基于开源库so-vits-svc生成AI歌手
learn
手动配置
65
教程简介
在本教程中,您将学习如何在阿里云交互式建模(PAI-DSW)中,基于so-vits-svc开源库端到端生成一个AI歌手。
在人工智能浪潮的推动下,技术的不断加持让虚拟人类愈发逼真。越来越多的虚拟人类被开发并应用于互联网中。技术使机器具备了人的特性,而人类也在追求智能化的道路上越走越远。使用人工智能克隆人类声音的场景已经不再仅限于荧屏之中。在今天,虚拟人类作为技术创新和文艺创作的结合体,让AI歌手成为了打开虚拟人与人世界的钥匙。本文将为您介绍如何生成一个AI歌手。AI歌手的效果演示如下:
目标人物声音:
歌曲原声:
换声后的效果:
我能学到什么
学会如何在DSW中训练模型。
学会如何在DSW中离线推理模型。
操作难度 | 中 |
所需时间 | 65分钟 |
使用的阿里云产品 | 阿里云在华北2(北京)、华东2(上海)、华东1(杭州)、华南1(深圳)地域为您提供了免费的PAI-DSW资源供您免费体验,您可根据需要选择对应地域申请试用,本教程以杭州地域为例。 【重要】:PAI-DSW免费资源包只适用于本教程中的PAI-DSW产品。如果您领取了PAI-DSW资源包后,使用了PAI-DSW及PAI的其他产品功能(如PAI-DLC、PAI-EAS等),PAI-DSW产品产生的费用由资源包抵扣,其他产品功能产生的费用无法抵扣,会产生对应的费用账单。 |
所需费用 | 0元 |
准备环境及资源
5
开始教程前,请按以下步骤准备环境和资源:
【重要】:PAI-DSW免费资源包只适用于本教程中的PAI-DSW产品。如果您领取了PAI-DSW资源包后,使用了PAI-DSW及PAI的其他产品功能(如PAI-DLC、PAI-EAS等),PAI-DSW产品产生的费用由资源包抵扣,其他产品功能产生的费用无法抵扣,会产生对应的费用账单。
访问阿里云免费试用。单击页面右上方的登录/注册按钮,并根据页面提示完成账号登录(已有阿里云账号)、账号注册(尚无阿里云账号)或实名认证(根据试用产品要求完成个人实名认证或企业实名认证)。
