通过DataWorks控制台,您可以在MaxCompute中使用merge_udf.jar包将表格存储的增量数据转换为全量数据格式。
前提条件
已导出表格存储全量数据到MaxCompute,且已配置同步表格存储增量数据到MaxCompute。具体操作,请分别参见全量导出和增量同步。
已下载merge_udf.jar包。具体下载路径请参见merge_udf.jar。
注意事项
字段名称大小写敏感,请确保MaxComputer中的字段名称与表格存储中的字段名称一致。
步骤一:新建JAR资源
通过新建JAR资源,将下载的merge_udf.jar包上传到MaxCompute中。
进入数据开发页面。
以项目管理员身份登录DataWorks控制台。
说明仅项目管理员角色可以新增数据源,其他角色的成员仅可查看数据源。
在左侧导航栏,单击工作空间列表后,选择地域。
在工作空间列表页面,在目标工作空间操作列选择快速进入>数据开发。
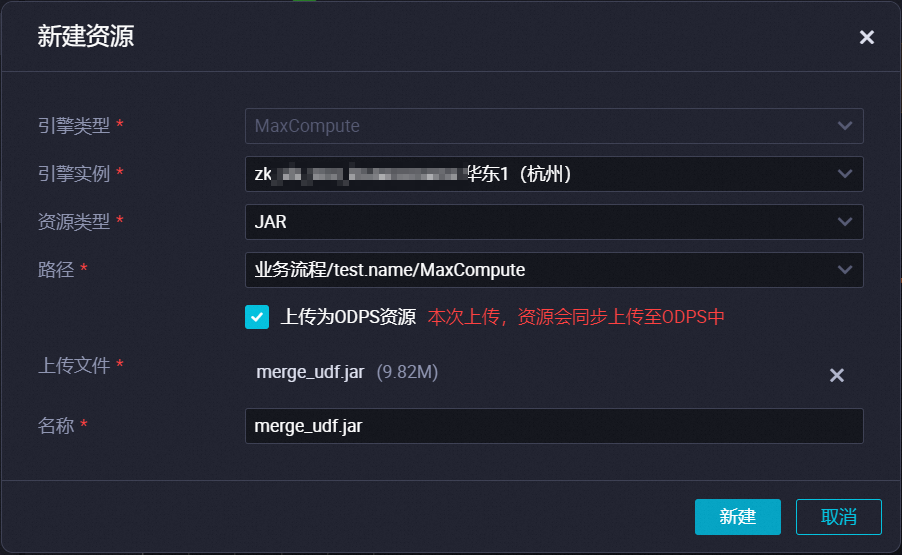
新建JAR资源。
在数据开发页面,将鼠标悬停在
 图标,选择新建资源>JAR。重要
图标,选择新建资源>JAR。重要只有在工作空间配置页面添加MaxCompute引擎后,当前页面才会显示MaxCompute节点。具体操作,请参见创建并管理工作空间。
您也可以打开相应的业务流程,右键单击MaxCompute,选择新建资源>JAR。
在新建资源对话框,选择路径并填写资源名称。
说明资源名称无需与上传的文件名保持一致,JAR资源的后缀必须为
.jar。如果该JAR包已经在MaxCompute(ODPS)客户端上传过,则需要取消选择上传为ODPS资源,否则上传会报错。
单击点击上传,选择相应文件进行上传。
单击新建。
在资源编辑页面,提交资源到调度开发服务器端。
单击工具栏中的
 图标。
图标。在提交对话框,填写变更描述。
单击确认。
步骤二:新建并注册函数
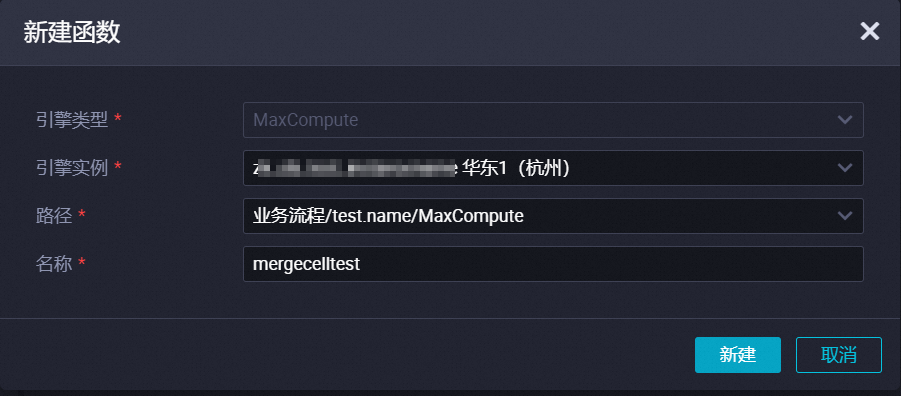
新建函数。
在数据开发页面,将鼠标悬停在
图标,选择新建函数>函数。您也可以打开相应的业务流程,右键单击MaxCompute,选择新建函数。
在新建函数对话框,选择路径并填写函数名称。
单击新建。
注册函数。
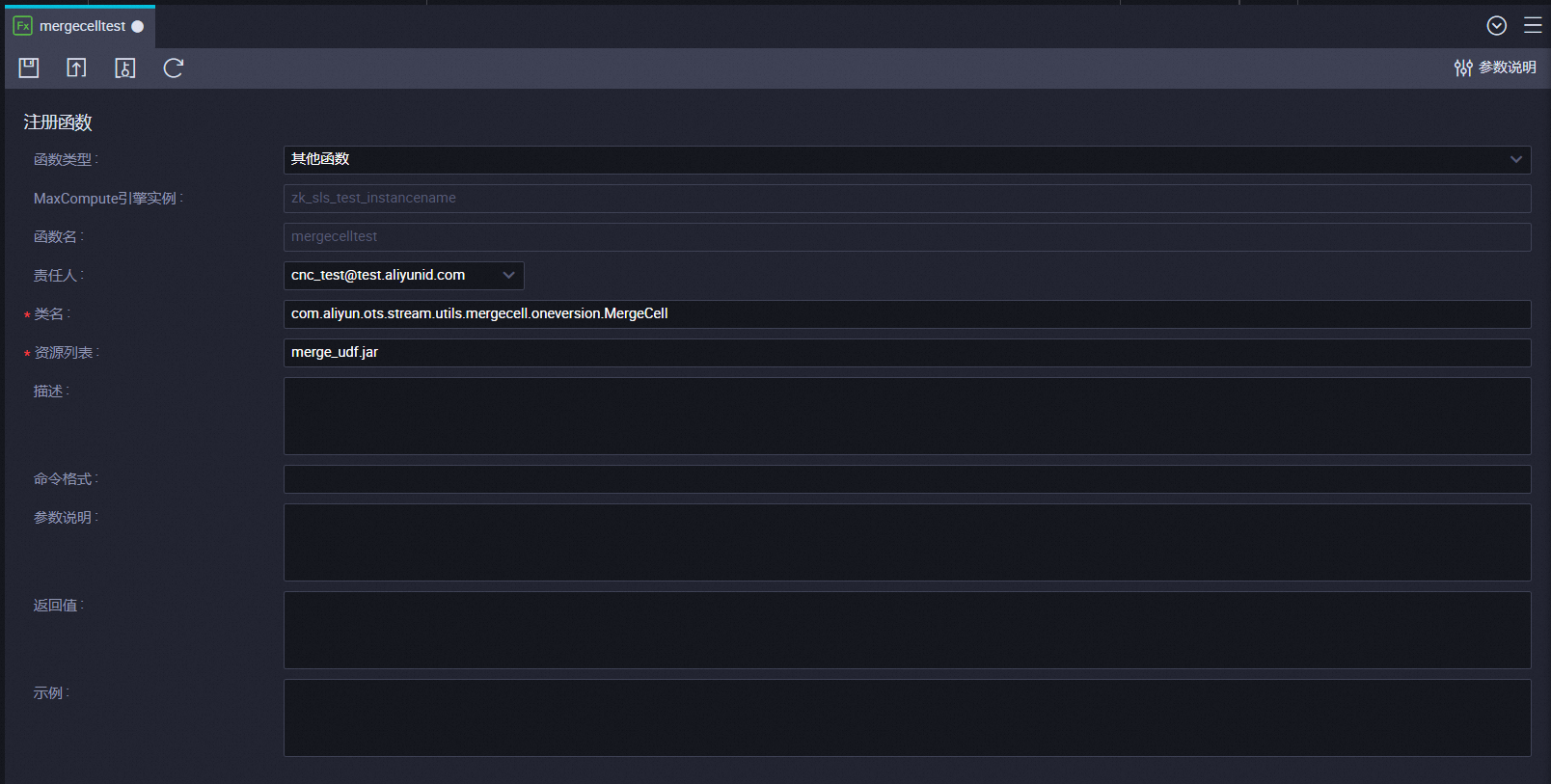
在注册函数页面,选择函数类型为其他函数。
