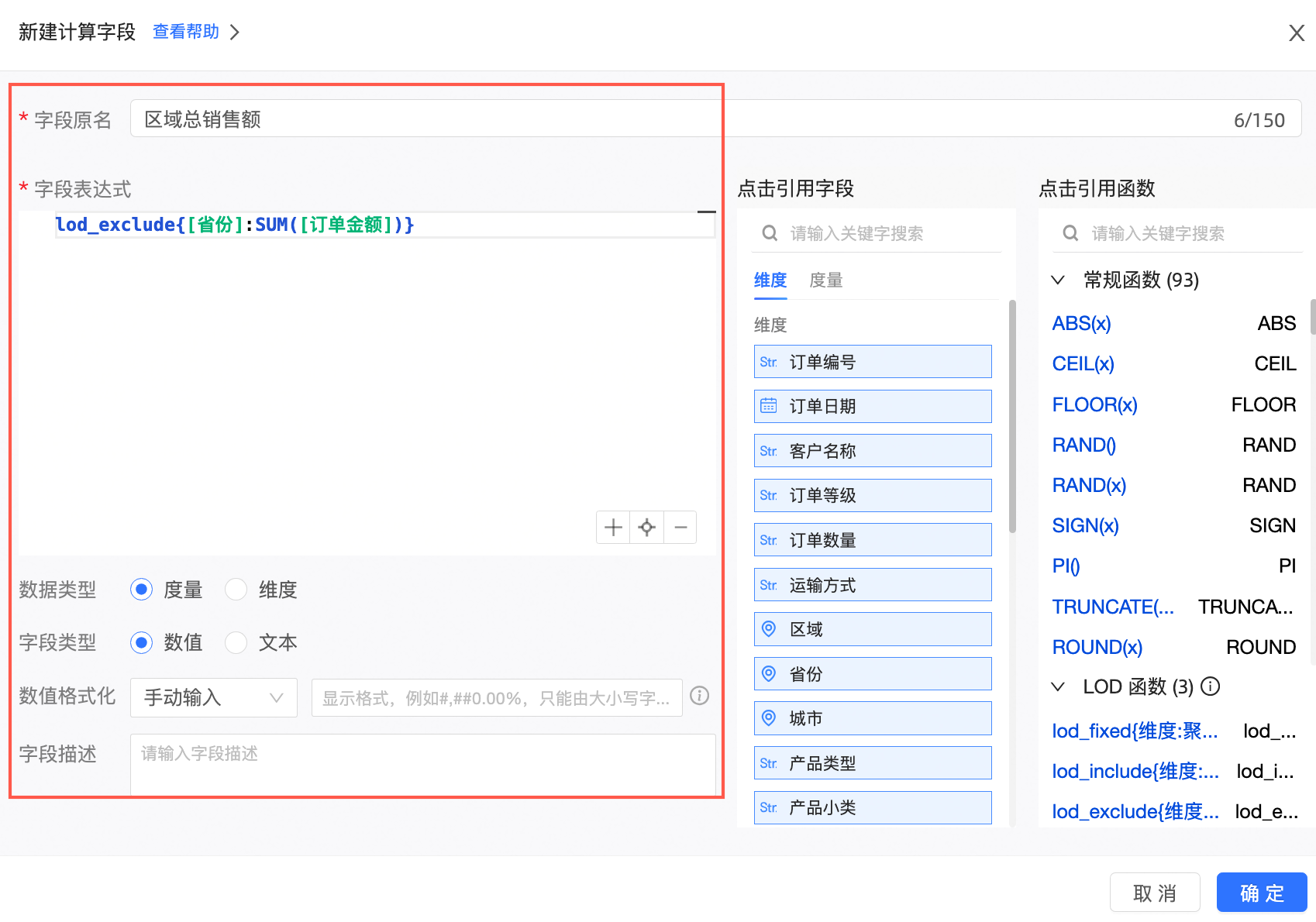
字段表达式:lod_exclude{[省份]:SUM([订单金额])}
含义:计算除去当前省份后该地区的销售额。
创建图表
本例中,我们创建一个交叉表。将订单金额、区域总销售额字段拖入列区域,将区域、省份字段拖入行区域,单击更新后系统自动更新图表。
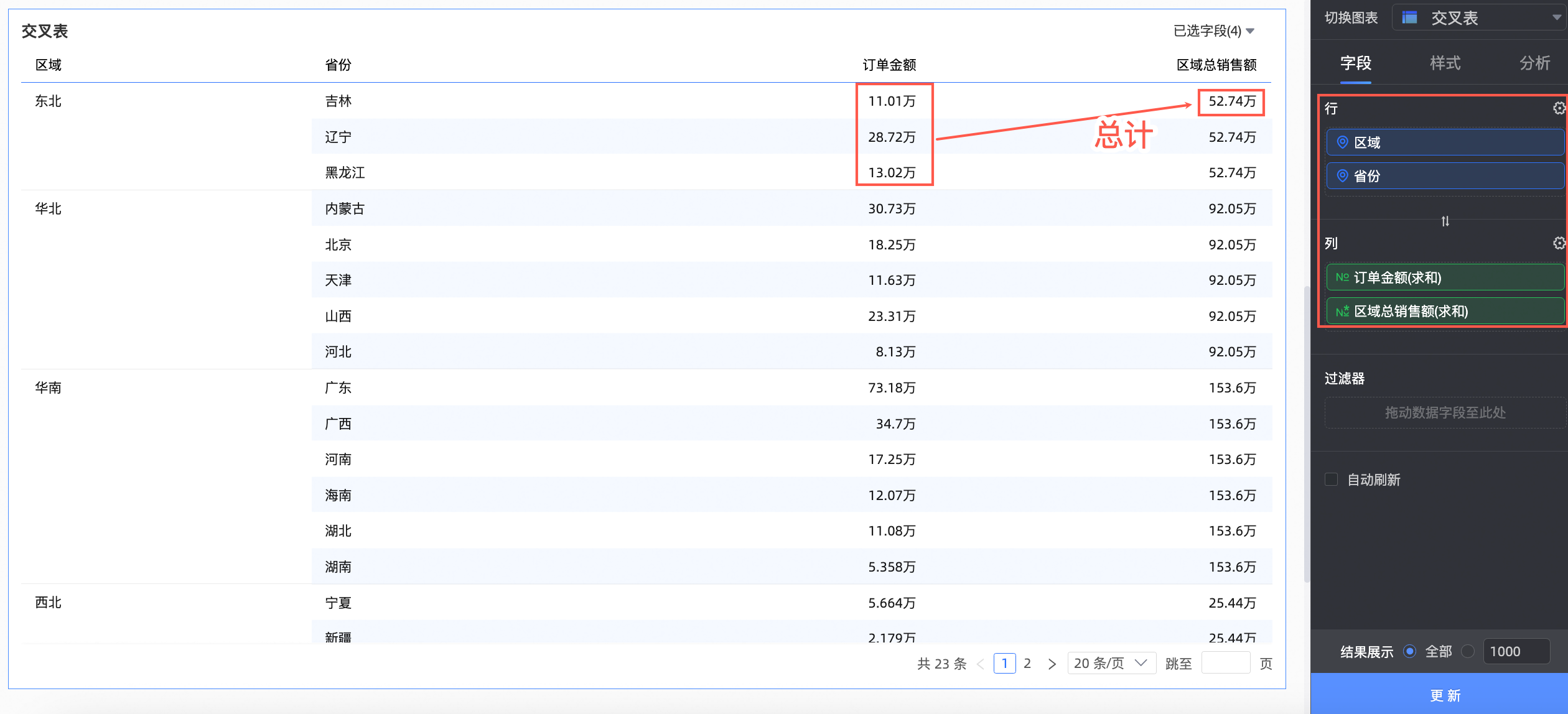
此时,我们既可以看到各省份的订单金额,也可以看到对应区域的总销售额。
应用场景二:各个销售区域和战区平均值之间的差额
