DeepSpeed是一个开源的深度学习优化库,提供了分布式训练和模型优化的功能,可以有效的加速训练过程。本文介绍如何使用Arena快速、方便地提交DeepSpeed的分布式训练作业,并通过TensorBoard可视化查看训练作业。
索引
前提条件
已创建包含GPU的Kubernetes集群。具体操作,请参见创建GPU集群。
已安装云原生AI套件,且机器学习命令行工具ack-arena的版本不低于0.9.10。具体操作,请参见部署云原生AI套件。
已安装Arena客户端,且版本不低于0.9.10。具体操作,请参见配置Arena客户端。
已为集群配置了Arena使用的PVC。具体操作,请参见配置NAS共享存储。
使用说明
本示例使用DeepSpeed训练一个掩码语言模型(Masked Language Model)。为方便运行,已将示例代码和数据集下载至示例镜像registry.cn-beijing.aliyuncs.com/acs/deepspeed:hello-deepspeed中;若您无需使用示例镜像,您也可以从Git URL下载源代码,并将数据集存放在共享存储系统(基于NAS的PV和PVC)中。本示例假设您已经获得了名称为training-data的PVC实例(一个共享存储),用来存放训练结果。
如需自定义训练镜像,可参见如下方式。
可参见Dockerfile,在基础镜像中安装OpenSSH。
说明训练任务需要通过SSH免密访问,生产环境中请您保障密钥Secret的安全性。
或者使用ACK提供的DeepSpeed基础镜像。
registry.cn-beijing.aliyuncs.com/acs/deepspeed:v072_base
操作步骤
执行如下命令,检查可用的GPU资源。
arena top node预期输出:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated) cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 0 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 0 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 0 --------------------------------------------------------------------------------------------------- Allocated/Total GPUs In Cluster: 0/3 (0.0%)预期输出表明,有3个包含GPU的节点可用于运行训练作业。
执行
arena submit deepspeedjob [--falg] command形式的命令,提交DeepSpeed作业。如果您使用ACK提供的DeepSpeed基础镜像,可执行如下代码,提交包含1个Launcher节点,3个Worker节点的DeepSpeed训练任务。
arena submit deepspeedjob \ --name=deepspeed-helloworld \ --gpus=1 \ --workers=3 \ --image=registry.cn-beijing.aliyuncs.com/acs/deepspeed:hello-deepspeed \ --data=training-data:/data \ --tensorboard \ --logdir=/data/deepspeed_data \ "deepspeed /workspace/DeepSpeedExamples/HelloDeepSpeed/train_bert_ds.py --checkpoint_dir /data/deepspeed_data"参数
是否必选
说明
默认值
--name
必选
提交的作业名称,全局唯一,不能重复。
无
--gpus
可选
作业Worker节点需要使用的GPU有卡数。
0
--workers
可选
作业Worker节点的数量。
1
--image
必选
训练环境的镜像地址。
无
--data
可选
通过挂载共享存储卷PVC到运行环境中,使您的代码可以访问PVC的数据。它由两部分组成,通过英文冒号(:)分割。
冒号左侧是您已经准备好的PVC名称。通过执行
arena data list命令,查看当前集群可用的PVC列表。冒号右侧是您想将PVC的挂载到运行环境中的路径,也是您训练代码要读取数据的本地路径。
如果没有可用的PVC,您可创建PVC。具体操作,请参见配置NAS共享存储。
无
--tensorboard
可选
为训练任务开启一个TensoBoard服务,用作数据可视化。您可以结合--logdir指定TensorBoard要读取的event路径。不指定该参数,则不开启TensorBoard服务。
无
--logdir
可选
需要结合--tensorboard一起使用,该参数表示TensorBoard需要读取event数据的路径。
/training_logs
如果您使用非公开Git代码库。则可以使用如下命令,提交DeepSpeed作业。