填写资源列表为步骤一:新建JAR资源中的资源名称,并根据表类型和模式填写对应的类名。
根据表类型不同可以选择的模式不同,单版本表只能选择单版本模式,多版本表可以选择多版本模式V1或者多版本模式V2。关于模式选择的更多信息,请参见附录:模式选择。
表类型
模式
类名
单版本表
单版本模式
com.aliyun.ots.stream.utils.mergecell.oneversion.MergeCell
多版本表
多版本模式V1
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV1
多版本模式V2
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV2
单击
 图标,保存配置。
图标,保存配置。
在函数编辑页面,提交函数到调度开发服务器端。
单击工具栏中的
图标。在提交对话框,填写变更描述。
单击确认。
步骤三:编写ODPS SQL并运行
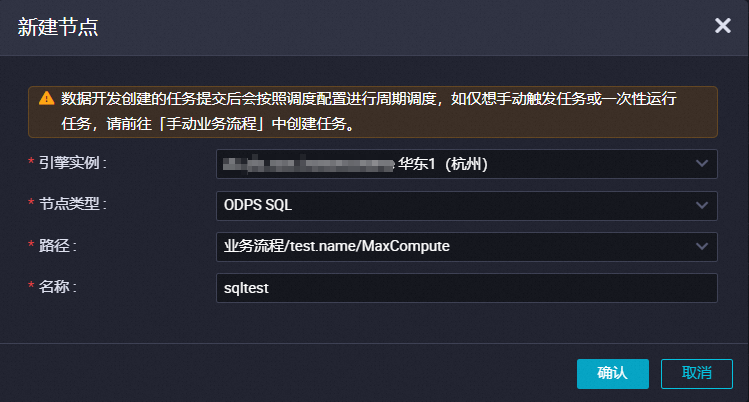
新建ODPS SQL节点。
在数据开发页面,将鼠标悬停在
图标,选择新建节点>ODPS SQL。您也可以打开相应的业务流程,右键单击MaxCompute,选择新建节点>ODPS SQL。
在新建节点对话框,选择路径并填写名称。
单击确认。
在节点编辑页面,编写ODPS SQL语句并执行。
ODPS SQL语句的语法如下:
select function_name(para_list) as (custom_para_list) from( select * from stream_table_name distribute by primary_keys sort by primary_keys,SequenceID )t;其中
function_name为步骤二:新建并注册函数中的函数名称,para_list为附录:模式选择中的参数列表,custom_para_list为自定义参数列表,stream_table_name为增量表的名称,primary_keys为表格存储数据表的主键列表,SequenceID为增量表的sequenceid。
附录:模式选择
模式包括单版本模式、多版本模式V1和多版本模式V2,请根据表类型选择合适的模式。
单版本模式
类名:com.aliyun.ots.stream.utils.mergecell.oneversion.MergeCell
