Lindorm宽表支持Tabular模型下的二级索引功能,此功能在非主键匹配的查询场景下,可以降低应用的开发复杂性、保证数据的一致性和提高写入效率。本文介绍Lindorm Tabular模型下二级索引的基本特性和使用示例。
背景信息
对于Lindorm Tabular模型,Lindorm宽表有表结构且表对应的列有类型预定义的。Lindorm原生二级索引功能在阿里云应用多年,经历了多次双11的考验,更加适用于解决海量数据的全局索引。Lindorm与Phoenix在索引场景下的性能对比如下图所示。
读写RT对比
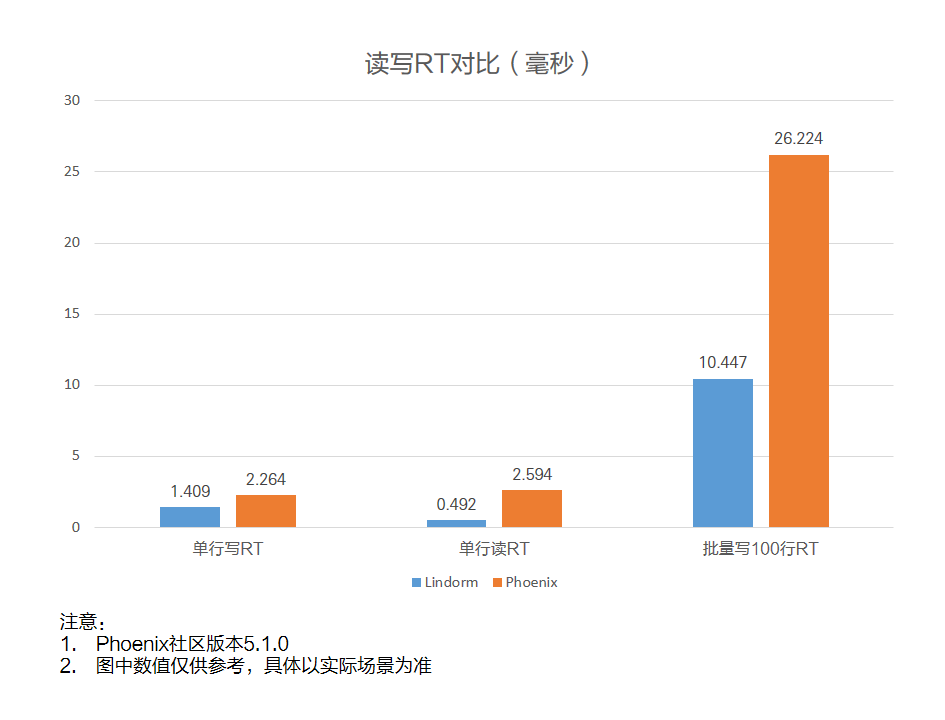
产品
单行写RT
单行读RT
批量写100行RT
Lindorm
1.409
0.492
10.447
开源Phoenix
2.264
2.594
26.224
可以看出,在索引场景下Lindorm进行读写操作耗时更少。单行写RT用时约为开源Phoenix的62%,单行读RT用时约为开源Phoenix的19%,批量写100行RT约为开源Phoenix的40%。
写吞吐对比
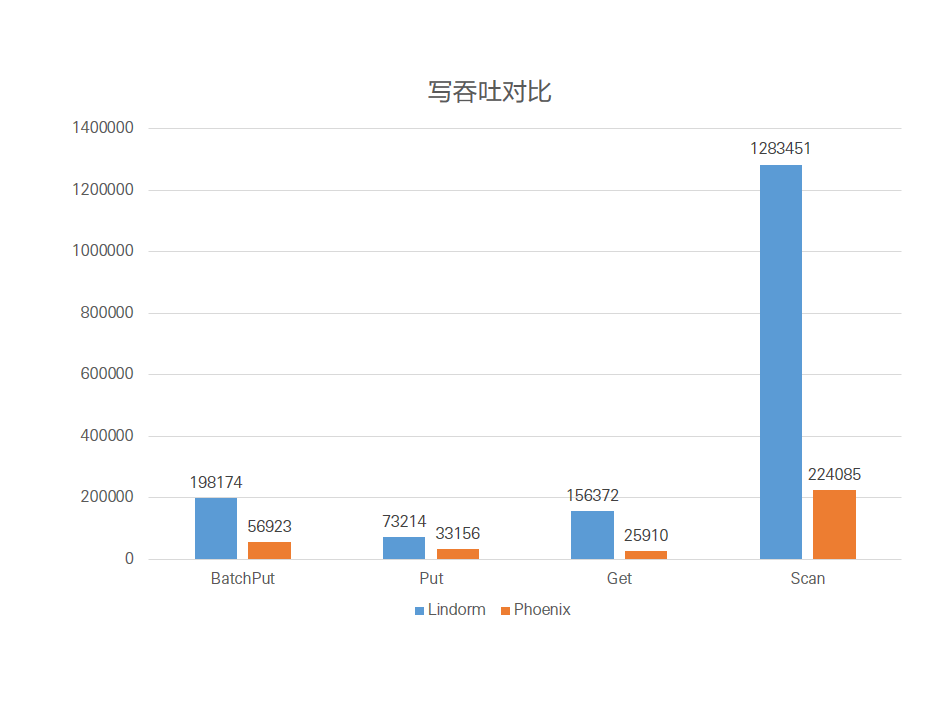
产品
BatchPut
Put
Get
Scan
Lindorm
198174
73214
156372
1283451
开源Phoenix
56923
33156
25910
224085
可以看出,在索引场景下Lindorm的BatchPut约为开源Phoenix的3.5倍,Put约为开源Phoenix的2.2倍,Get约为开源Phoenix的6倍,Scan约为开源Phoenix的5.7倍。
特性介绍
Lindorm二级索引支持为单表建多个索引,每个索引在物理上映射为一张数据表,与主表相互独立,每个索引有不同的存储策略(如采用不同的压缩算法、冷热分离策略)等属性。写主表时,Lindorm会自动更新所有索引表,并确保主表和索引表数据的一致性。读数据时,您只需针对主表发起查询,Lindorm会根据WHERE条件和SCHEMA自动选择合适的索引(包括主表)执行查询操作(支持HINT来干预优化器行为)。Lindorm二级索引的基本特性如下。
支持单个主表建多个索引。
支持组合索引(单列和多列)。
支持冗余索引,全冗余索引可自动冗余主表新增的列。
查询优化:根据WHERE语句自动选择索引,支持HINT来干预优化器的选择。
Online Schema Change:索引变更不影响主表的正常读写,可以随时新增、删除、更新索引。
支持数据有效期(简称:TTL):索引表自动继承主表的TTL设置,主表和索引表数据同时过期。
支持动态列:支持写入动态列和冗余动态列。
支持自定义数据版本:自定义时间戳后自动写入数据。
使用要求
服务器:使用Lindorm实例。
客户端:更多信息,请参见通过Lindorm宽表SQL使用宽表引擎。
Lindorm-Cli客户端:更多信息,请参见通过Lindorm-cli连接并使用宽表引擎。
基本概念
强一致性:是指主表和索引表的数据一致性。为了满足数据一致性的需求,最大程度减少二级索引的额外开销,提升高吞吐的写入能力,Lindorm二级索引在强一致性中具有如下约束。
不支持快照隔离性。在数据写入过程中不保证同时可见,但是返回客户端写入成功后主表和索引表数据可见。
在返回客户端超时或IO出错情况下,该数据在主表和索引表中不保证可见,但最终主表和索引表数据会保持一致。