场景描述
某销售公司目前根据全国的行政区块下辖了7个大战区,每个战区下面又根据省份设立了若干个销售区域,现在到了年终盘点的时候,我们需要快速知道各个省份的限售区域在今年的平均销售利润额和战区整体平均之间的差距,并看出哪些是优秀战区,哪些仍需要提升。对于这种场景,我们可以利用详细级别表达式(LOD表达式)和条件格式快速完成这样的一个报表。
本例中,我们使用lod_exclude函数求出各个销售区域和战区平均值之间的差额。
操作步骤
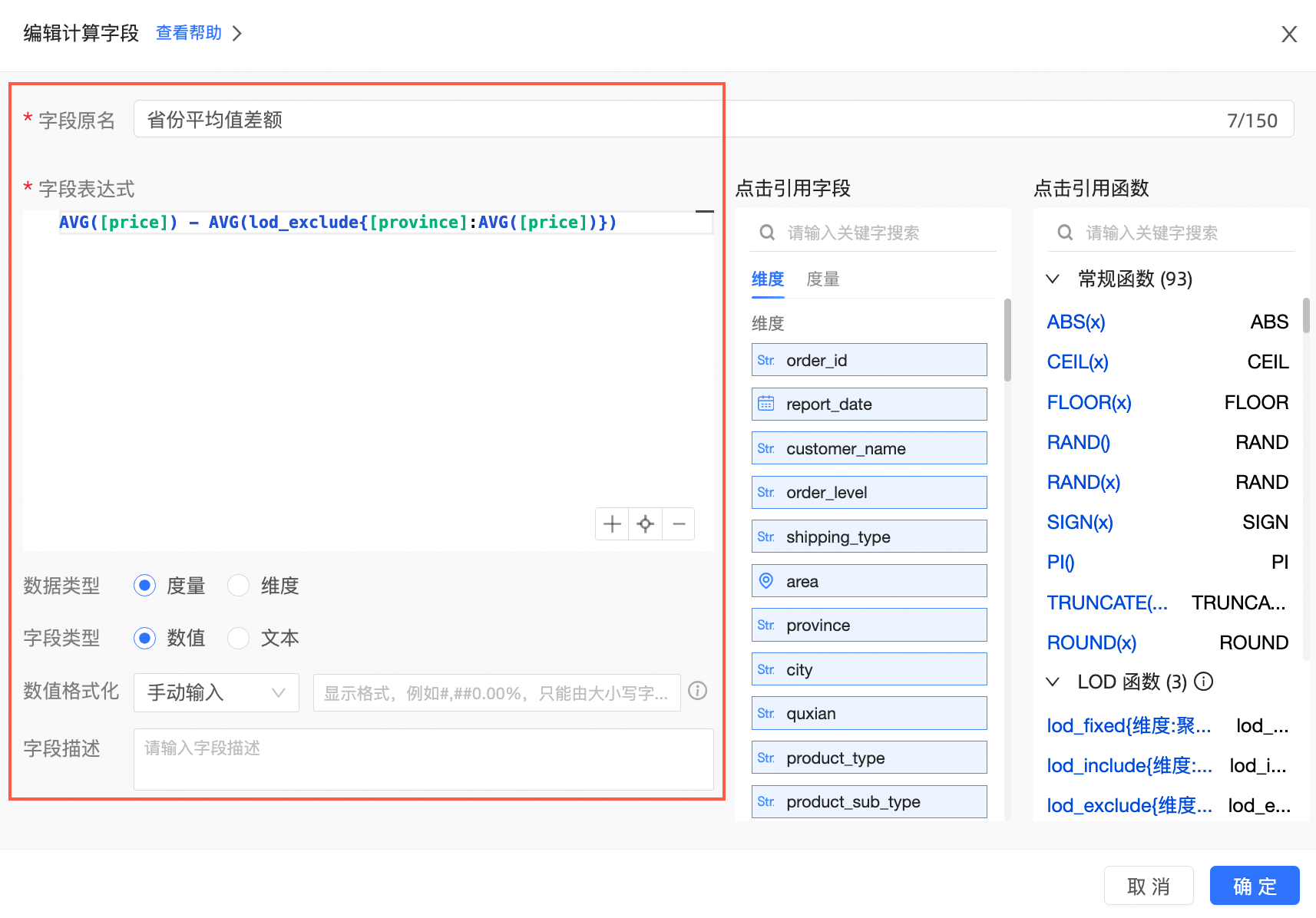