参数列表
参数列表的格式为
pknum,colnum,colnames,pknames,colname,version,colvalue,optype,sequenceinfo。具体参数说明请参见下表,请根据实际填写pknum、colnum、colnames和pknames,其他参数保持参数名称即可。参数
类型
描述
INT pknum
常量
表格存储数据表的主键个数。
INT colnum
常量
表格存储数据表中的属性列个数。
List<String> colnames
常量
要合并增量变更的属性列名称。
List<String> pknames
变量
表格存储数据表的主键列表。
STRING colname
变量
属性列。
BIGINT version
变量
版本号。
STRING colvalue
变量
增量值。
STRING optype
变量
增量操作类型。
STRING sequenceinfo
变量
自增保序sequenceid。
示例
当表格存储数据表的主键为
pk1,pk2且属性列为col1,col2,col3时,则在MaxCompute中创建的增量表Schema为pk1,pk2,colname,version,colvalue,optype,sequenceinfo,如果要合并增量变更的属性列为col1,col2,col3,设置参数列表为2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo,ODPS SQL语句示例如下:select mergeCell(2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo) as (pk1,pk2,col1,col1_is_deleted,col2,col2_is_deleted,col3,col3_is_deleted) from( select * from stream_table_name distribute by pk1,pk2 sort by pk1,pk2,sequenceInfo )t;执行ODPS SQL语句后的输出结果请参见下表。
pk1
pk2
col1
co1_is_deleted
col2
col2_is_deleted
col3
col3_is_deleted
test
0
\N
\N
20
\N
\N
true
输出结果的说明如下:
当col列和col_is_deleted列均为
\N时,表示col列无任何增量操作。当col列为具体的值且col_is_deleted列为
\N时,表示col列的值被修改为对应值。当col列为
\N且col_is_deleted列为true时,表示col列被删除。
多版本模式V1
类名:com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV1
参数列表
参数列表的格式为
pknum,colnum,colnames,pknames,colname,version,colvalue,optype,sequenceinfo。具体参数说明请参见下表,请根据实际填写pknum、colnum、colnames和pknames,其他参数保持参数名称即可。参数
类型
描述
INT pknum
常量
表格存储数据表的主键个数。
INT colnum
常量
表格存储数据表中的属性列个数。
List<String> colnames
常量
要合并增量变更的属性列名称。
List<String> pknames
变量
表格存储数据表的主键列表。
STRING colname
变量
属性列。
BIGINT version
变量
版本号。
STRING colvalue
变量
增量值。
STRING optype
变量
增量操作类型。
STRING sequenceinfo
变量
自增保序sequenceid。
示例
当表格存储数据表的主键为
pk1,pk2且属性列为col1,col2,col3时,则在MaxCompute中创建的增量表Schema为pk1,pk2,colname,version,colvalue,optype,sequenceinfo,如果要合并增量变更的属性列为col1,col2,col3,设置参数列表为2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo,ODPS SQL语句示例如下:select mergeCell(2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo) as (pk1,pk2,version,col1,col1_is_deleted,col2,col2_is_deleted,col3,col3_is_deleted) from( select * from stream_table_name distribute by pk1,pk2 sort by pk1,pk2,sequenceinfo )t;执行ODPS SQL语句后的输出结果请参见下表。