可选的索引组织成本:在主表有一个索引的情况下,写放大有四次操作(读主表,删除索引老数据,写索引,写主表),会大大增加维护索引的成本。但不是所有场景都会产生写放大,比如日志场景只有数据插入没有更新操作,此时索引表不存在老数据,只需要做写索引和写主表操作。所以Lindorm提出了Mutability的概念。Mutability是指对主表的写入模式进行分类,并以此组织索引数据,针对不同的需求实现最低的索引组织成本。Mutability分类和描述如下表所示。Mutability属性需要在创建表或修改表时通过Table_Options参数进行设置,具体操作,请参见CREATE TABLE语法介绍。
Mutability分类
约束
操作成本
操作说明
无索引
无。
1
没有索引的情况下,直接写主表,为1次操作。
IMMUTABLE
整行写入,不可更新或删除。
2
写主表,写索引表。所有场景中成本最低,性能最好。
IMMUTABLE_ROWS
整行写入,不可更新,删除。
2~3
正常写入时:写主表,写索引表。在删除场景下需额外读一次主表。性能仅次于IMMUTABLE。
MUTABLE_LATEST
可更新,可删除。
4
读主表,删索引,写索引,写主表。
MUTABLE_ALL
无限制,可使用自定义时间戳写入。
4
读主表,删索引,写索引,写主表。
说明IMMUTABLE和IMMUTABLE_ROWS不涉及数据更新,无写放大问题,成本最低。适合高吞吐写的场景,如日志、监控等。
IMMUTABLE不涉及删除,所以可充分利用Lindorm的多IDC部署,实现多活的数据访问。
选择两类IMMUTABLE可以有效降低索引场景下的写时延,提高整体吞吐。实际的业务中,如果不满足IMMUTABLE场景,可以通过数据冗余来改造成IMMUTABLE场景。
更新自定义时间戳的索引:Lindorm支持自定义时间戳进行写入,可以在任意时间戳进行数据更新,由系统来判断只有时间戳最大的数据生效。自定义时间戳特性在控制数据有效期、乱序、幂等等场景中发挥着重要的作用,在HBase中有广泛的应用。Lindorm支持列级时间戳,主表支持自定义时间戳写入数据。但在支持二级索引和时间戳的NoSQL系统中,支持自定义时间戳索引更新的,就比较罕见了。因为时间戳乱序写入很难有效维护索引数据的更新和删除。Lindorm全局二级索引解决了这个问题,支持列级别自定义时间戳更新。下面是两个使用自定义时间戳的实际业务场景。
导入与实时并存:在需要同时实时更新和历史数据导入的场景下,实时更新可以使用当前时间,而历史数据导入可以使用昨天23:59:59这个时间。所以当天未更新过的数据可以通过导入操作而更新,已更新过的数据也不会被导入覆盖。
追消息:业务系统通过消息来触发一系列处理逻辑,在消息出现积压时,系统可以跳过积压的消息,直接处理当前消息,并在事后通过追消息来处理之前积压的任务。或者,当业务逻辑有问题时,系统也可以跳过一部分消息来规避问题,在业务修复后重新处理。此时,业务可以通过使用消息本身的时间来写入数据,以此来保证追的消息和正常消息的准确覆盖关系。
全冗余索引:为了避免查询索引之后再回查主表,通常会在索引表中冗余一部分主表列,也称为冗余索引或覆盖索引。全冗余索引是比较常用的冗余方案。Lindorm支持三种冗余模式,可以在主表Schema变化以及动态列场景下简单的实现全冗余索引。
冗余指定的列:显式指定要冗余主表的哪些列。
