DataWorks支持通过内置敏感字段类型和自定义敏感字段类型,有效识别组织内的敏感数据。本文将为您介绍如何新建、配置数据识别规则。
背景信息
DataWorks支持您按照数据的敏感级别和所属分类定义数据识别规则,帮助您识别组织内的敏感数据,对于识别结果不准确的数据,您可以手动修正数据,并在敏感数据概况模块为您展示最近的通过数据识别规则命中的、按照项目细分的全部敏感字段分布情况,数据识别规则的使用逻辑如下图所示。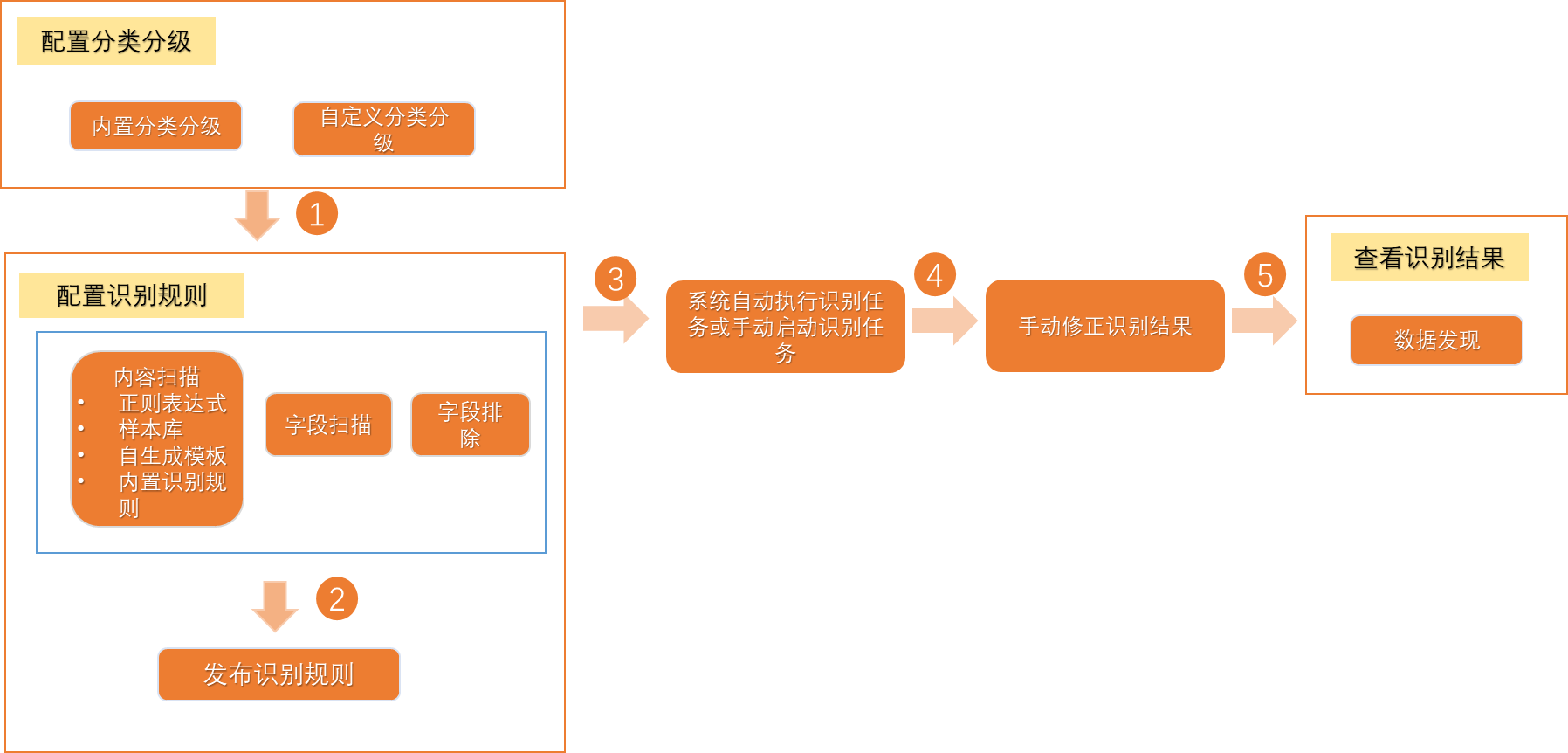
对CDH引擎中数据进行识别和脱敏时,您需要通过DataWorks的数据抽样采集器功能,从CDH Hive表中随机抽取表的部分数据用于数据保护伞的敏感数据识别,抽样采集的数据不会存储至DataWorks中,没有数据泄漏风险。详情请参见:CDH Hive数据抽样采集器。
进入数据识别规则
登录DataWorks控制台后,进入数据保护伞页面,操作详情请参见数据保护伞概述。
单击开始体验,默认进入数据保护伞的首页。
单击左侧导航栏中的,在数据识别规则页面您可以新增敏感字段类型并配置识别规则。
配置敏感字段所属分类
如果您是首次使用数据保护伞的新用户,进入数据识别规则页面后会在左侧区域展示数据分类分级模板的默认分类,您可以输入分类名称进行搜索。还支持您单击分类名称后的
 图标添加同层分类、添加子分类、重命名和删除分类。
图标添加同层分类、添加子分类、重命名和删除分类。如果您是已使用过数据保护伞的老用户,进入数据识别规则页面后需要您根据需求在左侧区域创建数据分类。单击未分类后的
图标添加分类。
分类名称必须唯一,仅支持中英文、数字,长度限制1~30个字符。
删除时请先确认该分类下是否有已发布的敏感字段类型。如果有,请将该分类下全部敏感字段类型下架后方可删除。详情请参见批量下架。
添加敏感字段类型
选择敏感字段所在的数据分类。
在左侧的内置分类分级模板区域选择新增敏感字段所在的数据分类。
新增敏感字段类型并配置识别规则。
单击右上角的+敏感字段类型。
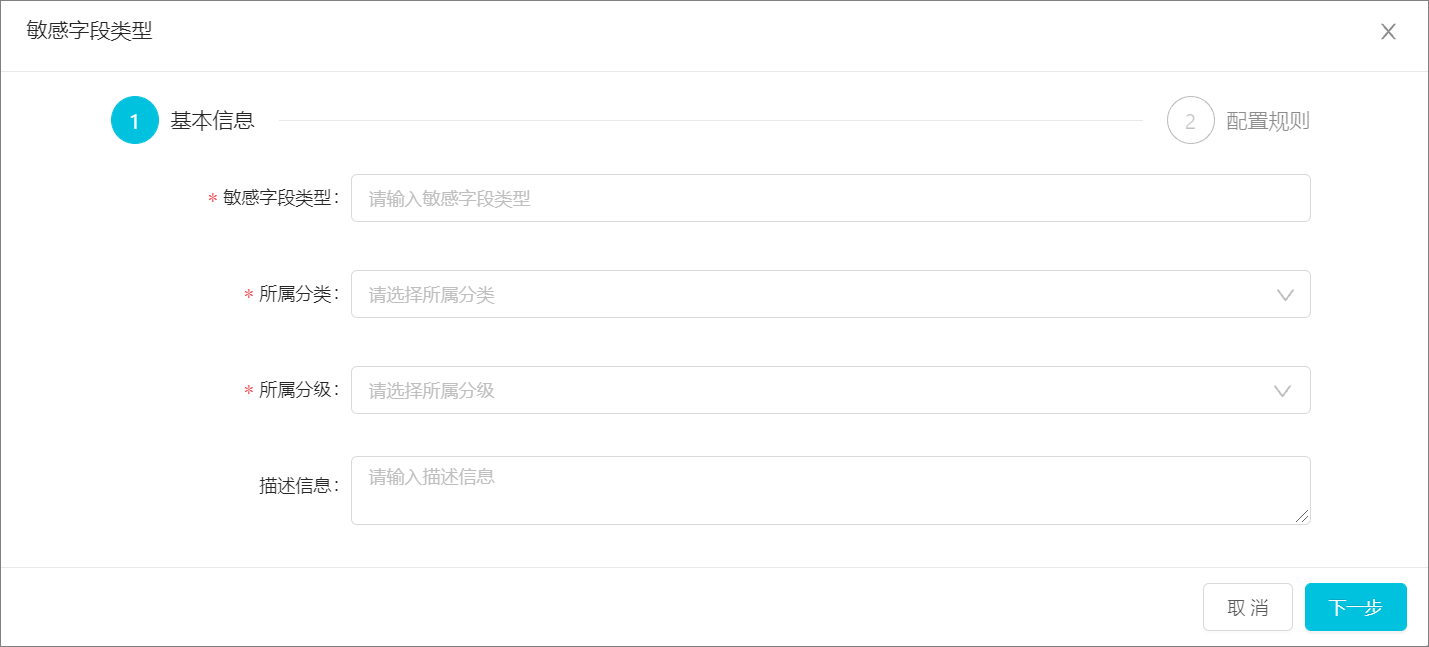
在基本信息页签中配置敏感字段类型信息,单击下一步。
配置
说明
敏感字段类型
自定义敏感字段类型的名称,例如:姓名、身份证号、手机号等。