pk1
pk2
version
col1
co1_is_deleted
col2
col2_is_deleted
col3
col3_is_deleted
test
0
123
\N
\N
20
\N
\N
true
输出结果的说明如下:
当version列为具体的值,且col列和col_is_deleted列均为
\N时,表示col列对应版本没有任何增量操作。当version列和col列均为具体的值,且col_is_deleted列为
\N时,表示col列对应版本的值被修改为具体的值。当version列为具体的值,col列为
\N,且col_is_deleted列为true时,表示col列对应版本被删除。当version列和col列均为
\N,且col_is_deleted列为true时,表示存在删除一列所有版本的操作。
多版本模式V2
类名:com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV2
参数列表
参数列表的格式为
pknum,colnum,maxversion,colnames,pknames,colname,version,colvalue,optype,sequenceinfo。具体参数说明请参见下表,请根据实际填写pknum、colnum、maxversion、colnames和pknames,其他参数保持参数名称即可。参数
类型
描述
BIGINT pknum
常量
表格存储数据表的主键个数。
BIGINT colnum
常量
表格存储数据表中的属性列个数。
BIGINT maxversion
常量
最大版本数。
List<String> colnames
常量
要合并增量变更的属性列名称。
List<String> pknames
变量
表格存储数据表的主键列表。
STRING colname
变量
属性列。
BIGINT version
变量
版本号。
STRING colvalue
变量
增量值。
STRING optype
变量
增量操作类型。
STRING sequenceinfo
变量
自增保序sequenceid。
示例
当表格存储数据表的主键为