新建计算字段。
字段表达式:AVG(lod_exclude{[province]:AVG([price])})
含义:在原有的基础上,去掉销售战区作为聚合粒度,并求出其他聚合粒度的销售额的平均值。这个表达式中,我们将会求出各战区(华东等)的销售额的平均值。
再用AVG([price])来减去之前的LOD函数,如表达式所示:AVG([price]) - AVG(lod_exclude{[province]:AVG([price])}),得到的就是各个销售区域和战区平均值之间的差额。
创建图表
本例中,我们创建一个交叉表。
将上一步创建省份平均差额字段拖入列,将area和province字段拖入行。
在样式->条件格式里,对该字段设置条件格式:大于0的为红色,小于0的为绿色。
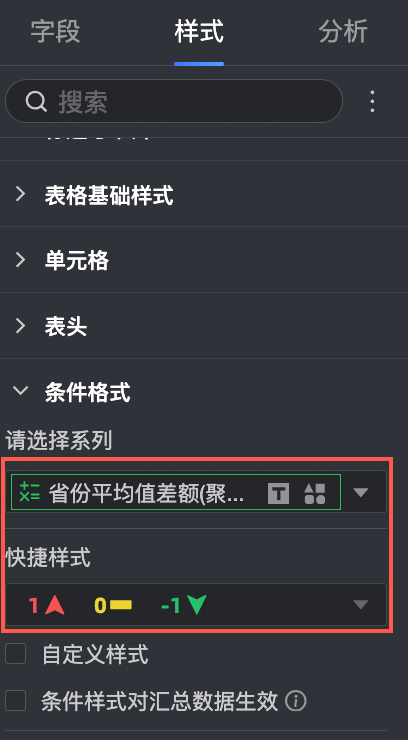
单击更新,系统自定更新图表。
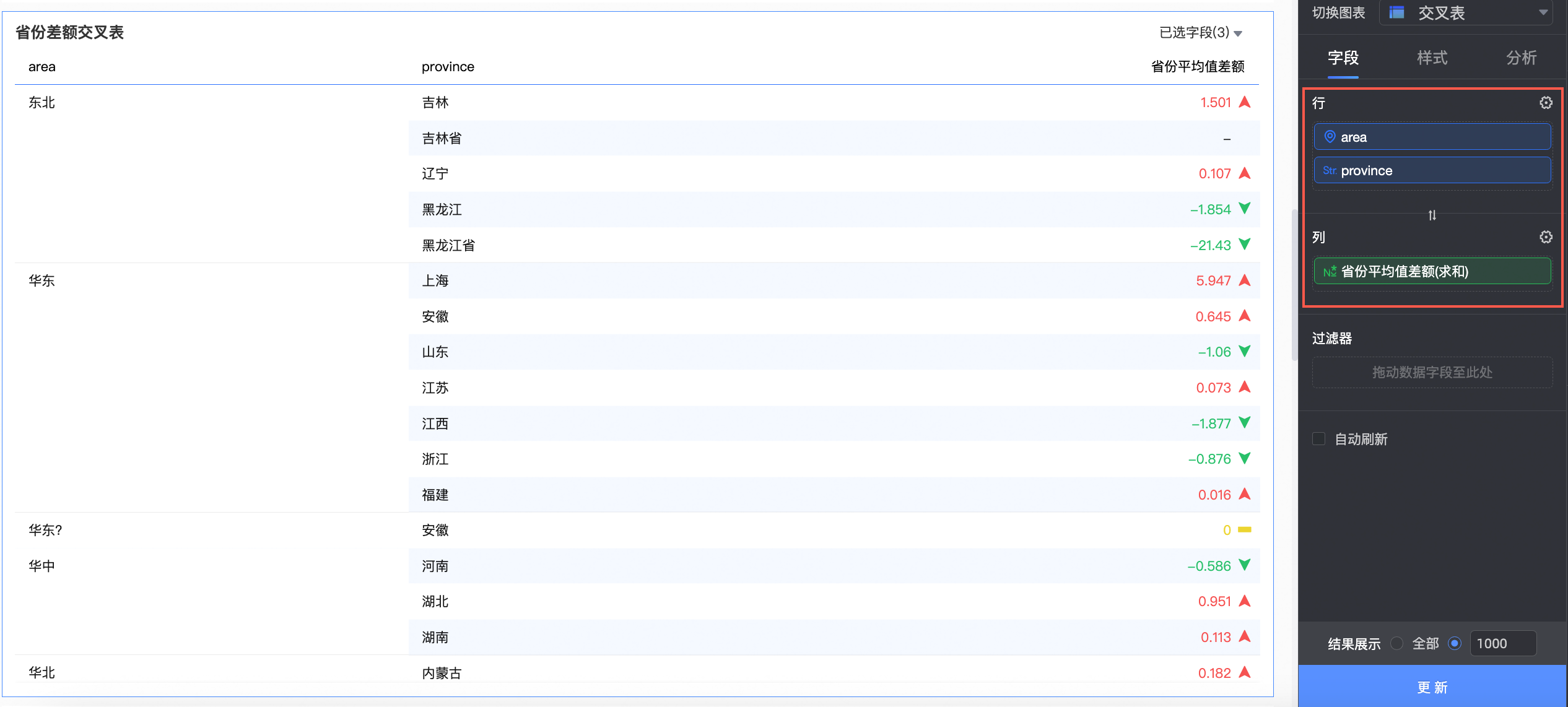
此时,我们可以快速看到,在华东战区,上海、安徽、江苏和福建的销售额是正向的,其中上海的表现最出色,而山东、江西和浙江的营业额未达到平均,还需努力。
- 本页导读 (0)