说明定义敏感字段类型时,名称必须唯一,当存在重名时系统会提示敏感字段类型重复。
所属分类
下拉列表展示步骤1选中的数据分类,如果您需要修改分类可以在下拉列表进行选择。
所属分级
选择敏感字段类型所属级别,对配置的数据进行等级划分。如果现有的分级不满足需求,请进入数据分类分级页面进行设置,详情请参见配置敏感数据分类分级。
描述信息
对当前敏感字段进行简单描述,长度0~100字符,不包含特殊字符。
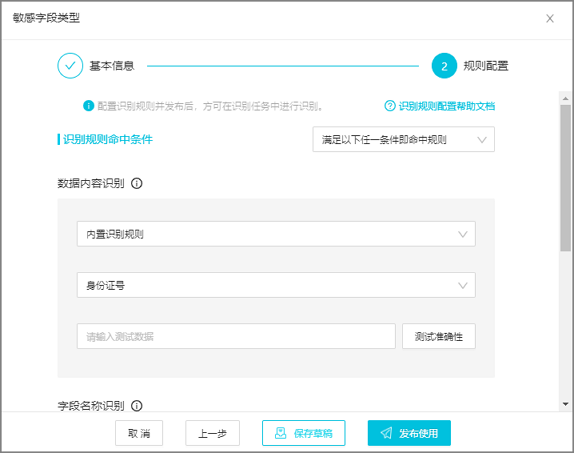
在规则配置页签中,配置识别规则命中条件、敏感字段识别规则并测试规则准确性。识别规则配置完成并发布后,即可在识别任务中进行识别。
 说明
说明规则修改后,历史规则命中的字段识别结果将被清理。
配置
说明
识别规则命中条件
您可以在右侧下拉列表中选择识别规则命中条件:
满足以下任一条件即命中规则:满足数据内容识别或字段名称识别规则其中任何一个条件,即可命中识别规则。
同时满足以下条件即命中规则:同时满足数据内容识别和字段名称识别规则时才可以命中识别规则。
说明识别规则命中条件仅对数据内容识别和字段名称识别规则生效。
数据内容识别
根据规则类型定义敏感数据识别规则的内容,用于匹配敏感数据的文本。
说明数据内容识别的信息为字段的数据内容,例如,字段name,包含张三、李四等数据。则识别的内容为张三、李四等具体的数据内容。
规则类型选择正则表达式时:在正则表达式文本框中手动输入该类型的正则表达式,并在测试数据输入框中输入样本数据测试识别规则准确性。
规则类型选择内置识别规则时:单击请选择内置识别规则下拉框,选择内置识别规则,并在测试数据输入框中输入样本数据测试识别规则准确性。
说明仅企业版及以上版本可以选择内置识别规则。
规则类型选择样本库时:单击请选择样本库下拉框,选择已配置的样本,并在测试数据输入框中输入样本数据测试识别规则准确性。样本配置请参见通过样本库识别。
规则类型选择自生成模型时:单击请选择自生成模型下拉框,选择自生成模型,并在测试数据输入框中输入样本数据测试识别规则准确性。自生成模型配置请参见通过自定义模型识别。
说明仅MaxCompute引擎支持选择自生成模型规则。仅DataWorks企业版及以上才可使用自生成模型。
