如果您想要在生产环境中部署Huggingface社区模型,并实现实时推理,您可以使用EAS模型在线服务。EAS提供了预置镜像,可快速部署Huggingface社区模型,并具备模型分发和镜像拉起的加速机制。您只需配置几个参数,即可轻松将Huggingface社区模型部署到EAS上。本文为您介绍如何部署和调用Huggingface社区模型。
背景信息
HuggingFace提供了多个模型选项,其中可在EAS上部署的包括普通Pipeline模型和大型语言模型,这两类模型的部署和调用方式稍有不同。您可以参考以下内容了解如何部署和调用这两种类型的模型:
普通模型
使用普通模型的通用操作流程如下:
步骤一:选择模型
在官方库tasks中选择要部署的模型,本文以文本分类模型为例,进入distilbert-base-uncased-finetuned-sst-2-english模型页面,分别获取下图中的MODEL_ID(模型ID)、TASK(模型对应的TASK)、REVISION(模型版本)的值并保存到本地。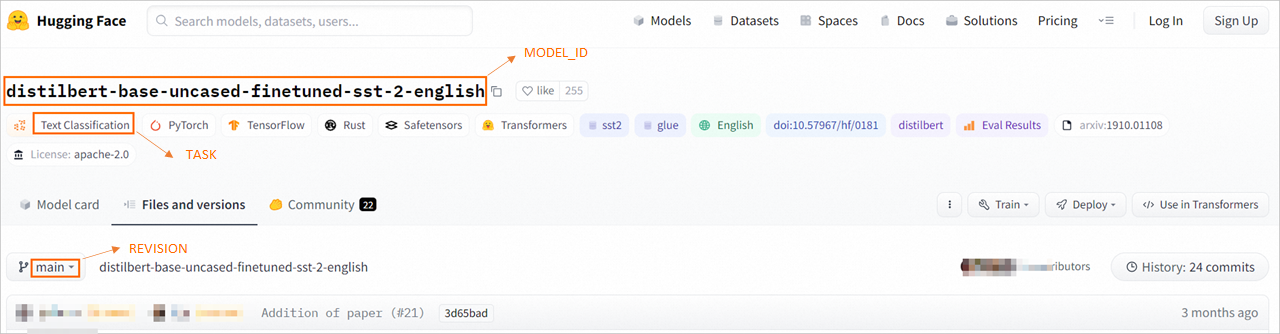
您可以根据下表中的对应关系找到部署EAS服务时所需的TASK:
HuggingFace页面展示的TASK | 部署EAS服务时填写的TASK |
Audio Classification | audio-classification |
Automatic Speech Recognition(ASR) | automatic-speech-recognition |
Feature Extraction | feature-extraction |
Fill Mask | fill-mask |
Image Classification | image-classification |
Question Answering | question-answering |
Summarization | summarization |
Text Classification | text-classification |
