Spark是一个通用的大数据分析引擎,具有高性能、易用和普遍性等特点(Spark概述),可用于进行复杂的内存分析,构建大型、低延迟的数据分析应用。DataWorks为您提供EMR Spark节点,便于您在DataWorks上进行Spark任务的开发和周期性调度。本文为您介绍如何创建EMR Spark节点,并通过详细的应用示例,为您介绍EMR Spark节点的功能。
背景信息
本节点支持使用OSS REF方式引用OSS资源,详情请参见方案一:直接引用OSS资源。
前提条件
数据开发(DataStudio)中已创建业务流程。
数据开发(DataStudio)基于业务流程对不同开发引擎进行具体开发操作,所以您创建节点前需要先新建业务流程,操作详情请参见创建业务流程。
已创建阿里云EMR集群,并注册EMR集群至DataWorks。
创建EMR相关节点并开发EMR任务前,您需要先将EMR集群注册至DataWorks工作空间,操作详情请参见注册EMR集群至DataWorks。
(可选,RAM账号需要)进行任务开发的RAM账号已被添加至对应工作空间中,并具有开发或空间管理员(权限较大,谨慎添加)角色权限,添加成员的操作详情请参见为工作空间添加空间成员。
已购买独享调度资源组并完成资源组配置,包括绑定工作空间、网络配置等,详情请参见新增和使用独享调度资源组。
使用限制
该类任务不支持公共调度资源组运行,支持在2023年12月1号之后购买的资源组运行。
DataLake或自定义集群若要在DataWorks管理元数据,需先在集群侧配置EMR-HOOK。若未配置,则在DataWorks中无法实时展示元数据、生成审计日志、展示血缘关系,EMR相关治理任务也将无法开展。配置EMR-HOOK,详情请参见配置Hive的EMR-HOOK。
准备工作:开发Spark任务并获取JAR包
在使用DataWorks调度EMR Spark任务前,您需要先在EMR中开发Spark任务代码并完成任务代码的编译,生成编译后的任务JAR包,EMR Spark任务的开发指导详情请参见Spark概述。
后续您需要将任务JAR包上传至DataWorks,在DataWorks中周期性调度EMR Spark任务。
创建EMR Spark节点
进入数据开发页面。
登录DataWorks控制台,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
创建业务流程。
鼠标悬停至
 图标,选择新建业务流程。
图标,选择新建业务流程。在新建业务流程对话框,输入业务名称。
单击新建。
创建EMR Spark节点。
鼠标悬停至
 图标,选择。
图标,选择。您也可以找到相应的业务流程,右键单击业务流程,选择。
在新建节点对话框中,输入名称,并选择引擎实例、节点类型及路径。
说明节点名称必须是大小写字母、中文、数字、下划线(_)和小数点(.),且不能超过128个字符。
单击确认,进入EMR Spark节点编辑页面。
如果您已有业务流程,则可以忽略该步骤。
开发Spark任务
双击已创建的节点,进入任务开发页面,进行以下任务开发操作。
方案一:直接引用OSS资源
当前节点可直接通过OSS REF的方式直接引用OSS资源,在运行EMR节点时,DataWorks会自动加载代码中的OSS资源至本地使用。该方式常用于“需要在EMR任务中运行JAR依赖”、“EMR任务需依赖脚本”等场景。引用格式如下:
ossref://{endpoint}/{bucket}/{object}endpoint:OSS对外服务的访问域名。Endpoint为空时,仅支持使用与当前访问的EMR集群同地域的OSS,即OSS的Bucket需要与EMR集群所在地域相同。
Bucket:OSS用于存储对象的容器,每一个Bucket有唯一的名称,登录OSS管理控制台,可查看当前登录账号下所有Bucket。
object:存储在Bucket中的一个具体的对象(文件名称或路径)。
该功能不支持公共调度资源组。并且若您在2023年12月1日前购买的资源组,需联系我们进行资源组升级以使用此功能。
方案二:先上传资源后引用EMR JAR资源
DataWorks也支持您从本地先上传资源至DataStudio,再引用资源。EMR Spark任务编译完成后,您需获取编译后的JAR包,建议根据JAR包大小选择不同方式存储JAR包资源。上传JAR包资源,创建为DataWorks的EMR资源并提交,或直接存储在EMR的HDFS存储中。