说明仅DataWorks专业版及以上版本,才可以使用内容扫描功能。如果您使用的是低版本的DataWorks,则需要升级至专业版及以上版本,才可以使用该功能。升级DataWorks版本,详情请参见DataWorks版本服务计费说明。
字段名称识别
在输入框中输入需要识别为敏感数据的字段,支持多个字段匹配,各字段间为或关系。输入格式为:project.table.column,其中任一段可以使用*作为通配符,例如。
abcd.efg.*:abcd的project下efg表中所有字段都会被识别为敏感数据。
ab*.*.salary:ab开头的project下,所有表中的salary字段都会被识别为敏感数据。
*cd.ef*.sa*ry:cd结尾的project下,ef开头的表中,所有以sa开头、ry结尾的字段都会被识别为敏感数据。
说明字段名称识别的信息为字段的名称,例如,字段name,包含张三、李四等数据,则识别的内容为字段名称name。
字段注释识别
识别的信息为字段注释,如敏感字段类型为手机号时,对应字段注释为:手机号、联系方式,则可配置包含手机号、联系方式时,识别为手机号类型。在输入框中输入字段注释,字符长度0-100,字符不限,可添加多个输入框,最多10个。
字段排除
在输入框中输入需要排除的字段,符合字段排除规则的字段将不会被该识别规则命中。输入格式为:project.table.column,其中任一段可以使用*作为通配符,例如。
abcd.efg.*:abcd的project下efg表中所有字段都会被排除,不会识别为该类敏感数据。
ab*.*.salary:ab开头的project下,所有表中的salary字段都会被排除,不会识别为该类敏感数据。
*cd.ef*.sa*ry:cd结尾的project下,ef开头的表中,所有以sa开头、ry结尾的字段都会被排除,不会识别为该类敏感数据。
命中率配置
支持您自定义识别规则命中率,当一列数据中的非空数据,超过命中阈值的数据符合数据内容识别条件时,则认为命中该识别规则。命中率默认配置为50%,命中率计算公式为:
100%*该列中命中识别规则的数据条数/该列数据的总条数。说明命中率仅对数据内容识别规则生效。