Sentiment Analysis | sentiment-analysis |
Text Generation | text-generation |
Translation | translation |
Translation (xx-to-yy) | translation_xx_to_yy |
Text-to-Text Generation | text2text-generation |
Zero-Shot Classification | zero-shot-classification |
Document Question Answering | document-question-answering |
Visual Question Answering | visual-question-answering |
Image-to-Text | image-to-text |
步骤二:部署模型
在EAS模型在线服务页面,部署HuggingFace模型。
进入部署服务页面,配置以下关键参数,其他参数配置详情,请参见服务部署:控制台。
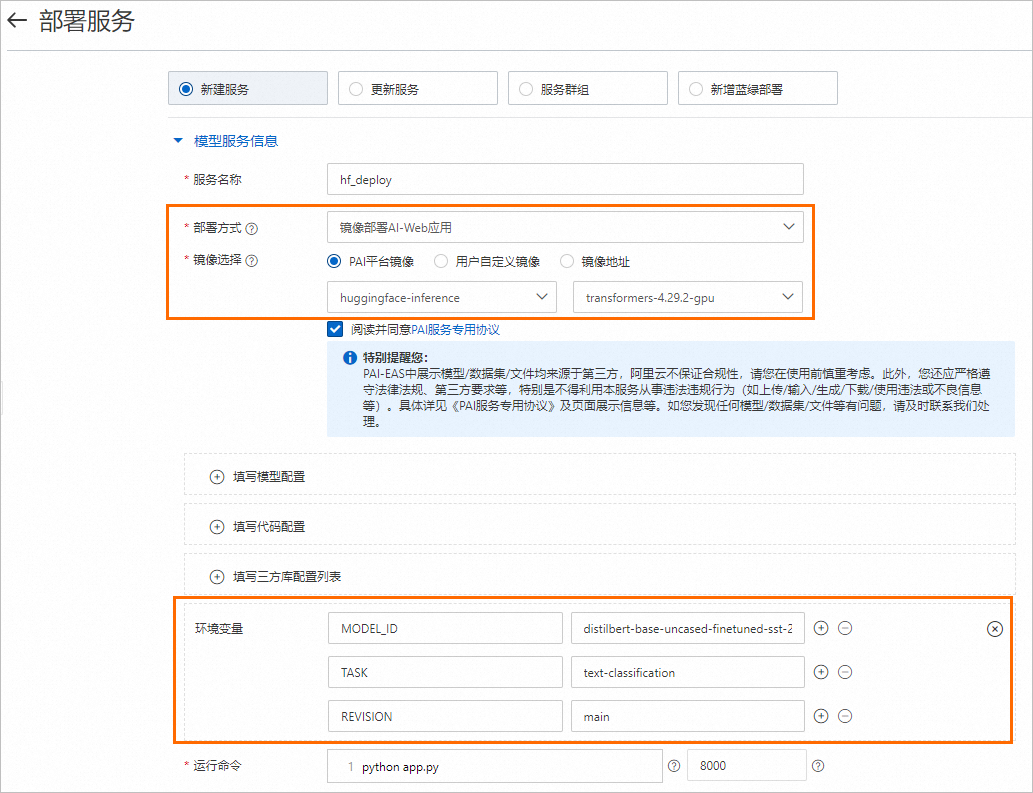
参数
描述
服务名称
参照界面提示自定义配置服务名称。
部署方式
选择镜像部署AI-Web应用。
镜像选择
在PAI平台镜像列表中选择huggingface-inference;并根据实际场景选择对应的镜像版本。
三方库配置
(可选)单击填写三方库配置列表,配置三方库。
PAI镜像中预装了基础的依赖库和各领域常用的依赖包。对于有特殊依赖的模型,可根据提示配置依赖库。

环境变量
配置以下参数为步骤一中查询的结果:
MODEL_ID:distilbert-base-uncased-finetuned-sst-2-english。
TASK:text-classification。
REVISION:main。
运行命令
配置镜像版本后,系统会自动配置运行命令,您无需修改配置。
单击部署。当服务状态变为运行中时,表明服务已部署成功。
步骤三:调用服务
支持以下几种调用方式:
通过控制台调用服务