成功登录后,在产品类别下选择,在交互式建模PAI-DSW卡片上单击立即试用。
【说明】:如果您此前已申请过试用PAI的免费资源包,此时界面会提示为已试用,您可以直接单击已试用按钮,进入PAI的控制台。
在交互式建模PAI-DSW面板,勾选服务协议后,单击立即试用,进入免费开通页面。
【重要】以下几种情况可能产生额外费用。
使用了除免费资源类型外的计费资源类型:
您申请试用的是PAI-DSW免费资源包,但您创建的DSW实例使用的资源类型非阿里云免费试用提供的资源类型。当前可申请免费使用的资源类型有:ecs.gn6v-c8g1.2xlarge、ecs.g6.xlarge、ecs.gn7i-c8g1.2xlarge。
申请试用的免费资源包与使用的产品资源不对应:
您创建了DSW实例,但您申请试用的是DLC或EAS产品的免费资源包。您使用DSW产品产生的费用无法使用免费资源包抵扣,会产生后付费账单。
您申请试用的是DSW免费资源包,但您使用的产品是DLC或EAS。使用DLC和EAS产品产生的费用无法使用DSW免费资源包抵扣,会产生后付费账单。
免费额度用尽或超出试用期:
领取免费资源包后,请在免费额度和有效试用期内使用。如果免费额度用尽或试用期结束后,继续使用计算资源,会产生后付费账单。
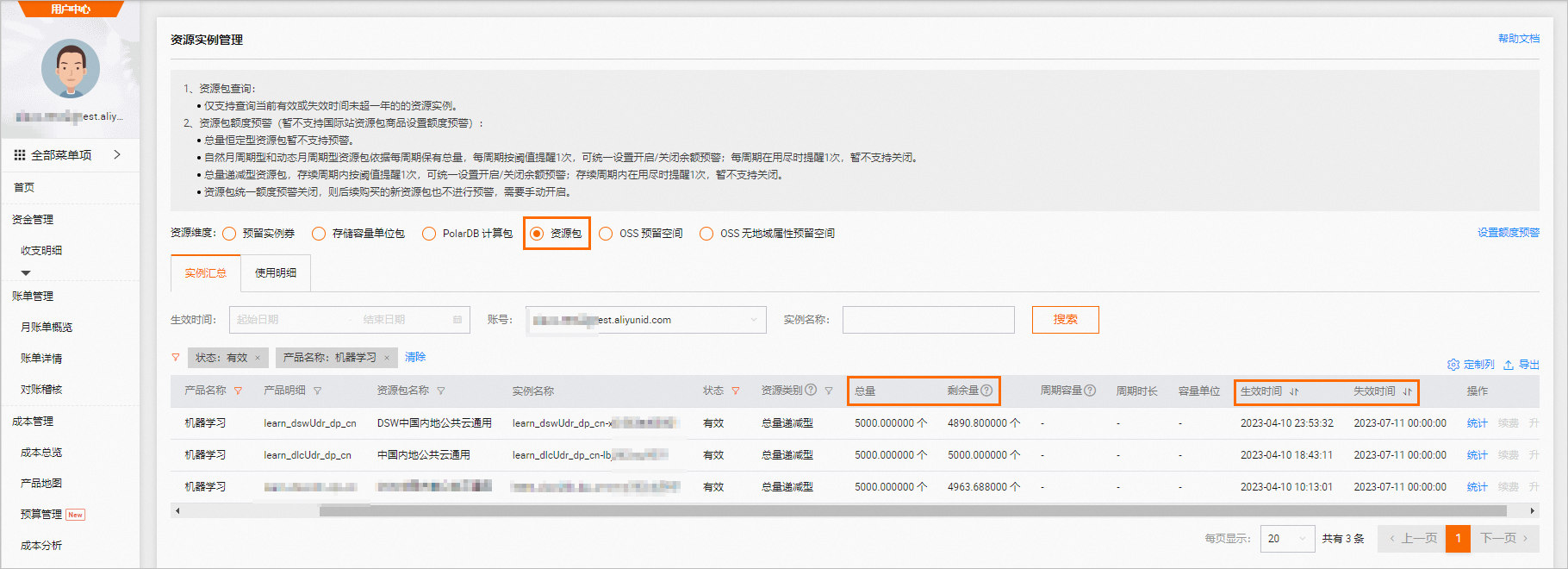
请前往资源实例管理页面,查看免费额度使用量和过期时间,如下图所示。
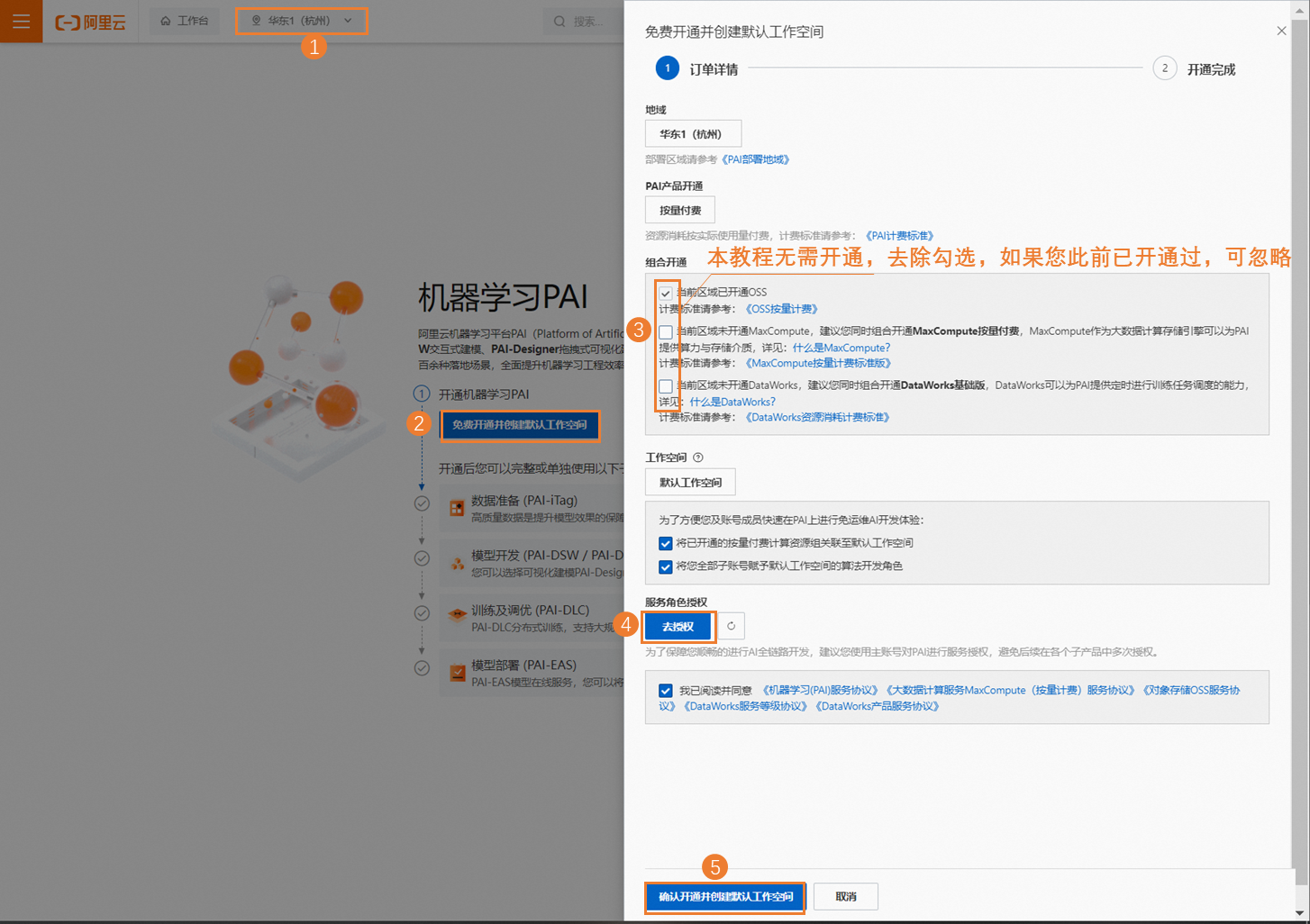
开通人工智能平台PAI并创建默认工作空间。其中关键参数配置如下,更多详细内容,请参见开通并创建默认工作空间。
本教程地域选择:华东1(杭州)。您也可以根据情况选择华北2(北京)、华东2(上海)、华南1(深圳)地域。
单击免费开通并创建默认工作空间:在弹出的开通页面中配置订单详情。配置要点如下。
本教程不需要开通其他产品,您需要在组合开通配置模块,去勾选其他产品的复选框。