确认配置无误后,您可以单击保存草稿将新增的敏感字段类型状态置为草稿,您还可以单击发布使用,发布后,敏感字段类型状态置为已发布,并触发新的识别任务。
说明某列数据可能会命中不同敏感字段类型的识别规则命中条件。当这些敏感字段类型的命中条件个数相同时,识别顺序是。当命中条件的个数和类型都相同时,优先命中分级等级高的敏感字段类型的识别规则。
完成敏感字段类型的配置后,可在数据发现、数据访问和数据风险等模块通过筛选已配置的敏感字段类型及级别进行查看。
手动开启敏感数据识别任务
支持您手动触发或停止敏感数据识别任务,并查看敏感数据识别任务的运行状态及执行日志。
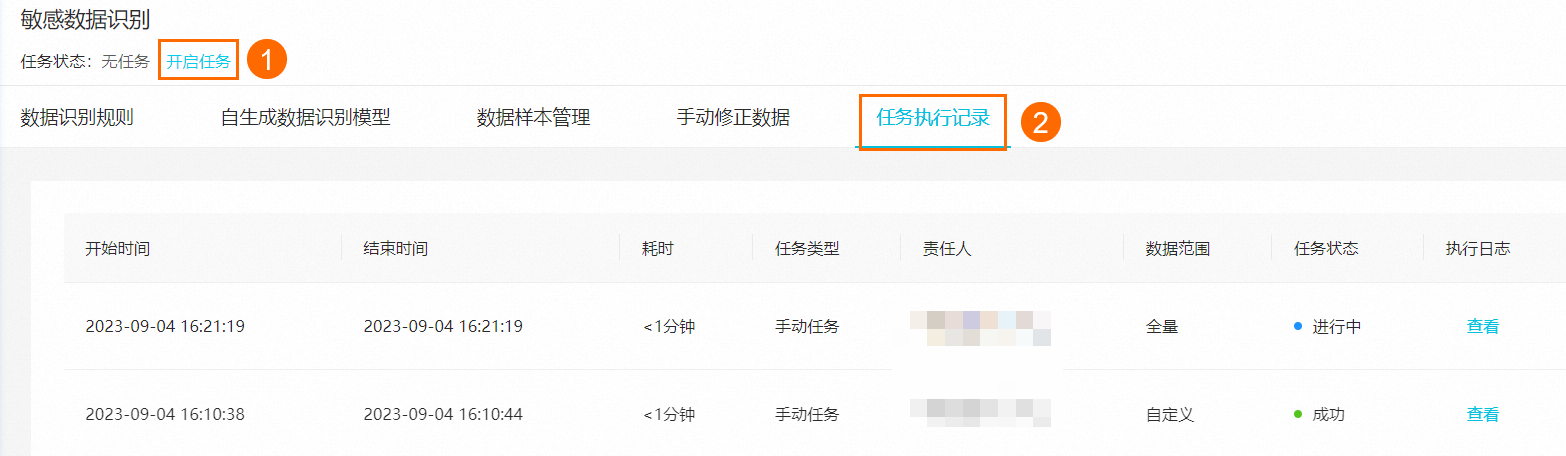
单击页面上方的开启任务,在右侧弹出的对话框中配置扫描范围,支持您扫描全量任务或自定义扫描范围。
任务执行中会显示执行进度,您可以手动终止识别任务。
敏感数据识别任务执行完成后,您可以进入任务执行记录页签,查看敏感数据识别任务的运行状态及执行日志。
管理敏感字段类型
复制敏感字段类型
单击相应敏感字段类型后的
 图标,即可生成一个完全一致的规则。复制后的名称加后缀-副本,复制的规则默认状态为草稿,您可以根据需求进行配置。
图标,即可生成一个完全一致的规则。复制后的名称加后缀-副本,复制的规则默认状态为草稿,您可以根据需求进行配置。编辑敏感字段类型
单击相应敏感字段类型后的
 图标,可以修改敏感字段的规则配置。内置敏感字段类型不可修改敏感字段类型名称、所属分类、所属分级信息,自定义敏感字段类型支持修改敏感字段类型信息。
图标,可以修改敏感字段的规则配置。内置敏感字段类型不可修改敏感字段类型名称、所属分类、所属分级信息,自定义敏感字段类型支持修改敏感字段类型信息。删除敏感字段类型
单击相应敏感字段类型后的
 图标,在对话框中单击删除即可。重要
图标,在对话框中单击删除即可。重要删除敏感字段类型影响较大,请仔细阅读以下影响后再确认是否删除。
识别结果中该敏感字段类型的记录将会删除。详情请参见手动修正数据。
数据发现中的敏感数据分布信息将不统计该敏感字段类型。详情请参见敏感数据概况。
已配置的风险识别规则中有对应配置项的将会取消该敏感字段类型。详情请参见风险识别管理(旧版)
批量发布
发布对应的敏感字段类型后,系统开始进行敏感数据识别,识别结果请参见敏感数据概况。
