阿里云E-MapReduce(简称EMR) on ACK提供了全新构建大数据平台的方式。您可以将开源大数据服务部署在阿里云容器服务Kubernetes版(ACK)之上,利用ACK在服务部署和容器应用管理的优势,减少对底层集群资源的运维投入,以便于您可以更加专注大数据任务本身。
形态对比
阿里云EMR提供on ECS和on ACK两种方式,以满足不同用户的需求。
对于正在使用EMR on ECS的用户,可以将Spark和Presto任务运行在ACK集群上,与其他应用共享一个ACK集群,可以实现计算资源跨可用区共享。
对于已经将大数据任务(例如,Spark和Presto等)执行在ACK集群上的用户,EMR on ACK提供了自动部署和管理集群的能力。EMR on ACK与EMR Shuffle Service相结合,可以显著提升Spark任务的性能。
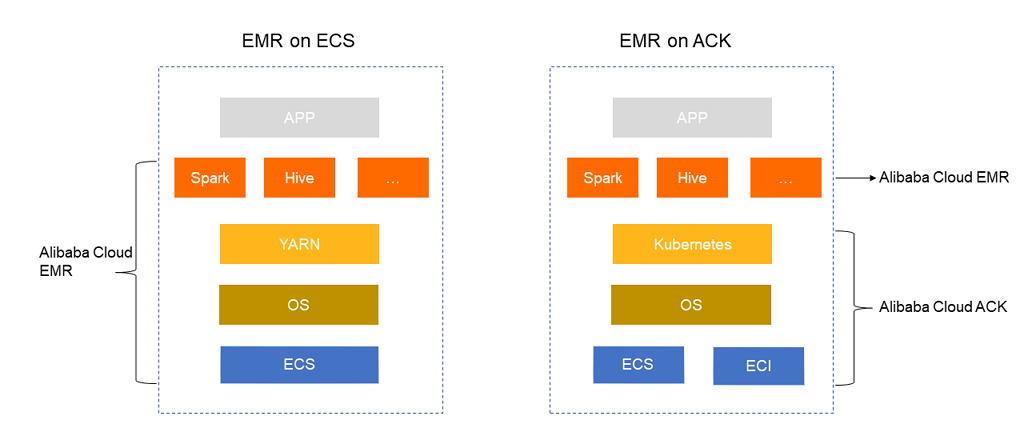
形态 | 描述 |
EMR on ECS | EMR负责将开源Hadoop生态的组件安装部署在ECS上,并启动相应的服务。您可以在EMR控制台完成对集群ECS及服务的运维操作。 您需要将其大数据任务提交至EMR集群。 |
EMR on ACK | 您需要先完成ACK集群的安装部署。当ACK集群准备就绪后,EMR将基于ACK的资源安装部署大数据服务组件,并在容器内运行。 |
EMR on ACK优势
优势 | 描述 |
节省成本 | 您无需为大数据服务单独购买ACK集群,通过简单的配置即可在已有的ACK集群上执行大数据作业,成本低廉。 复用现有ACK集群的空闲资源,一键执行EMR Spark和Presto等任务,轻松上手。大数据和在线应用程序可以共享集群资源。 离在线混部(在线任务和离线任务)场景下,资源可以充分利用。大数据和在线应用程序共享集群资源,达到削峰填谷的效果。 |
简化运维 | 一套运维体系,一套集群管理,全面覆盖大数据和在线等多种业务,简化运维。 |
优化体验 | 一套EMR平台,同时支持ECS和ACK两套IaaS资源模型,您可以无缝切换。 利用ACK和弹性容器实例ECI的资源快速交付能力,弹性计算资源的获取时间更短,充分应对计算高峰期。 支持针对作业级别调整Spark版本,便于快速尝试新特性,以满足不同业务对版本的需求。 |
深度集成 | 完全采用云原生数据湖架构,计算使用阿里云ACK,计算资源可以无限扩展;存储使用阿里云OSS,存储计算分离;元数据使用数据湖构建DLF,助力数据湖构建。 |
- 本页导读 (1)