arena submit deepspeedjob \ ... --sync-mode=git \ # 同步代码的模式,您可以指定模式为git或rsync。 --sync-source=<非公开Git代码库地址> \ # 同步代码的仓库地址,需要和--sync-mode一起使用。如果--sync-mode=git,该参数可以为任何github项目地址。 --env=GIT_SYNC_USERNAME=yourname \ --env=GIT_SYNC_PASSWORD=yourpwd \ "deepspeed /workspace/DeepSpeedExamples/HelloDeepSpeed/train_bert_ds.py --checkpoint_dir /data/deepspeed_data"arena命令使用git-sync同步源代码。您可以设置在git-sync项目中定义的环境变量。
预期输出:
trainingjob.kai.alibabacloud.com/deepspeed-helloworld created INFO[0007] The Job deepspeed-helloworld has been submitted successfully INFO[0007] You can run `arena get deepspeed-helloworld --type deepspeedjob` to check the job status执行如下命令,查看当前通过Arena提交的所有作业。
arena list预期输出:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE deepspeed-helloworld RUNNING DEEPSPEEDJOB 3m 3 3 192.168.9.69执行如下命令,检查作业使用的GPU资源。
arena top job预期输出:
NAME STATUS TRAINER AGE GPU(Requested) GPU(Allocated) NODE deepspeed-helloworld RUNNING DEEPSPEEDJOB 4m 3 3 192.168.9.69 Total Allocated/Requested GPUs of Training Jobs: 3/3执行如下命令,检查集群所使用的GPU资源。
arena top node预期输出:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated) cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 1 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 1 cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 1 --------------------------------------------------------------------------------------------------- Allocated/Total GPUs In Cluster: 3/3 (100%)执行如下命令,获取作业详情,并获取TensorBoard Web服务地址。
arena get deepspeed-helloworld预期输出:
Name: deepspeed-helloworld Status: RUNNING Namespace: default Priority: N/A Trainer: DEEPSPEEDJOB Duration: 6m Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- deepspeed-helloworld-launcher Running 6m true 0 cn-beijing.192.1xx.x.x deepspeed-helloworld-worker-0 Running 6m false 1 cn-beijing.192.1xx.x.x deepspeed-helloworld-worker-1 Running 6m false 1 cn-beijing.192.1xx.x.x deepspeed-helloworld-worker-2 Running 6m false 1 cn-beijing.192.1xx.x.x Your tensorboard will be available on: http://192.1xx.x.xx:31870本示例已开启了TensorBoard,因此上述作业详情的最后两行显示TensorBoard的Web访问地址;如果没有开启TensorBoard,最后两行信息将不存在。
通过浏览器查看TensorBoard。
执行如下命令,将集群中的TensorBoard映射到本地9090端口。
kubectl port-forward svc/deepspeed-helloworld-tensorboard 9090:6006在浏览器中访问
localhost:9090,即可查看TensorBoard。如下图所示。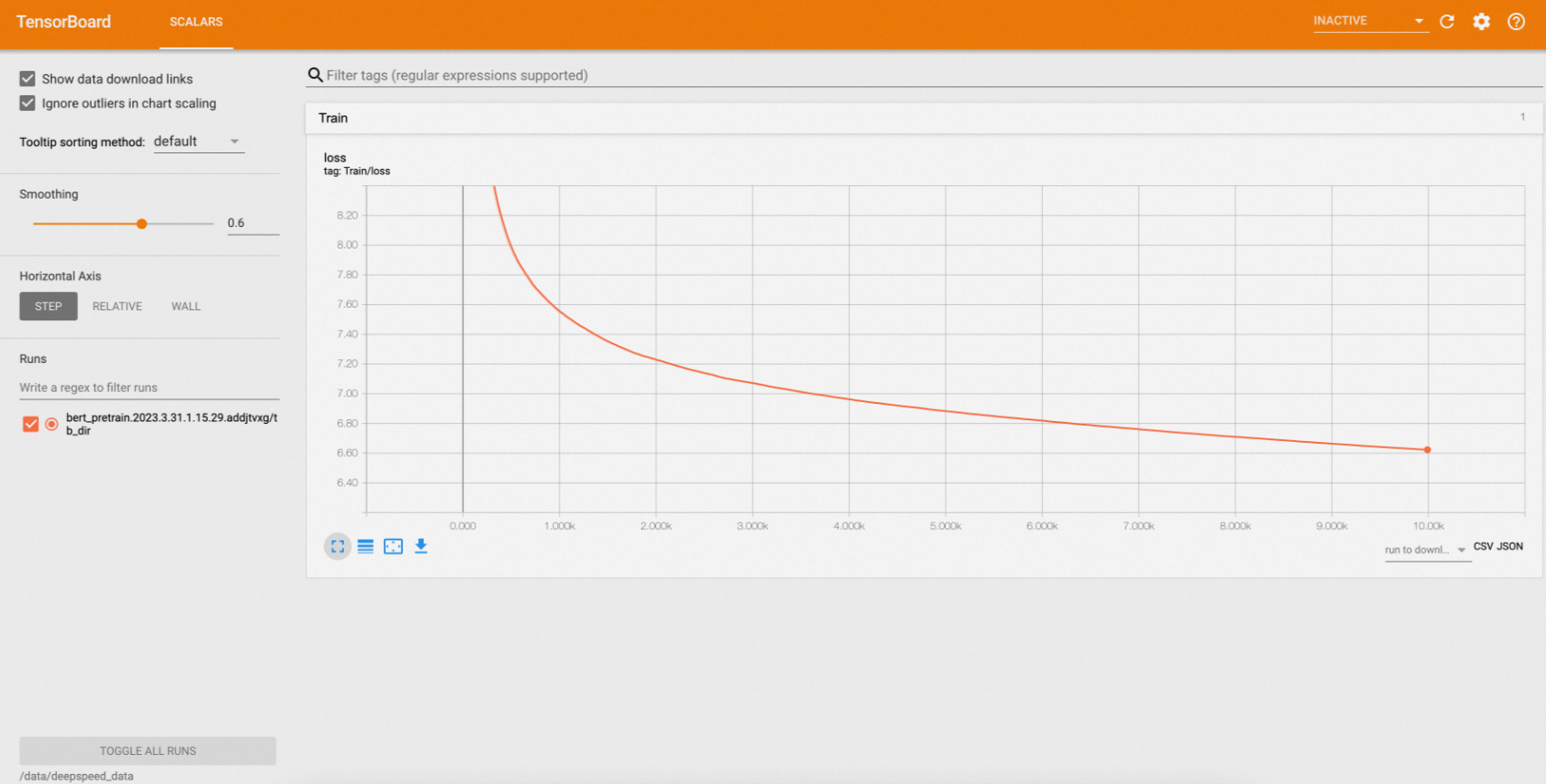
