本文为您介绍如果在语音识别过程中出现问题,应该如何排查及常见问题的解决方案。
操作步骤
使用Cooledit或者Adobe Audition软件查看语音格式,播放试听并查看分轨情况、波形、能量和频谱图。
ASR识别标准格式:8KHz或16KHz采样率、16bit采样位数、单声道的语音数据(录音文件识别服务可支持双声道语音数据识别)。
检查管控台项目中使用的模型是否支持音频采样率和场景。
播放声音进行试听,重点关注如下两点:
检查是否存在噪音,比如人噪(人发出的声音或者远场非主说话人的声音)或非人噪(如敲桌子、开门、汽车鸣笛)。
检查发音清晰度和辨识度,比如是否存在吞音、语速过快或者重口音、方言等情形。
查看波形、能量和频谱图,重点关注波形幅度和频段信息。
检查波形幅度是否过小或过大。此处以8KHz采样率语音为例进行说明。
正常语音波形。
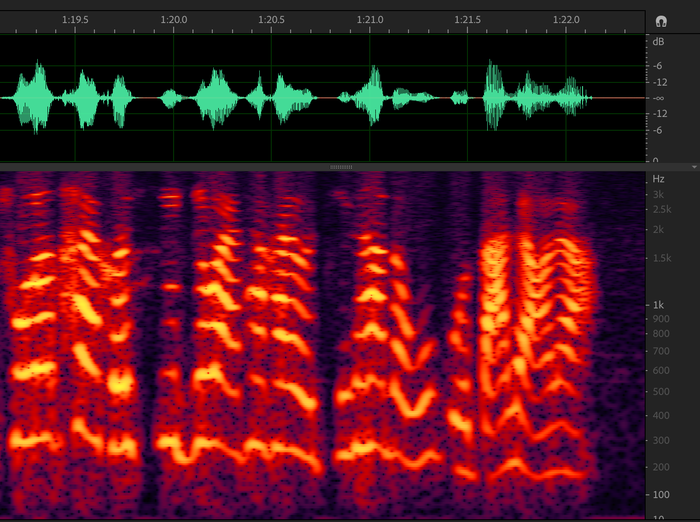
波形幅度过小,话音能量过低。
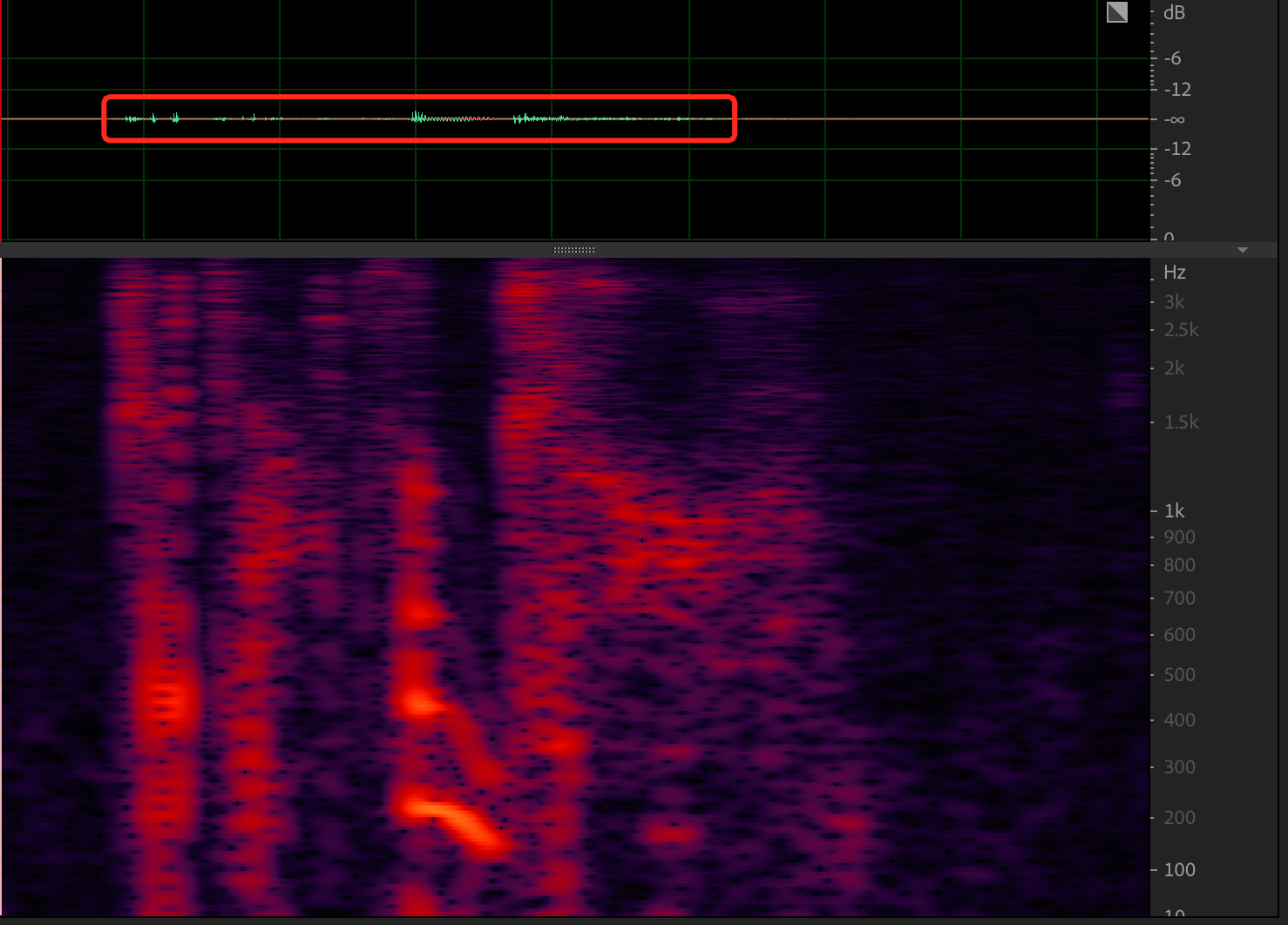