在PAI-EAS模型在线服务页面,单击服务方式列下的查看Web应用,在WebUI页面验证模型推理效果。

单击目标服务操作列下的在线调试,在Body页签输入请求数据,例如:
{"data": ["hello"]},单击发送请求。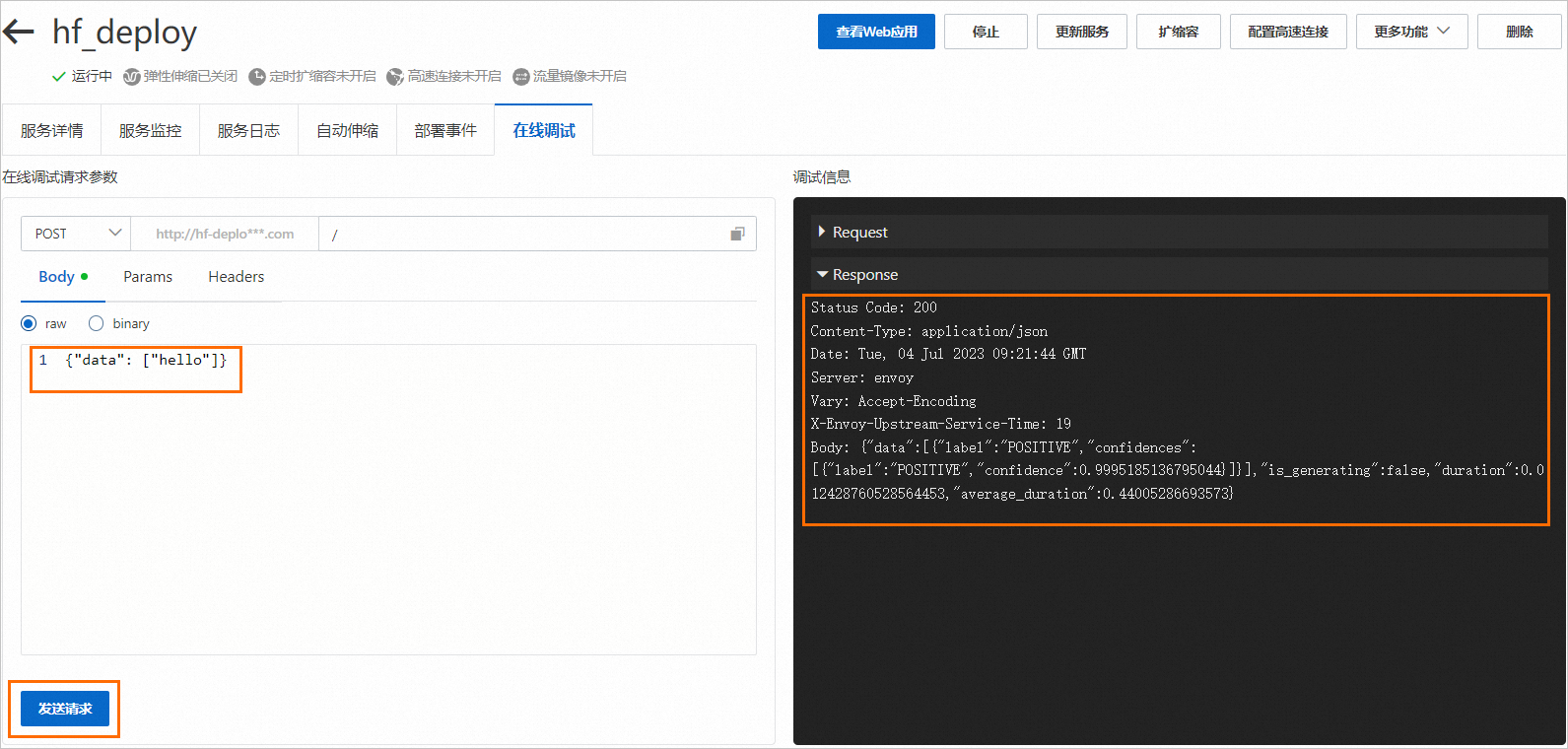 说明
说明文本分类模型输入的数据格式(
{"data": ["XXX"]})是Gradio框架的/api/predict定义的,如果您使用其他类型的模型,例如图片分类或语音数据处理等,可以参考/api/predict的定义来构造请求数据。
通过API调用服务
单击服务名称进入服务详情页面,在该页面单击查看调用信息。
在调用信息对话框公网地址调用页签,查看访问地址和Token,并保存到本地。
通过如下代码使用API调用服务。
import requests resp = requests.post(url="<service_url>", headers={"Authorization": "<token>"}, json={"data": ["hello"]}) print(resp.content) # resp: {"data":[{"label":"POSITIVE","confidences":[{"label":"POSITIVE","confidence":0.9995185136795044}]}],"is_generating":false,"duration":0.280987024307251,"average_duration":0.280987024307251}其中:<service_url>和<token>均需要替换为步骤b中获取的访问地址和Token。
大语言对话模型
目前支持一键部署的大语言对话模型列表,请参见附录:目前支持一键部署的大语言对话模型列表。使用大语言对话模型的通用流程如下:
步骤一:部署模型
进入部署服务页面,配置以下关键参数,其他参数配置详情,请参见服务部署:控制台。
参数
描述
服务名称
参照界面提示自定义配置服务名称。
部署方式
选择镜像部署AI-Web应用。
镜像选择