获取作业日志信息。
您可执行如下命令,获取作业日志信息。
arena logs deepspeed-helloworld预期输出:
deepspeed-helloworld-worker-0: [2023-03-31 08:38:11,201] [INFO] [logging.py:68:log_dist] [Rank 0] step=7050, skipped=24, lr=[0.0001], mom=[(0.9, 0.999)] deepspeed-helloworld-worker-0: [2023-03-31 08:38:11,254] [INFO] [timer.py:198:stop] 0/7050, RunningAvgSamplesPerSec=142.69733028759384, CurrSamplesPerSec=136.08094834473613, MemAllocated=0.06GB, MaxMemAllocated=1.68GB deepspeed-helloworld-worker-0: 2023-03-31 08:38:11.255 | INFO | __main__:log_dist:53 - [Rank 0] Loss: 6.7574 deepspeed-helloworld-worker-0: [2023-03-31 08:38:13,103] [INFO] [logging.py:68:log_dist] [Rank 0] step=7060, skipped=24, lr=[0.0001], mom=[(0.9, 0.999)] deepspeed-helloworld-worker-0: [2023-03-31 08:38:13,134] [INFO] [timer.py:198:stop] 0/7060, RunningAvgSamplesPerSec=142.69095076844823, CurrSamplesPerSec=151.8552037291255, MemAllocated=0.06GB, MaxMemAllocated=1.68GB deepspeed-helloworld-worker-0: 2023-03-31 08:38:13.136 | INFO | __main__:log_dist:53 - [Rank 0] Loss: 6.7570 deepspeed-helloworld-worker-0: [2023-03-31 08:38:14,924] [INFO] [logging.py:68:log_dist] [Rank 0] step=7070, skipped=24, lr=[0.0001], mom=[(0.9, 0.999)] deepspeed-helloworld-worker-0: [2023-03-31 08:38:14,962] [INFO] [timer.py:198:stop] 0/7070, RunningAvgSamplesPerSec=142.69048436022115, CurrSamplesPerSec=152.91029839772997, MemAllocated=0.06GB, MaxMemAllocated=1.68GB deepspeed-helloworld-worker-0: 2023-03-31 08:38:14.963 | INFO | __main__:log_dist:53 - [Rank 0] Loss: 6.7565您还可以通过命令
arena logs $job_name -f实时查看作业的日志输出,通过命令arena logs $job_name -t N查看尾部N行的日志,以及通过arena logs --help查询更多参数使用情况。例如,执行如下命令,查看尾部5行的日志信息。
arena logs deepspeed-helloworld -t 5预期输出:
deepspeed-helloworld-worker-0: [2023-03-31 08:47:08,694] [INFO] [launch.py:318:main] Process 80 exits successfully. deepspeed-helloworld-worker-2: [2023-03-31 08:47:08,731] [INFO] [launch.py:318:main] Process 44 exits successfully. deepspeed-helloworld-worker-1: [2023-03-31 08:47:08,946] [INFO] [launch.py:318:main] Process 44 exits successfully. /opt/conda/lib/python3.8/site-packages/apex/pyprof/__init__.py:5: FutureWarning: pyprof will be removed by the end of June, 2022 warnings.warn("pyprof will be removed by the end of June, 2022", FutureWarning)
- 本页导读 (1)