冗余主表Schema中的所有列:当您需要全冗余索引时,不需要在CREATE INDEX中将主表的每一列都显式添加进来,而是通过一个常量来描述冗余所有列,当主表新增列时,全冗余索引表会自动冗余这个新增列,无需重建索引。也无需担心新增列的查询会导致回查主表了。
冗余动态列:Lindorm支持固定Schema和松散Schema(即动态列)。通过DYNAMIC冗余模式,索引表能够自动冗余主表中的所有动态列,也会冗余主表Schema中的所有列。
语法参考
二级索引的语法详细说明,请参见以下文档:
创建二级索引:CREATE INDEX。
修改二级索引:ALTER INDEX。
查看二级索引:SHOW INDEX。
构建二级索引:BUILD INDEX。
删除二级索引:DROP INDEX
创建二级索引
创建完Lindorm主表后,可以为主表的相应列创建二级索引。以下是创建二级索引的示例。
-- 创建主表
create table shop_item_relation (
shop_id varchar,
item_id varchar,
status varchar,
constraint pk primary key(shop_id, item_id)) ;
-- 对第二列主键建索引,冗余所有列
create index idxs1 on shop_item_relation (item_id) 'INDEX_COVERED_TYPE'='COVERED_ALL_COLUMNS_IN_SCHEMA';
-- 基于索引表进行查询,因为对item_id构建索引,当指定item_id 进行查询会对应命中索引表
select * from shop_item_relation where item_id = 'item2'; 创建索引有同步创建和异步创建两种方式,在存量数据不大的情况下,可以使用同步创建。其他情况下可以使用异步创建。具体的语法请参见CREATE INDEX。
在已有数据的表中添加新的索引时,CREATE_INDEX命令会同时将主表的历史数据同步到索引表中,如果主表很大时,CREATE_INDEX会非常耗时间(数据同步任务是在服务端执行的,即使删除Lindorm Shell进程也不会影响数据同步任务)。
查看二级索引
通过Lindorm宽表SQL可以查看创建的二级索引状态。以下是查看二级索引的示例。
show index from shop_item_relation;通过示例可以展示出shop_item_relation主表下创建的索引名和索引类型。
修改二级索引状态
创建完二级索引后,如果主表有存量数据,需要手动对索引进行一次Rebuild操作,具体语法请参见BUILD INDEX;若主表没有存量数据,则可以直接使用修改二级索引语法来修改二级索引表状态。以下是修改二级索引状态的示例:
alter index idxs1 on shop_item_relation ACTIVE;
alter index idxs1 on shop_item_relation DISABLED;当二级索引状态为DISABLED时,直接修改为ACTIVE状态会导致数据缺失,因此修改前需要进行一次Rebuild操作。
删除二级索引
通过以下示例删除对应主表中的相关二级索引。
drop index idxs1 on shop_item_relation;删除索引操作需要您有Trash权限。
查询优化
Lindorm依据RBO(Rule Based Optimization)策略进行二级索引选择。根据查询条件匹配索引表的前缀,选择匹配程度最高的索引表作为本次查询使用的索引。通过以下示例可以更好的理解。