JAR包小于200MB时
创建EMR JAR资源。
JAR包小于200MB时,可将JAR包通过本地上传的方式上传为DataWorks的EMR JAR资源,便于后续在DataWorks控制台进行可视化管理,创建完成资源后需进行提交,操作详情请参见创建和使用EMR资源。
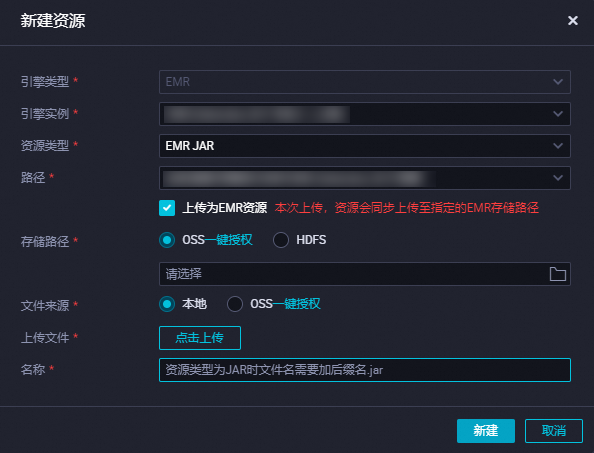 说明
说明首次创建EMR资源时,如果您希望JAR包上传后存储在OSS中,您需要先参考界面提示进行授权操作。
引用EMR JAR资源。
双击创建的EMR Spark节点,打开EMR Spark 节点的代码编辑页面。
在节点下,找到上述步骤中已上传的EMR JAR资源,右键选择引用资源。
选择引用资源后,当前打开的EMR Spark节点的编辑页面会自动添加资源引用代码,引用代码示例如下。
##@resource_reference{"spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar"} spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar如果成功自动添加上述引用代码,表明资源引用成功。其中,spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar为您实际上传的EMR JAR资源名称。
改写EMR Spark节点代码,补充spark submit命令,改写后的示例如下。
重要EMR Spark节点编辑代码时不支持注释语句,请务必参考如下示例改写任务代码,不要随意添加注释,否则后续运行节点时会报错。
##@resource_reference{"spark-examples_2.11-2.4.0.jar"} spark-submit --class org.apache.spark.examples.SparkPi --master yarn spark-examples_2.11-2.4.0.jar 100其中:
org.apache.spark.examples.SparkPi:为您实际编译的JAR包中的任务主Class。
spark-examples_2.11-2.4.0.jar:为您实际上传的EMR JAR资源名称。
其他参数可参考以上示例不做修改,您也可执行以下命令查看spark submit的使用帮助,根据需要修改spark submit命令。
重要若您需要在Spark节点中使用Spark-submit命令简化的参数,您需要在代码中自行添加,例如,
--executor-memory 2G。Spark节点仅支持使用Yarn的Cluster提交作业。
spark-submit方式提交的任务,deploy-mode推荐使用cluster模式,不建议使用client模式。
spark-submit --help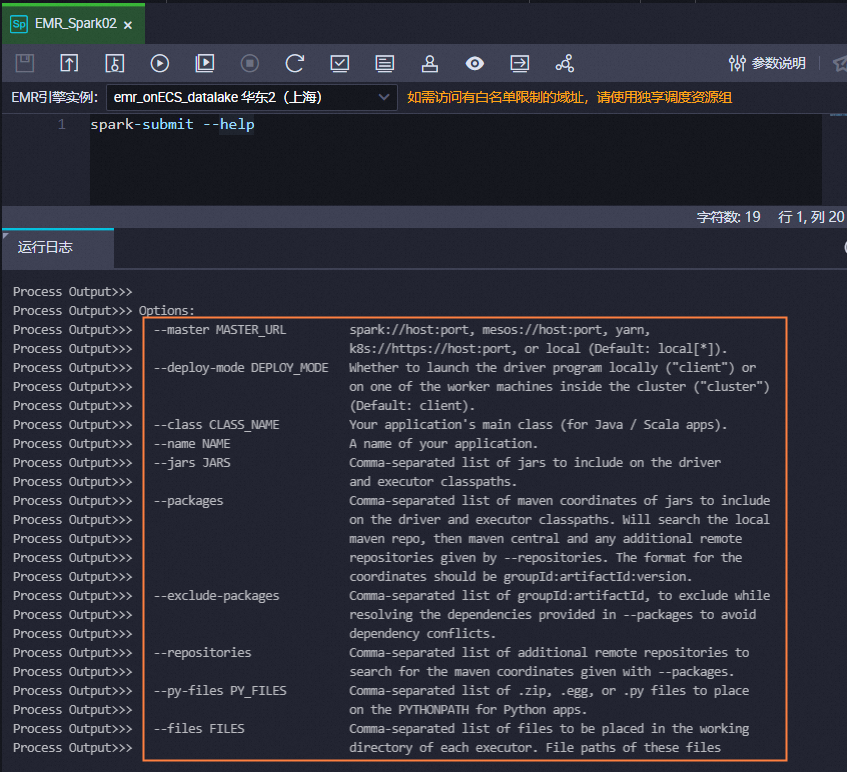
JAR包大于等于200MB时
创建EMR JAR资源。
JAR包大于等于200MB时,无法通过本地上传的方式直接上传为DataWorks的资源,建议直接将JAR包存储在EMR的HDFS中,并记录下JAR包的存储路径。便于后续在DataWorks调度Spark任务时引用该路径。
引用EMR JAR资源。
JAR包存储在HDFS时,您可以直接在EMR Spark节点中通过代码指定JAR包路径的方式引用JAR包。
双击创建的EMR Spark节点,打开EMR Spark 节点的代码编辑页面。
编写spark submit命令,示例如下。
spark-submit --master yarn --deploy-mode cluster --name SparkPi --driver-memory 4G --driver-cores 1 --num-executors 5 --executor-memory 4G --executor-cores 1 --class org.apache.spark.examples.JavaSparkPi hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar 100其中:
hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar:为JAR包实际在HDFS中的路径。
org.apache.spark.examples.JavaSparkPi:为您实际编译的JAR包中的任务主class。
其他参数为实际EMR集群的参数,需根据实际情况进行修改配置。您也可以执行以下命令查看spark submit的使用帮助,根据需要修改spark submit命令。
重要若您需要在Spark节点中使用Spark-submit命令简化的参数,您需要在代码中自行添加,例如,
--executor-memory 2G。Spark节点仅支持使用Yarn的Cluster提交作业。
spark-submit方式提交的任务,deploy-mode推荐使用cluster模式,不建议使用client模式。
spark-submit --help
配置高级参数
不同类型EMR集群涉及配置的高级参数有差异,具体如下表。对于任务的相关参数配置,请参考Spark Configuration。
DataLake集群/自定义集群:EMR on ECS
高级参数 | 配置说明 |
“queue” | 提交作业的调度队列,默认为default队列。 如果您在注册EMR集群至DataWorks工作空间时,配置了工作空间级的YARN资源队列:
关于EMR YARN说明,详情请参见队列基础配置,注册EMR集群时的队列配置详情请参见设置全局YARN资源队列。 |
“priority” | 优先级,默认为1。 |
其他 |
|
Hadoop集群:EMR on ECS
高级参数 | 配置说明 |
“queue” | 提交作业的调度队列,默认为default队列。 如果您在注册EMR集群至DataWorks工作空间时,配置了工作空间级的YARN资源队列:
关于EMR YARN说明,详情请参见队列基础配置,注册EMR集群时的队列配置详情请参见设置全局YARN资源队列。 |
“priority” | 优先级,默认为1。 |
“FLOW_SKIP_SQL_ANALYZE” | SQL语句执行方式。取值如下:
说明 该参数仅支持用于数据开发环境测试运行流程。 |
“USE_GATEWAY” | 设置本节点提交作业时,是否通过Gateway集群提交。取值如下:
说明 如果本节点所在的集群未关联Gateway集群,此处手动设置参数取值为 |
其他 |
|
Spark集群:EMR ON ACK
您可以直接在高级配置里追加自定义SPARK参数。例如,
"spark.eventLog.enabled" : false,DataWorks会自动在最终下发EMR集群的代码中进行补全,格式为:--conf key=value。还支持配置全局Spark参数,详情请参见设置全局Spark参数。
配置任务调度
如果您需要周期性执行创建的节点任务,可以单击节点编辑页面右侧的调度配置,根据业务需求配置该节点任务的调度信息:
配置任务调度的基本信息,详情请参见配置基础属性。
配置时间调度周期、重跑属性和上下游依赖关系,详情请参见时间属性配置说明及配置同周期调度依赖。
说明您需要设置节点的重跑属性和依赖的上游节点,才可以提交节点。
配置资源属性,详情请参见配置资源属性。访问公网或VPC网络时,请选择与目标节点网络连通的调度资源组作为周期调度任务使用的资源组。详情请参见配置资源组与网络连通。
调试代码任务
(可选)选择运行资源组、赋值自定义参数取值。
在工具栏单击
 图标,在参数对话框选择已调试运行需要使用的独享调度资源组。
图标,在参数对话框选择已调试运行需要使用的独享调度资源组。如果您的任务代码中有使用调度参数变量,可在此处为变量赋值,用于调试。参数赋值逻辑详情请参见运行,高级运行和开发环境冒烟测试赋值逻辑有什么区别。
保存并运行SQL语句。
在工具栏,单击
 图标,保存编写的SQL语句,单击
图标,保存编写的SQL语句,单击 图标,运行创建的SQL任务。
图标,运行创建的SQL任务。(可选)冒烟测试。
如果您希望在开发环境进行冒烟测试,可在执行节点提交,或节点提交后执行,冒烟测试,操作详情请参见执行冒烟测试。
后续步骤
相关文档
- 本页导读 (1)