单击批量发布按钮,勾选需要发布的敏感字段类型。
说明状态为已发布的敏感字段不可勾选。
单击发布,对应敏感字段类型的状态置为已发布。
点击取消,恢复原始状态。
敏感数据识别任务
每天早上9点会开始运行敏感数据识别自动任务。您也可以在批量发布任务后,手动触发敏感数据识别任务。
在页面顶端单击开启任务按钮开发敏感数据识别任务。
在开启敏感数据识别任务面板里,设置扫描范围为全量或自定义范围。
配置
说明
全量
扫描当前租户授权账号下全部可获取的数据。
自定义范围
项目空间范围默认全部数据引擎和全部项目空间。数据引擎下拉列表目前只能选ODPS,项目空间下拉列表是所选数据引擎下获取到元数据的所有项目空间。
表名总体长度0-100,字符不限,不填写代表全部。支持 .*通配符,如 .*name表示以name为后缀,private.*表示以private为前缀,多个表名或字段名请用英文逗号分隔。
您可以单击添加自定义范围添加多个自定义扫描范围,最多添加10个自定义范围,最终扫描范围取多个自定义范围的并集。
设置完扫描范围后,单击开启按钮开启扫描任务,任务状态从无状态更新为任务进度条,进度计算方式为=(本次任务中已识别的表数量/本次任务中全部要识别的表数量)*100%。如果要结束任务,您可以单击终止任务按钮,然后在弹框中单击确定按钮。
说明识别规则修改后,新规则将在下一次自动任务(非实时)中启用,若需要实时触发新任务,您需要手动启动。
单击查看日志按钮可以查看最新的50条执行日志记录。
扫描任务结束后,任务状态更新为无任务。
批量下架
下架对应敏感字段类型后系统将不再进行该类敏感数据的识别,数据发现、手动修正数据等模块中的该类敏感字段类型的记录将会删除。在进行下架操作前,请确认该敏感字段类型是否被数据脱敏规则及风险识别规则引用,如果有需要先将数据脱敏规则置为失效,并取消风险识别规则中的引用。详情请参见创建数据脱敏规则和风险识别管理(旧版)。
单击批量下架按钮,勾选需要下架的敏感字段类型。
单击下架,单击对应敏感字段类型的状态置为草稿。
点击取消,恢复原始状态。
任务执行记录
任务执行记录保留近1周已完成任务的记录,不包含当前正在进行中的记录,包括开始时间,结束时间,耗时,任务类型,责任人和数据范围。
- 本页导读 (1)