-- 主表和索引表如下
create table dt (rowkey varchar, c1 varchar, c2 varchar, c3 varchar, c4 varchar, c5 varchar, constraint pk primary key(rowkey));
create index idx1 on dt (c1);
create index idx2 on dt (c2, c3, c4);
create index idx3 on dt (c3) include (c1, c2, c4);
create index idx4 on dt (c5) 'INDEX_COVERED_TYPE'='COVERED_ALL_COLUMNS_IN_SCHEMA';
-- 查询优化如下
select rowkey from dt where c1 = 'a';
select rowkey from dt where c2 = 'b' and c4 = 'd';
select * from dt where c2 = 'b' and c3 >= 'c' and c3 < 'f';
select * from dt where c5 = 'c';select rowkey from dt where c1 = 'a'表示选择索引表idx1。
select rowkey from dt where c2 = 'b' and c4 = 'd'表示选择索引表idx2,从中查找所有满足c2=b条件的行,然后逐行按c4=d进行过滤。虽然c4是索引列之一,但因WHERE条件中缺少c3列,无法匹配idx2的前缀。
select * from dt where c2 = 'b' and c3 >= 'c' and c3 < 'f'表示选择索引表idx2,由于是select *,而索引表里并未包含主表的所有列,因此在查询索引之后,还要回查一次主表。回查主表时,回查的Rowkey可能散布在主表的各个地方,因此,可能会消耗多次RPC。回查的数据量越大,RT越长。
select * from dt where c5 = 'c'表示选择索引表idx4,idx4是全冗余索引,所以select *不需要回查主表。
使用限制
不同主表可以有同名索引,如dt表有索引Idx1,foo表也有索引Idx1,但同一主表下不允许有同名索引。
只能为Version为1的表建索引,不支持为多版本的表建索引。
对有TTL的主表建索引,不能单独为索引表设置TTL,索引表会自动继承主表的TTL。
索引列最多不超过3个。
索引列和主表主键,总长度不能超过30 KB。不建议使用大于100字节的列作为索引列。
单个主表的索引表个数最多不超过5个,过多索引会造成存储成本过高,以及写入耗时过长。
一次查询最多能命中一个索引,不支持多索引联合查询(Index Merge Query)。
创建索引时会将主表的数据同步到索引中,对数据多的表建索引会导致Create_Index命令耗时过长。
二级索引不支持batch increase功能。
命中二级索引的排序与主表不一样。
仅支持为通过SQL或API写入的数据构建二级索引,不支持为Bulkload(批量导入)至Lindorm的数据构建二级索引。
问题答疑
对于索引使用上的任何问题,您可以通过钉钉联系云Lindorm答疑或工单咨询,具体操作,请参见技术支持。
- 本页导读 (1)