如果需要使用MaxCompute备份表格存储数据或者迁移表格存储数据到MaxCompute中使用,您可以通过在DataWorks数据集成控制台新建和配置离线同步任务来实现全量数据导出。全量数据导出到MaxCompute后,您可以使用DataWorks数据分析功能查看和分析导出到MaxCompute中的数据。
注意事项
表格存储的字段名称大小写敏感,请确保MaxComputer中的字段名称与表格存储中的字段名称一致。
步骤一:新增表格存储数据源
将表格存储数据库添加为数据源,具体步骤如下:
进入数据集成页面。
以项目管理员身份登录DataWorks控制台。
在左侧导航栏,单击工作空间列表后,选择地域。
在工作空间列表页面,在目标工作空间操作列选择快速进入>数据集成。
在左侧导航栏,单击数据源。
在数据源页面,单击新增数据源。
在新增数据源对话框,找到Tablestore区块,单击Tablestore。
在新增OTS数据源对话框,根据下表配置数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
Endpoint
Tablestore实例的服务地址。更多信息,请参见服务地址。
如果Tablestore实例和目标数据源的资源在同一个地域,填写VPC地址;如果Tablestore实例和目标数据源的资源不在同一个地域,填写公网地址。
Table Store实例名称
Tablestore实例的名称。更多信息,请参见实例。
AccessKey ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。获取方式请参见创建AccessKey。
AccessKey Secret
测试资源组连通性。
创建数据源时,您需要测试资源组的连通性,以保证同步任务使用的资源组能够与数据源连通,否则将无法正常执行数据同步任务。
重要数据同步时,一个任务只能使用一种资源组。资源组列表默认仅显示独享数据集成资源组,为确保数据同步的稳定性和性能要求,推荐使用独享数据集成资源组。
如果未创建资源组,请单击新建独享数据集成资源组进行创建。具体操作,请参见新增和使用独享数据集成资源组。
单击相应资源组操作列的测试连通性,当连通状态为可连通时,表示连通成功。
测试连通性通过后,单击完成。
在数据源列表中,可以查看新建的数据源。
步骤二:新增MaxCompute数据源
具体操作与步骤一类似,只需在新增数据源对话框,找到MaxCompute区块,单击MaxCompute。
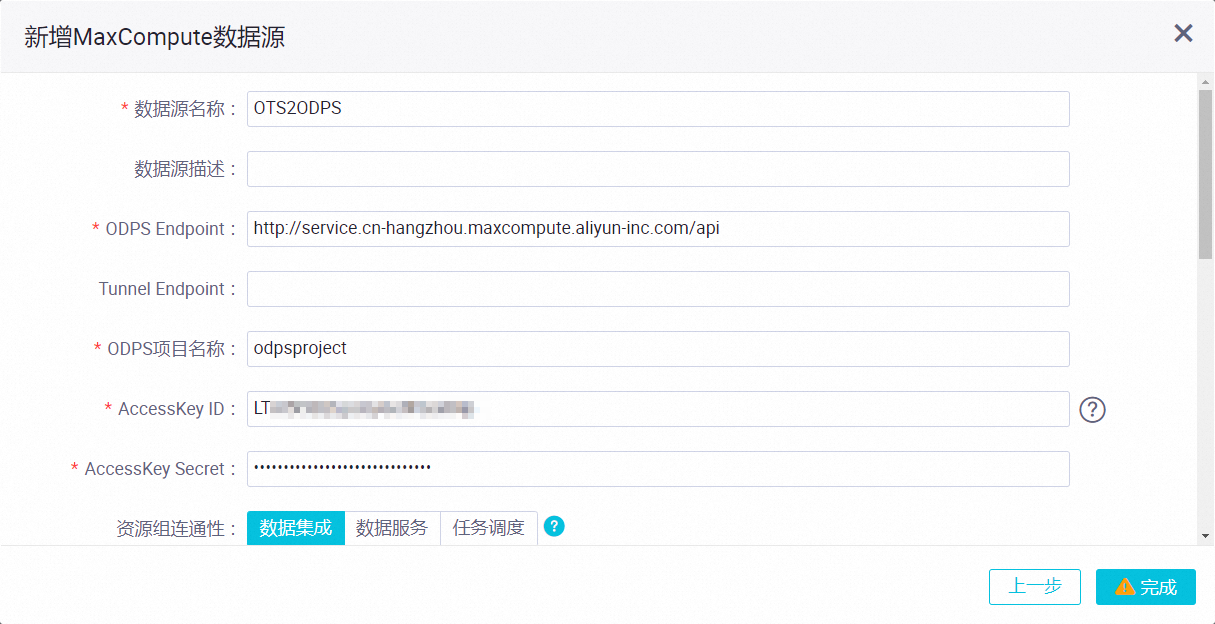
本示例中,该数据源名称使用OTS2ODPS,如下图所示。
数据同步时,一个任务只能使用一种资源组。资源组列表默认仅显示独享数据集成资源组,为确保数据同步的稳定性和性能要求,推荐使用独享数据集成资源组。
如果未创建资源组,请单击新建独享数据集成资源组进行创建。具体操作,请参见新增和使用独享数据集成资源组。
步骤三:新建同步任务节点
进入数据开发页面。
以项目管理员身份登录DataWorks控制台。
选择地域,在左侧导航栏,单击工作空间列表。
在工作空间列表页面,在目标工作空间操作列选择快速进入>数据开发。
在DataStudio控制台的数据开发页面,单击业务流程节点下的目标业务流程。
如果需要新建业务流程,请参见创建业务流程。
在数据集成节点上右键选择新建节点 > 离线同步。
在新建节点对话框,选择路径并填写节点名称。
单击确认。
在数据集成节点下会显示新建的离线同步节点。
步骤四:配置离线同步任务并启动
配置表格存储到MaxCompute的同步任务,具体步骤如下:
在数据集成节点下,双击打开新建的离线同步任务节点。