在服务角色授权模块单击去授权,根据界面提示为PAI完成授权,然后返回开通页面,刷新页面,继续开通操作。
开通成功后单击进入PAI控制台,在默认工作空间中创建DSW实例。其中关键参数配置如下,其他参数取默认配置即可。更多详细内容,请参见创建DSW实例。
【说明】:创建DSW实例需要一定时间,与当前的资源数有关,通常大约需要15分钟。如果您使用地域资源不足,可更换其他支持免费试用的地域申请开通试用并创建DSW实例。
参数
描述
地域及可用区
本教程选择:华东1(杭州)。
实例名称
您可以自定义实例名称,本教程示例为:AIGC_test。
资源配额
本教程需选择公共资源(后付费)的GPU规格,规格名称为ecs.gn6v-c8g1.2xlarge。
【说明】:阿里云免费试用提供的资源类型包括以下几种类型:
ecs.gn7i-c8g1.2xlarge
ecs.g6.xlarge
ecs.gn6v-c8g1.2xlarge
选择镜像
选择官方镜像中的stable-diffusion-webui-develop:1.0-pytorch1.13-gpu-py310-cu117-ubuntu22.04。
在DSW中打开教程文件
5
进入PAI-DSW开发环境。
登录PAI控制台。
在页面左上方,选择DSW实例所在的地域。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在左侧导航栏,选择模型开发与训练>交互式建模(DSW)。
单击需要打开的实例操作列下的打开,进入PAI-DSW实例开发环境。
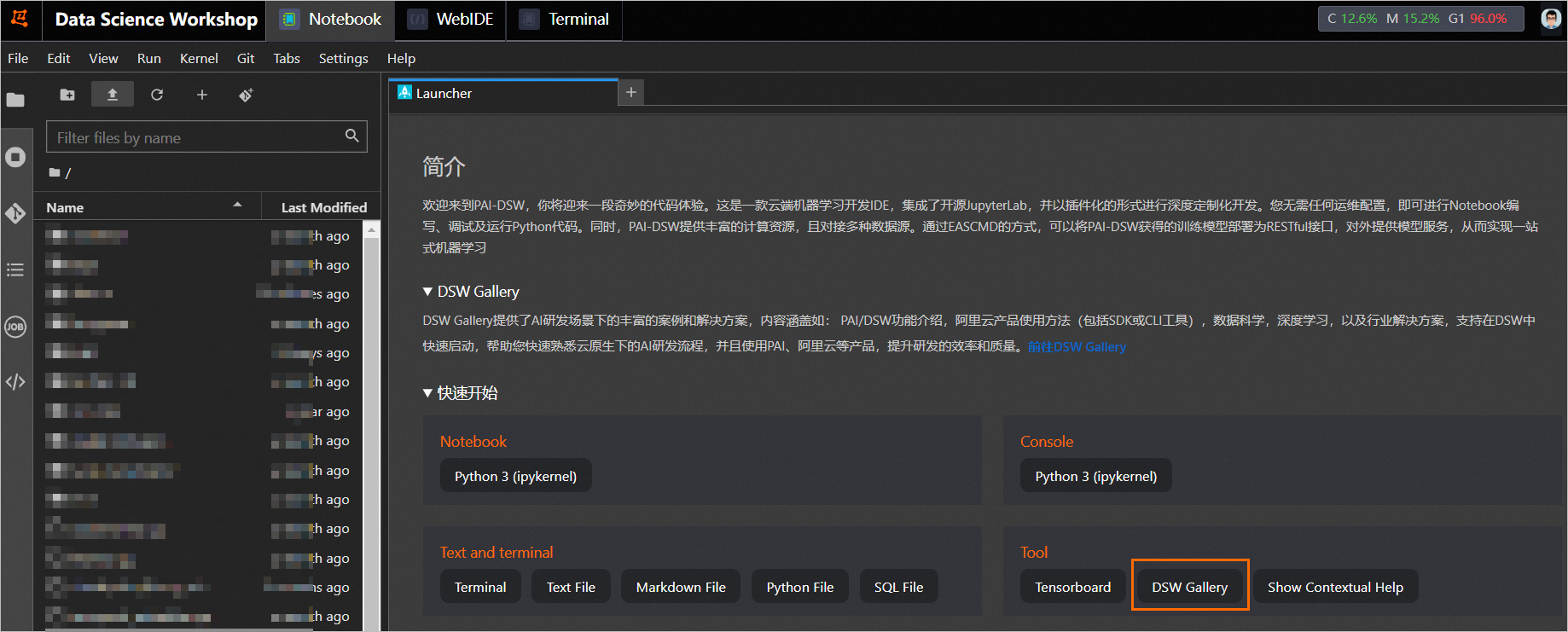
在Notebook页签的Launcher页面,单击快速开始区域Tool下的DSW Gallery,打开DSW Gallery页面。
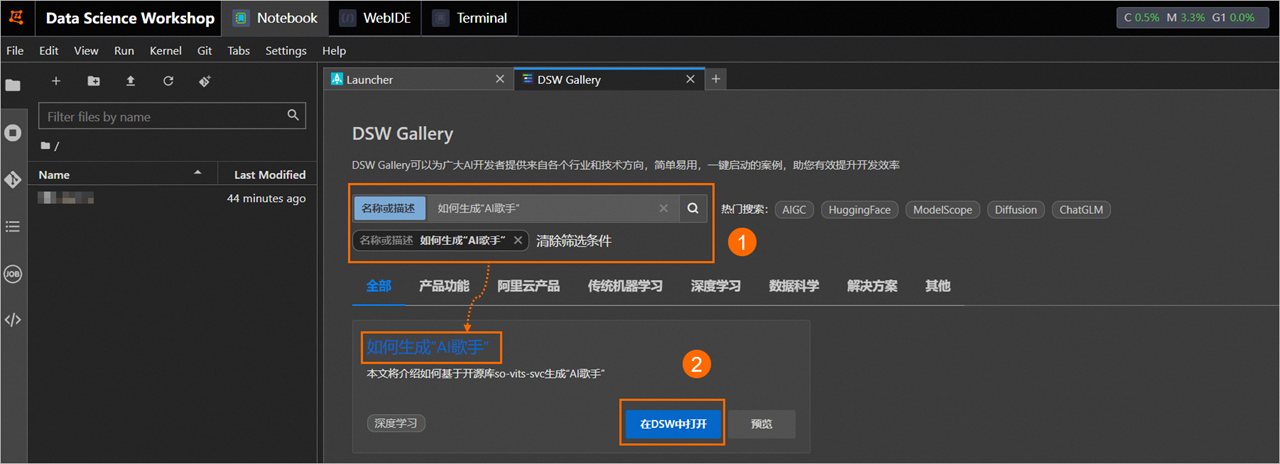
在DSW Gallery页面中,搜索并找到如何生成“AI歌手”教程,单击教程卡片中的在DSW中打开。