pk1,pk2,属性列为col1,col2,col3且最大版本数为3时,则在MaxCompute中创建的增量表Schema为pk1,pk2,colname,version,colvalue,optype,sequenceinfo,如果要合并增量变更的属性列为col1,col2,col3,设置参数列表为2,3,3,"col1","col2","col3",pk1,pk2,colName,version,colValue,opType,sequenceInfo,ODPS SQL语句示例如下:select mergeCell(2,3,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,opyype,sequenceinfo) as (pk1,pk2,col1,col2,col3) from( select * from stream_table_name distribute by pk1,pk2 sort by pk1,pk2,sequenceinfo )t;执行ODPS SQL语句后的输出结果请参见下表。
pk1
pk2
col1
col2
col3
test
02
{"data":[{"version":1621330803390,"value":"value001"},{"version":1621330795198,"value":"value002"},{"version":1621330785936,"value":"value003"}],"needDeleteAllVersionFirst":true,"deleteVersions":[]}
\N
\N
输出结果的说明如下:
data表示新写入的数据列表,按照版本号降序排序。最多保留maxversion个版本的数据。
needDeleteAllVersionFirst表示该列是否需要删除原有全部版本。当出现删除一行DeleteRow或删除一列的所有版本DeleteColumns时,该值为true,否则为false。
deleteVersions表示该列需要删除的版本列表,按照版本号降序排序。最多保留maxversion个版本。
deleteVersions中的版本号不会与data中的版本号相同,当needDeleteAllVersionFirst为true时,deleteVersions为空列表。
常见问题
执行SQL语句进行表格存储数据格式转换时出现类型转换错误问题