配置同步网络链接。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
重要数据同步任务的执行必须经过资源组来实现,请选择资源组并保证资源组与读写两端的数据源能联通访问。
在网络与资源配置步骤,选择数据来源为Tablestore,并选择数据源名称为步骤一:新增表格存储数据源中新增的源数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
重要请与新增数据源时选择的资源组保持一致。
选择数据去向为MaxCompute(ODPS),并选择数据源名称为步骤二:新增MaxCompute数据源中新增的目的数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务。
您可以通过向导模式或者脚本模式配置任务,请根据实际需要选择。
(推荐)向导模式
在配置任务步骤的配置数据来源与去向区域,根据实际配置数据来源和数据去向。
数据来源配置
参数
说明
表
表格存储中的数据表名称。
主键区间分布(起始)
数据读取的起始主键和结束主键,格式为JSON数组。
起始主键和结束主键需要是有效的主键或者是由INF_MIN和INF_MAX类型组成的虚拟点,虚拟点的列数必须与主键相同。
其中INF_MIN表示无限小,任何类型的值都比它大;INF_MAX表示无限大,任何类型的值都比它小。
数据表中的行按主键从小到大排序,读取范围是一个左闭右开的区间,返回的是大于等于起始主键且小于结束主键的所有的行。
假设表包含pk1(String类型)和pk2(Integer类型)两个主键列。
如果需要导出全表数据,则配置示例如下:
主键区间分布(起始)的配置示例
[ { "type": "INF_MIN" }, { "type": "INF_MIN" } ]主键区间分布(结束)的配置示例
[ { "type": "INF_MAX" }, { "type": "INF_MAX" } ]
如果需要导出
pk1="tablestore"的行,则配置示例如下:主键区间分布(起始)的配置示例
[ 。 { "type": "STRING", "value": "tablestore" }, { "type": "INF_MIN" } ]主键区间分布(结束)的配置示例
[ { "type": "STRING", "value": "tablestore" }, { "type": "INF_MAX" } ]
主键区间分布(结束)
切分配置信息
自定义切分配置信息,普通情况下不建议配置。当Tablestore数据存储发生热点,且使用Tablestore Reader自动切分的策略不能生效时,建议使用自定义的切分规则。切分指定的是在主键起始和结束区间内的切分点,仅配置切分键,无需指定全部的主键。格式为JSON数组。
数据去向配置
参数
说明
表
MaxCompute中的表名称。
写入模式
数据写入表中的模式。取值范围如下:
写入前保留已有数据(Insert Into):直接向表或静态分区中插入数据。
写入前清理已有数据(Insert Overwrite):先清空表中的原有数据,再向表或静态分区中插入数据。
空字符串转为Null写入
如果源头数据为空字符串,在向目标MaxCompute列写入时是否转为Null值写入。
同步完成才可见
单击高级配置后才会显示该参数。
同步到MaxCompute中的数据是否在同步完成后才能被查询到。
在字段映射区域,分别单击来源字段和目标字段后的
 图标,手动编辑来源字段和目标字段。重要
图标,手动编辑来源字段和目标字段。重要请确保来源字段和目标字段的数量和类型相匹配。
来源字段中的字段需要以JSON格式表示,例如
