本文介绍了时序表的索引机制,以及查询时序表的最佳实践。
背景信息
时序数据的模型请参见如何设计时序数据表,数据是按照时间序列来进行组织的。所以在时序数据表中,所有标记TAG的列(标签列)会被建立为索引列,来表示每一条数据具体所属于哪个时间序列,从而显示数据的来源。
以时序数据表为例,具体请参见如何设计时序数据表,这些数据都属于同一个时间序列,如下图所示。

如果标签列的值发生变化,则数据将属于不同的时间序列。通常情况下,一个时间序列可以标记一个产生时序数据的数据源。
时序引擎会根据每个标签列建立索引,其索引形态是倒排索引,以标签列的列名和值作为索引键来索引所有拥有该键值对的时间序列,用于从时间序列维度快速定位某个标签对应的数据范围。随着数据的不断写入,时序数据表的倒排索引将会呈现以下形态。

对于时间戳列,时序引擎会默认建立数据块范围索引,确保在海量时序数据中快速定位到需要查询的数据范围。但对于普通的Field列,时序引擎不会对数据建立索引。
使用建议
结合时序引擎的内部索引机制,对Lindorm时序引擎的时序表进行查询时需要考虑以下几点:
建议在查询的条件语句中增加标签列的等值过滤条件语句和时间戳列的过滤条件语句,避免条件语句中只有Field列过滤语句。
查询的条件语句中如果包含多个标签列过滤条件,且这几个标签列映射的时间线范围存在包含关系,建议只需要保留选择区分度最高的标签列的过滤条件(例如上图中的id列相对city列选择区分度更高)。
查询条件覆盖的时间范围过大可能会导致扫描过多的数据,进而导致查询速度过慢,在这种情况下建议您可以缩小时间戳列的过滤范围来提高查询性能。
常见的时序查询场景和查询操作
如果需要复现以下查询场景的结果,请下载相应的SQL脚本语句填写样例数据。
查询时间范围内的原始点
使用以下语句查询余杭区内设备从2019-04-18 10:00:00至2019-04-18 10:30:00上报的全部SO2监控指标。
SELECT id, so2 FROM aqm WHERE district='yuhang' AND time >= '2019-04-18 10:00:00' AND time < '2019-04-18 10:30:00';查询结果如下。
查询时序数据表中特定标签列的所有标签值
当将许多同类设备上报的数据接入到一张时序数据表中之后,有时会需要查询接入设备的某个标签的标签值。例如下述SQL就可以查询时序数据表 aqm 中接入的所有空气质量监控设备的设备id:
SELECT DISTINCT(id) FROM aqm;查询结果如下。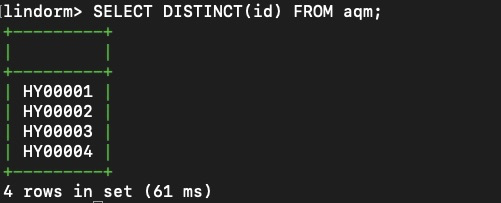
对于标签列的查询在存储引擎层面默认会基于标签索引进行查询,因此无需担心这样的查询会走全表扫描而产生性能问题。但若已接入的设备量非常多时,即使是走标签索引其查询耗时也可能会较长。
查询时间精度的降采样
查询余杭区内设备从2019-04-18 10:00:00至2019-04-18 10:30:00上报的PM2.5和SO2监控指标,按5分钟为粒度求平均值。
SELECT id, time, avg(pm2_5) AS avg_pm2_5, avg(so2) AS avg_so2 FROM aqm WHERE district='yuhang' AND time >= '2019-04-18 10:00:00' AND time < '2019-04-18 10:30:00' SAMPLE BY 5m;查询结果如下。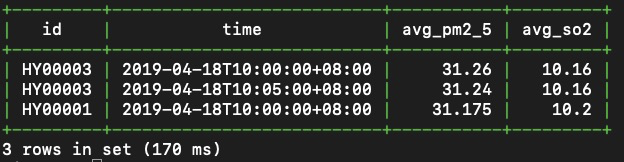
降采样的实质是以时间序列为单位在时间维度的聚合。关于降采样查询的详细说明请参见 降采样。
查询跨设备的聚合数据
查询余杭区内设备从2019-04-18 10:00:00至2019-04-18 10:30:00上报的PM2.5和SO2监控指标,查询按照5分钟粒度的最大平均值。
SELECT max(avg_pm2_5) AS max_avg_pm25, max(avg_so2) AS max_avg_so2 FROM (SELECT district, id, time, avg(pm2_5) AS avg_pm2_5, avg(so2) AS avg_so2 FROM aqm WHERE district='yuhang' AND time >= '2019-04-18 10:00:00' AND time < '2019-04-18 10:30:00' SAMPLE BY 5m) GROUP BY district;查询结果如下。
- 本页导读 (1)