支持向量机SVM(Support Vector Machine)是基于统计学习理论的一种机器学习方法,通过寻求结构风险最小化,提高学习机泛化能力,从而实现经验风险和置信范围最小化。本文介绍线性支持向量机算法组件的配置方法及使用示例。
背景信息
本文中的线性支持向量机算法不通过核函数方式实现,具体实现理论请参见算法原理中的Trust Region Method for L2-SVM部分。
使用限制
线性支持向量机算法组件仅支持二分类场景。
组件配置
您可以使用以下任意一种方式,配置线性支持向量机组件参数。
方式一:可视化方式
输入框
线性支持向量机算法组件仅一个输入桩,需要接入读数据表组件,为必选项。
在工作流页面配置组件参数。
页签
参数
是否必选
描述
字段设置
特征列
是
输入列,根据输入数据表的特征选择特征列,支持BIGINT和DOUBLE类型的数据。
标签列
是
根据输入数据表的特征选择标签列,支持BIGINT、DOUBLE及STRING类型。
参数设置
正样本的标签值
否
目标基准值。如果未指定,则系统随机选定。如果正负例样本差异大,建议手动指定。
正例惩罚因子
否
正例权重值。默认值为1.0,取值范围为(0, +∞)。
负例惩罚因子
否
负例权重值。默认值为1.0,取值范围为(0, +∞)。
收敛系数
否
收敛误差。默认值为0.001,取值范围为(0, 1)。
执行调优
计算的核心数
否
如果未配置,则系统自动分配。
每个核心的内存
否
如果未配置,则系统自动分配。单位为MB。
输出桩
输出OfflineModel格式的二分类模型,下游可以接“预测”组件。
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
PAI -name LinearSVM -project algo_public
-DinputTableName="bank_data"
-DmodelName="xlab_m_LinearSVM_6143"
-DfeatureColNames="pdays,emp_var_rate,cons_conf_idx"
-DlabelColName="y"
-DpositiveLabel="0"
-DpositiveCost="1.0"
-DnegativeCost="1.0"
-Depsilon="0.001";PAI命令中的参数详情如下表所示。
参数名称 | 是否必选 | 描述 | 默认值 |
inputTableName | 是 | 输入表的名称。 | 无 |
inputTableParitions | 否 | 输入表中,参与训练的分区。系统支持以下格式:
说明 指定多个分区时,分区之间使用英文逗号(,)分隔。 | 输入表的所有分区 |
modelName | 是 | 输出的模型名称。 | 无 |
featureColNames | 是 | 输入表中,用于训练的特征列名。 | 无 |
labelColName | 是 | 输入表中,标签列的名称。 | 无 |
positiveLabel | 否 | 正例的值。 | 从label取值中,随机选择一个。 |
positiveCost | 否 | 正例权重值,即正例惩罚因子。取值范围为(0, +∞)。 | 1.0 |
negativeCost | 否 | 负例权重值,即负例惩罚因子。取值范围为(0, +∞)。 | 1.0 |
epsilon | 否 | 收敛系数,取值范围为(0,1)。 | 0.001 |
enableSparse | 否 | 输入数据是否为稀疏格式,取值为true或false。 | false |
itemDelimiter | 否 | 当输入表数据为稀疏格式时,KV对之间的分隔符。 | 英文逗号(,) |
kvDelimiter | 否 | 当输入表数据为稀疏格式时,key和value之间的分隔符。 | 英文冒号(:) |
coreNum | 否 | 计算的核心数,取值范围为正整数。 | 系统自动分配 |
memSizePerCore | 否 | 每个核心的内存,取值范围为1 MB~65536 MB。 | 系统自动分配 |
示例
导入如下训练数据。
id
y
f0
f1
f2
f3
f4
f5
f6
f7
1
-1
-0.294118
0.487437
0.180328
-0.292929
-1
0.00149028
-0.53117
-0.0333333
2
+1
-0.882353
-0.145729
0.0819672
-0.414141
-1
-0.207153
-0.766866
-0.666667
3
-1
-0.0588235
0.839196
0.0491803
-1
-1
-0.305514
-0.492741
-0.633333
4
+1
-0.882353
-0.105528
0.0819672
-0.535354
-0.777778
-0.162444
-0.923997
-1
5
-1
-1
0.376884
-0.344262
-0.292929
-0.602837
0.28465
0.887276
-0.6
6
+1
-0.411765
0.165829
0.213115
-1
-1
-0.23696
-0.894962
-0.7
7
-1
-0.647059
-0.21608
-0.180328
-0.353535
-0.791962
-0.0760059
-0.854825
-0.833333
8
+1
0.176471
0.155779
-1
-1
-1
0.052161
-0.952178
-0.733333
9
-1
-0.764706
0.979899
0.147541
-0.0909091
0.283688
-0.0909091
-0.931682
0.0666667
10
-1
-0.0588235
0.256281
0.57377
-1
-1
-1
-0.868488
0.1
导入如下测试数据。
id
y
f0
f1
f2
f3
f4
f5
f6
f7
1
+1
-0.882353
0.0854271
0.442623
-0.616162
-1
-0.19225
-0.725021
-0.9
2
+1
-0.294118
-0.0351759
-1
-1
-1
-0.293592
-0.904355
-0.766667
3
+1
-0.882353
0.246231
0.213115
-0.272727
-1
-0.171386
-0.981213
-0.7
4
-1
-0.176471
0.507538
0.278689
-0.414141
-0.702128
0.0491804
-0.475662
0.1
5
-1
-0.529412
0.839196
-1
-1
-1
-0.153502
-0.885568
-0.5
6
+1
-0.882353
0.246231
-0.0163934
-0.353535
-1
0.0670641
-0.627669
-1
7
-1
-0.882353
0.819095
0.278689
-0.151515
-0.307329
0.19225
0.00768574
-0.966667
8
+1
-0.882353
-0.0753769
0.0163934
-0.494949
-0.903073
-0.418778
-0.654996
-0.866667
9
+1
-1
0.527638
0.344262
-0.212121
-0.356974
0.23696
-0.836038
-0.8
10
+1
-0.882353
0.115578
0.0163934
-0.737374
-0.56974
-0.28465
-0.948762
-0.933333
创建如下实验,详情请参见算法建模。
配置线性支持向量机组件的参数(配置如下表格中的参数,其余参数使用默认值)。
页签
参数
描述
字段设置
特征列
选择f0、f1、f2、f3、f4、f5、f6及f7列。
标签列
选择y列。
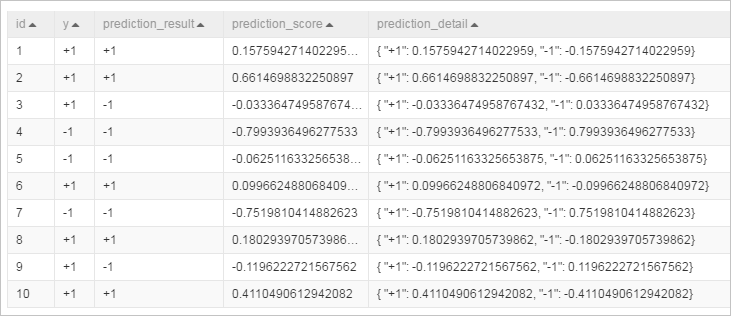
运行实验,查看预测结果。
- 本页导读 (1)