{"name":"id","type":"STRING"}。目标字段中的字段直接填写字段名称即可。一行表示一个字段,字段映射按照同行映射执行。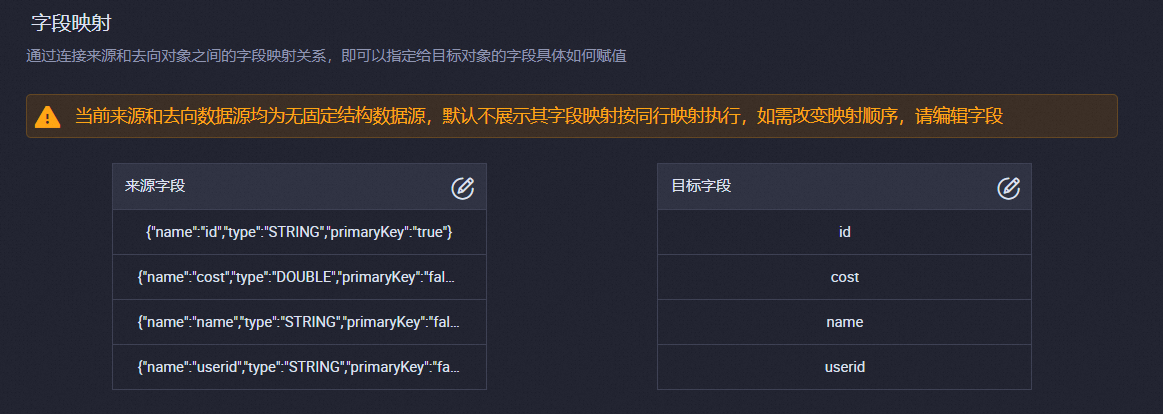
在通道控制区域,配置任务运行参数,例如同步速率、脏数据同步策略等。关于参数配置的更多信息,请参见配置通道。
单击
 图标,保存配置。说明
图标,保存配置。说明执行后续操作时,如果未保存配置,则系统会出现保存确认的提示,单击确认即可。
脚本模式
全量数据的同步需要使用到Tablestore(OTS) Reader和MaxCompute Writer插件。脚本配置规则请参见Tablestore数据源和MaxCompute数据源。
重要任务转为脚本模式后,将无法转为向导模式,请谨慎操作。
在配置任务步骤,单击
 图标,然后在弹出的对话框中单击确认。
图标,然后在弹出的对话框中单击确认。在脚本配置页面,请根据如下示例完成配置。
重要由于全量导出一般是一次性的,所以无需配置自动调度参数。如果需要配置调度参数,请参见同步增量数据到MaxCompute中的调度参数配置。
如果在脚本配置中存在变量,例如存在
${date},则需要在运行同步任务时设置变量的具体值。为了便于理解,在配置示例中增加了注释内容,实际使用脚本时请删除所有注释内容。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "ots", #插件名称,不能修改。 "parameter": { "datasource": "", #表格存储数据源名称,请根据实际填写。 "column": [ #需要导出的表格存储列名。 { "name": "column1" }, { "name": "column2" }, { "name": "column3" }, { "name": "column4" }, { "name": "column5" } ], "range": { "split": [ #用于配置Tablestore的数据表的分区信息,可以加速导出。一般情况下无需配置。 { "type": "INF_MIN" }, { "type": "STRING", "value": "splitPoint1" }, { "type": "STRING", "value": "splitPoint2" }, { "type": "STRING", "value": "splitPoint3" }, { "type": "INF_MAX" } ], "end": [ { "type": "INF_MAX" #Tablestore中第一列主键的结束位置。如果需要导出全量数据,此处请配置为INF_MAX;如果只需导出部分数据,则按需配置。当数据表存在多个主键列时,此处end中需要配置对应主键列信息。 }, { "type": "INF_MAX" }, { "type": "STRING", "value": "end1" }, { "type": "INT", "value": "100" } ], "begin": [ { "type": "INF_MIN" #Tablestore中第一列主键的起始位置。如果需要导出全量数据,此处请配置为INF_MIN;如果只需导出部分数据,则按需配置。当数据表存在多个主键列时,此处begin中需要配置对应主键列信息。 }, { "type": "INF_MIN" }, { "type": "STRING", "value": "begin1" }, { "type": "INT", "value": "0" } ] }, "table": "" #Tablestore中的数据表名称。 }, "name": "Reader", "category": "reader" }, { "stepType": "odps", #插件名称,不能修改。 "parameter": { "partition": "", #如果表为分区表,则必填。如果表为非分区表,则不能填写。需要写入数据表的分区信息,必须指定到最后一级分区。 "truncate": true, #是否清空之前的数据。 "datasource": "", #MaxCompute数据源名称,请根据实际填写。 "column": [ #MaxCompute中的列名,列名顺序必须对应TableStore中的列名顺序。 "*" ], "table": "" #MaxCompute中的表名,请提前创建完成,否则任务执行会失败。 }, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "parameter": {} } ], "setting": { "executeMode": null, "errorLimit": { "record": "0" #当错误个数超过record个数时,导入任务会失败。 }, "speed": { "throttle":true, #当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。 "concurrent":1 #作业并发数。 "mbps":"12" #限流。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }您可以通过begin和end来配置导出的数据范围,假设表包含pk1(String类型)和pk2(Integer类型)两个主键列。
如果需要导出全表数据,则配置示例如下:
"begin": [ # 需要导出数据的起始位置。 { "type": "INF_MIN" }, { "type": "INF_MIN" } ], "end": [ # 需要导出数据的结束位置。 { "type": "INF_MAX" }, { "type": "INF_MAX" } ],如果需要导出
pk1="tablestore"的行,则配置示例如下:"begin": [ # 导出数据的起始位置。 { "type": "STRING", "value": "tablestore" }, { "type": "INF_MIN" } ], "end": [ # 导出数据的结束位置。 { "type": "STRING", "value": "tablestore" }, { "type": "INF_MAX" } ],
单击
图标,保存配置。说明执行后续操作时,如果未保存脚本,则系统会出现保存确认的提示,单击确认即可。
执行同步任务。
重要全量数据一般只需要同步一次,无需配置调度属性。
单击
 图标。
图标。在参数对话框,选择运行资源组的名称。
单击运行。
运行结束后,在同步任务的运行日志页签,单击Detail log url对应的链接后。在任务的详细运行日志页面,查看
Current task status对应的状态。当
Current task status的值为FINISH时,表示任务运行完成。
步骤五:查看导入到MaxCompute中的数据
在数据地图控制台查看MaxCompute数据同步结果。
进入数据地图。
以项目管理员身份登录DataWorks控制台。
在左侧导航栏,单击工作空间列表后,选择地域。
在工作空间列表页面,在目标工作空间操作列选择快速进入>数据地图。
在数据地图控制台左侧导航栏,选择我的数据>我管理的数据。
在MaxCompute页签,单击导入数据的表名称。
在表详情页面,单击数据预览页签。
在数据预览页签,即可查看导入到MaxCompute中的数据。
- 本页导读 (1)