波形幅度过大,有可能造成超出系统范围被截断的情况。
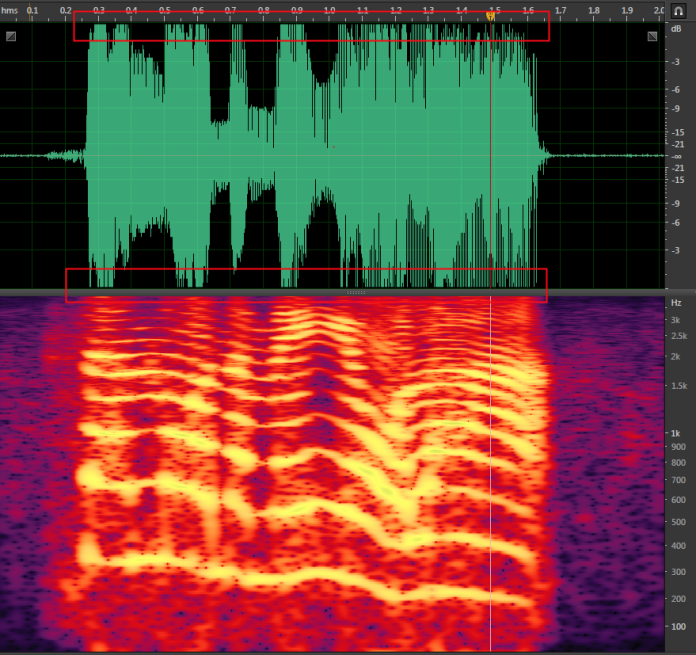
检查频段信息是否符合要求。此处以8KHz采样率语音为例进行说明。
实际频段信息只有3*2=6K(最高频段信息2倍即为实际采样率)。
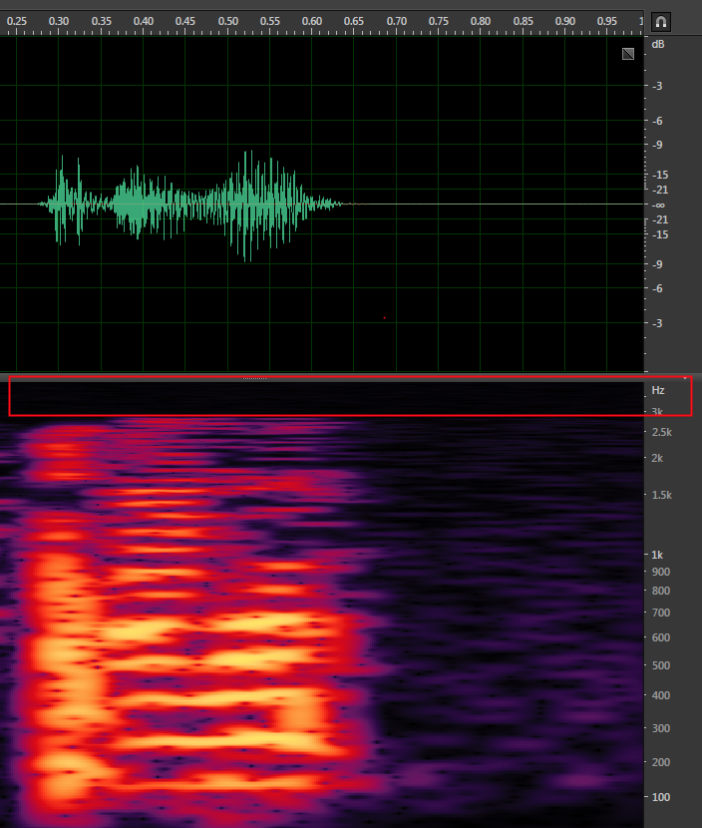
说明对于录音文件识别服务,需查看是合轨还是分轨数据。以客服场景为例,合轨指客户和客服的声音存在一个声道,不免会有语音重叠的时刻;分轨指客户和客服的声音分开存储在两个声道。
检查是否使用了热词或者自学习模型。
解决方案
语音识别不可能达到100%识别率。
在项目中选择支持的音频采样率和场景的模型。
出现“吞音、辨识度不高、听不懂”等情况无法解决时:
如果存在方言和重口音,可能由于ASR的训练数据覆盖不全造成识别错误,请联系阿里智能语音交互工程师进一步评估。
如果有大量的重口音(非方言)识别需求,请联系阿里智能语音交互工程师进一步评估。
如果人噪被误识别,此问题很难解决。
噪声模型优先考虑只要是人发出的声音就会被送入ASR识别。
如果非人噪被误识别,您可以多收集一些噪声数据,提供给阿里云进行噪声模型优化。
如果波形幅度不大,能量过低,造成识别数据丢失,可能是由于音量太小被噪声模型当成噪声处理。
建议调整收音设备,或减小说话人与收音设备的距离。
如果波形幅度过大能量过高造成识别错误,可能是由于音量太大被截幅而语音失真,造成识别错误。
建议调整收音设备,或者说话人离收音设备远些。
如果频段信息不完整,可能会造成识别不准确,ASR模型的标准训练数据要求为频段完整的8K/16K采样率数据。
建议确保频段信息完整的基础上,对识别不准确的地方使用自学习模型进行优化。
如果使用了热词,业务专属热词的权重不宜过高,权重太高可能会引起语句被截断,导致后续语音无法进行识别。
针对一般的识别错误,可以使用语音模型优化,将识别不佳的句子(非单个词)进行多复制几遍的操作。
对于使用录音文件识别服务,如果是合轨数据造成识别不准确。
建议采用分轨进行存储。
- 本页导读 (1)