在PAI平台镜像列表中选择huggingface-inference,镜像版本选择transformers-4.33。
环境变量
MODEL_ID配置详情请参见附录:目前支持一键部署的大语言对话模型列表;TASK均配置为chat。您需要参考步骤一:选择模型来查询REVISION的配置。以qwen系列模型为例:
MODEL_ID:Qwen/Qwen-7B-Chat。
TASK:chat。
REVISION:main。
运行命令
配置镜像版本后,系统会自动配置运行命令
python webui/app.py,您无需修改配置。资源配置选择
本方案选择ml.gu7i.c16m60.1-gu30。
由于大语言模型的体积通常较大,并且对于GPU的要求较高,建议根据实际模型需求选择合适的GPU资源。
针对7B模型,建议选择GU30系列机型。对于更大的模型,可能需要考虑双卡机型或拥有更大显存的机型,请按实际需求选择。
单击部署。当服务状态变为运行中时,表明服务已部署成功。
步骤二:调用服务
大语言对话模型支持WebUI和API接口两种调用方式。
启动WebUI调用模型服务
服务部署成功后,单击服务方式列下的查看Web应用,即可打开一个类似下图页面的对话窗口,在该页面可以直接开始对话。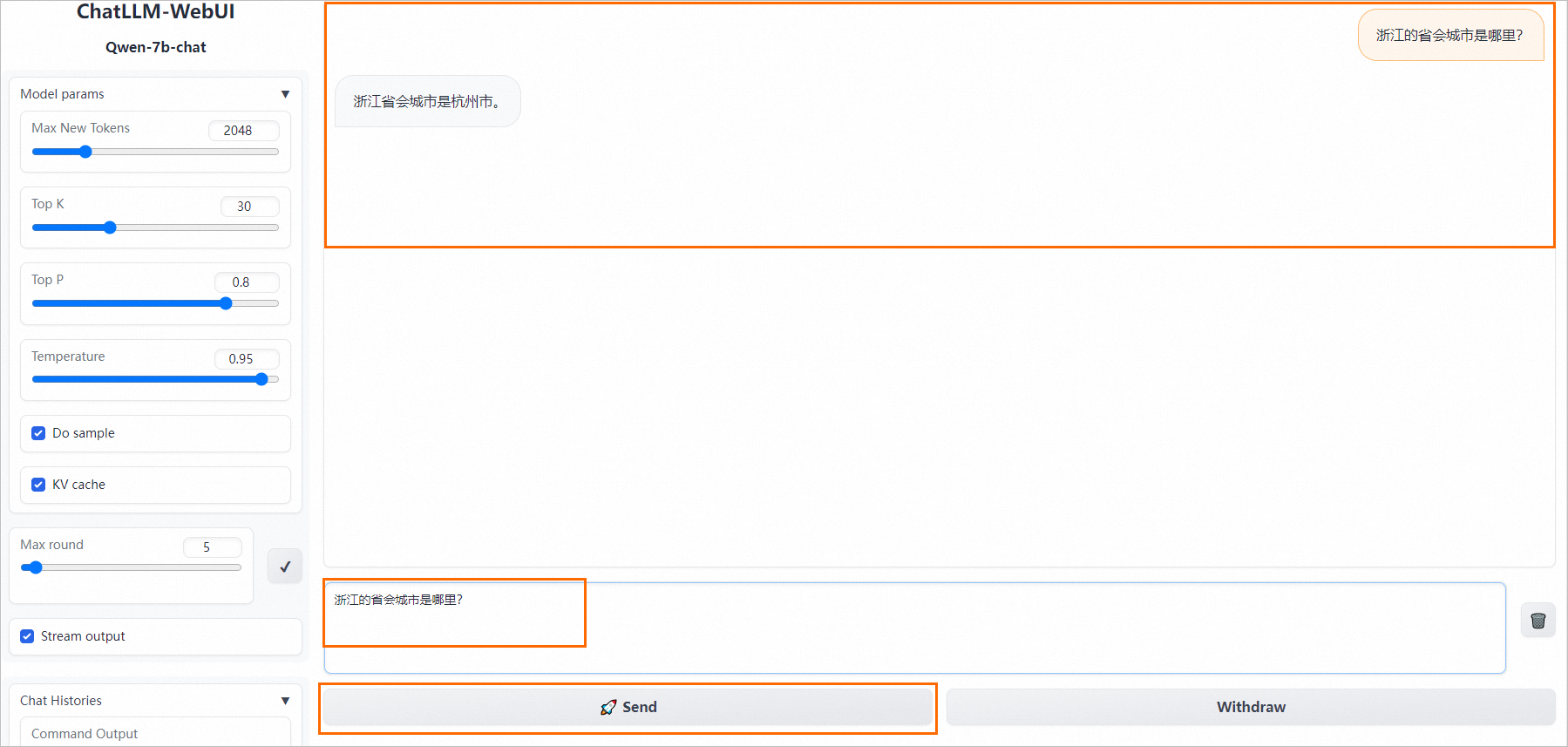
通过API接口调用模型服务
API接口的具体调用方式,请参见如何使用ChatGLM API进行模型推理?。
附录:目前支持一键部署的大语言对话模型列表
语言 | 类型 | MODEL_TYPE | MODEL_ID |
中文模型 | Qwen系列 | qwen |
|
ChatGLM系列 | glm |
| |
Baichuan系列 | baichuan |
| |
其他类型 | 无 |
| |
| |||
英文模型 | Llama系列 | llama |
|
相关文档
此外,EAS还预置了TritonServer、TensorFlow Serving、Modelscope镜像,您可以通过EAS一键部署相应的模型服务,并进行推理验证。具体操作,请参见:
- 本页导读 (1)