问题现象
在DataWorks中通过数据开发执行SQL语句进行表格存储数据格式转换时出现如下错误:
FAILED ODPS -0010000:System internal error -fuxi job failed, causer by: Failed in UDF/UDTF/UDAF com.aliyun.otsstream.utils.mergecell.oneversion.MergeCell class, at query location of line 1, column 8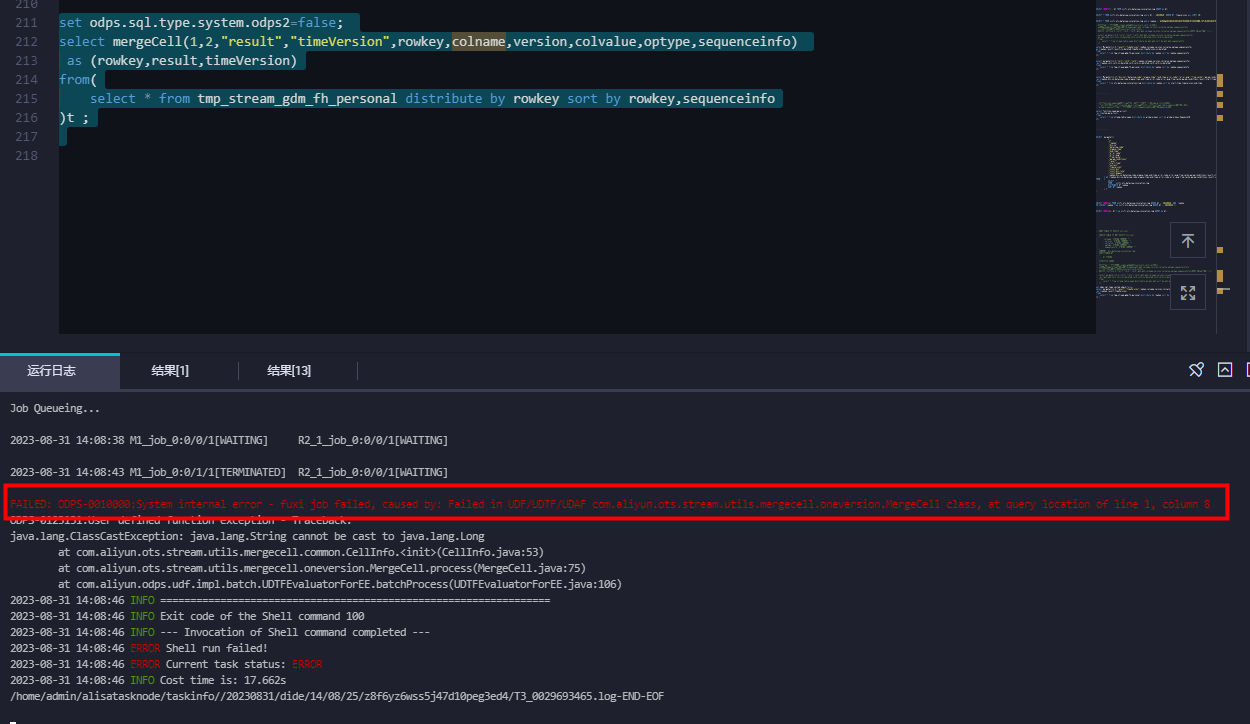
可能原因
odps.sql.type.system.odps2参数的配置不正确(即odps.sql.type.system.odps2=true)。解决方案
在该函数的SQL语句前加
set odps.sql.type.system.odps2=false;,并与SQL语句一起提交运行。
字段映射不到值且未查到值的字段均显示被删除
问题现象
执行数据转换SQL语句后,返回结果中存在字段映射不到值,且未查到值的字段均显示被删除。例如下图中name列值均为
\N且name_is_deleted列值均为True,表示name列被删除,但是实际表格存储中增量数据表中实际存在name列。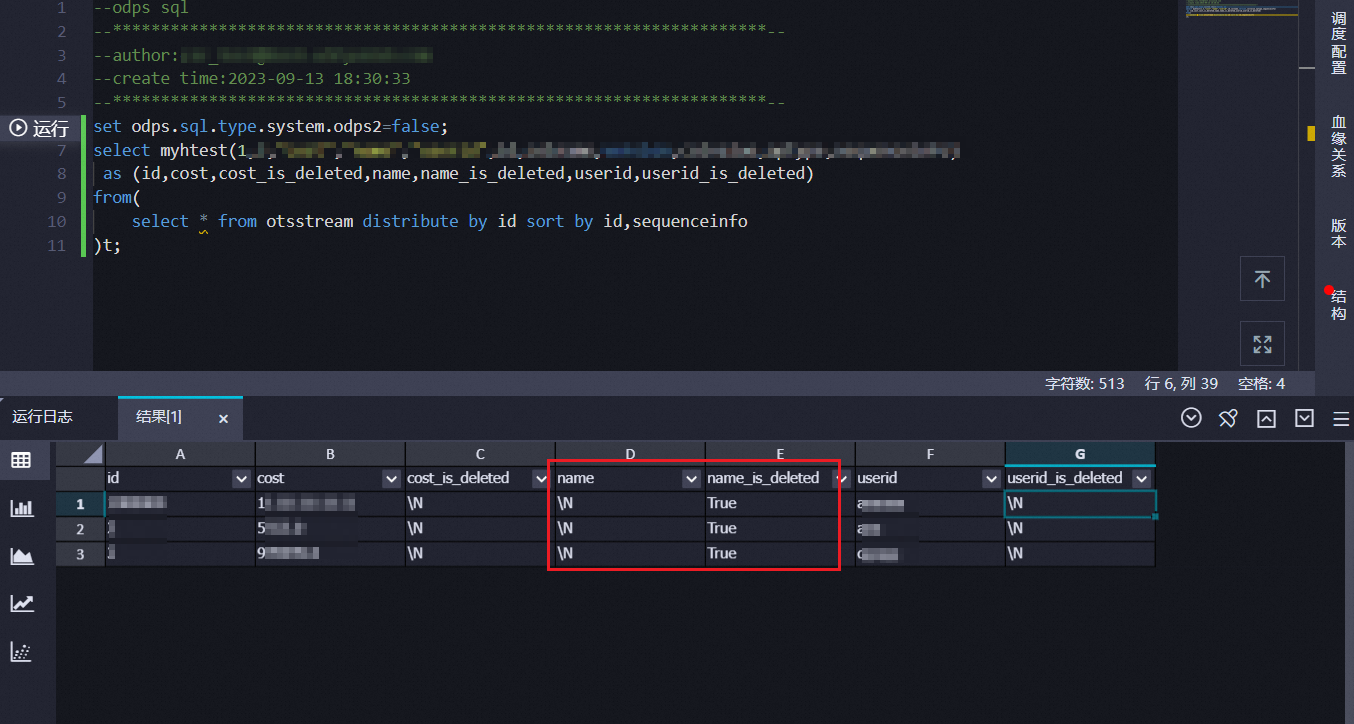
可能原因
增量同步任务中的isExportSequenceInfo参数配置不正确(即
"isExportSequenceInfo"=false),导致系统认为属性值已被删除。sequenceInfo中记录了某一列的历史版本信息,如果未导出sequenceInfo,则增量数据转为全量数据格式时,对应版本的值无法设置到行中。
解决方案
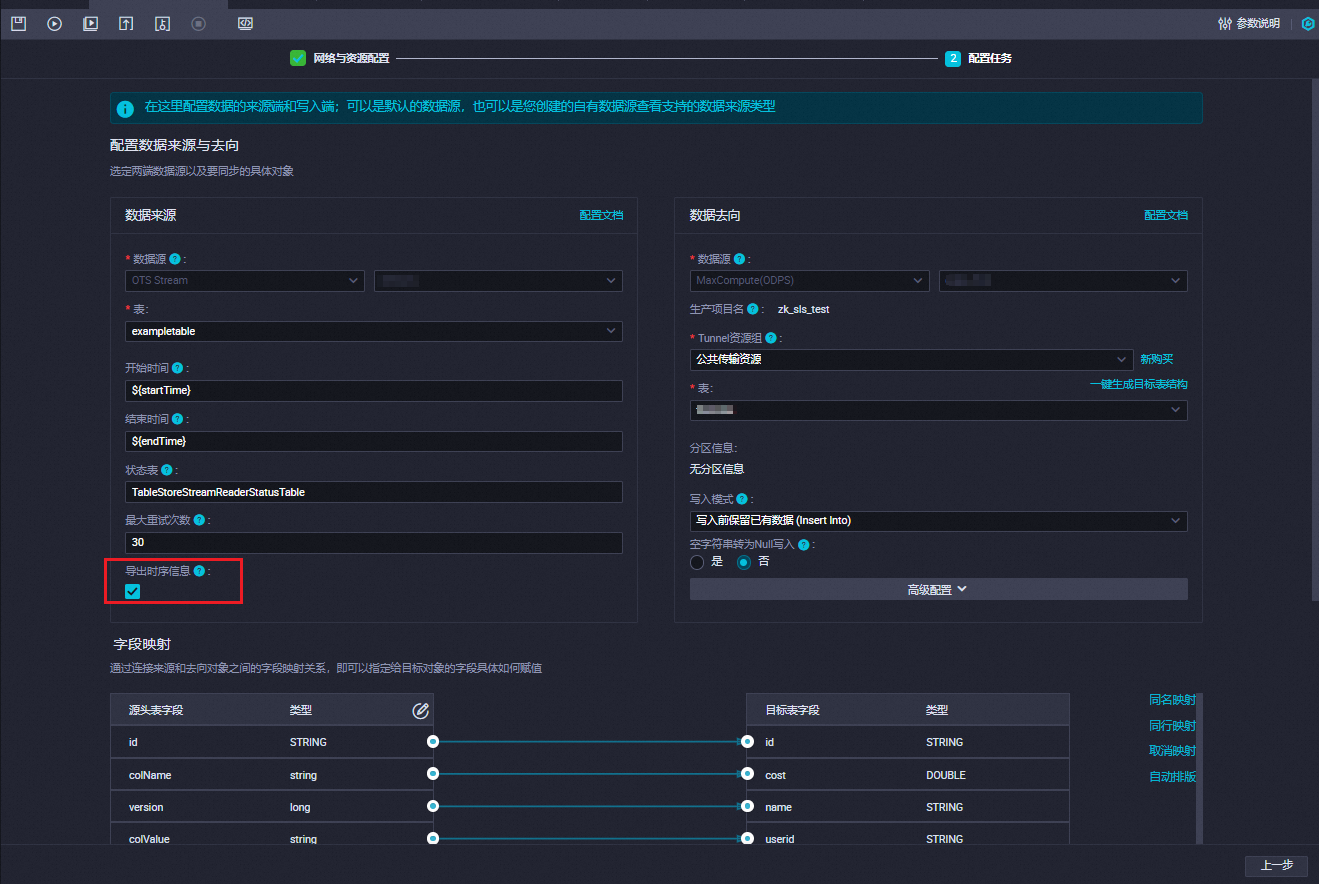
在同步任务中配置导出时序信息,然后重新执行同步数据并进行数据格式转换。
请选择合适方式进行导出时序信息配置。
通过DataWorks控制台在增量同步任务脚本编辑页面修改isExportSequenceInfo参数为true(即
"isExportSequenceInfo"=true),并保存和提交同步任务。通过DataWorks控制台在增量同步任务的配置任务步骤选中导出时序信息复选框,并保存和提交同步任务。
- 本页导读 (1)