单击后即会自动将本教程所需的资源和教程文件下载至DSW实例中,并在下载完成后自动打开教程文件。
运行教程文件
40
在打开的教程文件ai_singer.ipynb文件中,您可以直接看到教程文本,您可以在教程文件中直接运行对应的步骤的命令,当成功运行结束一个步骤命令后,再顺次运行下个步骤的命令。 本教程包含的操作步骤以及每个步骤的运行结果如下。
本教程包含的操作步骤以及每个步骤的运行结果如下。
下载so-vits-svc源码并安装依赖包。
克隆开源代码。
安装依赖包。
【说明】结果中出现的ERROR和WARNING信息可以忽略。
下载预训练模型。
下载声音编码器模型。
下载预训练模型。
下载训练数据。
您可以直接下载PAI准备好的训练数据。您也可以自行下载数据并参照教程文本中的附录内容完成数据清洗操作。
下载的样本数据格式如下,支持多种人声的训练。
dataset_raw ├───speaker1(C12) │ ├───xxx1.wav │ ├───... │ └───xxxn.wav ├───speaker2(可选) │ ├───xxx1.wav │ ├───... │ └───xxxn.wav ├───speakerN(可选)预处理训练数据。
重采样数据。
将数据切分为训练集和验证集并生成配置文件。
生成音频特征数据,并保存至
./so-vits-svc/dataset/44k/C12目录下。
训练(可选)
【说明】由于模型训练时间比较长,您可以跳过该步骤,使用PAI准备好的模型文件直接进行模型推理。
为了获得更好的效果,建议您将epochs参数值修改为1000,每个epoch训练时长大约为20~30秒。训练时长大约持续500分钟。
完成
10
完成以上操作后,您已经成功完成了AI歌手的模型训练。您可以使用上述步骤训练好的模型文件或者使用PAI准备好的模型文件进行离线推理。推理结果默认保存在./results目录下。您可以在教程文件中继续运行推理章节的操作步骤。具体操作步骤以及每个步骤的执行结果如下。
(可选)下载PAI准备好的模型文件,并将模型文件保存至
./so-vits-svc/logs/G_8800_8gpus.pth目录下。【说明】如果您使用上述步骤训练好的模型文件进行离线推理,则可以跳过该步骤。
--2023-08-30 08:50:10-- http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/projects/so-vits-svc/models/C12/G_8800.pth Resolving pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com (pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com)... 39.98.1.111 Connecting to pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com (pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com)|39.98.1.111|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 627897375 (599M) [application/octet-stream] Saving to: ‘logs/G_8800_8gpus.pth’ logs/G_8800_8gpus.p 100%[===================>] 598.81M 13.8MB/s in 45s 2023-08-30 08:50:55 (13.3 MB/s) - ‘logs/G_8800_8gpus.pth’ saved [627897375/627897375]下载测试数据,并保存至
./raw目录下。本教程使用UVR5分离好的数据作为测试数据。由于离线推理需要使用干净的人声数据,如果您想自行准备测试数据,则需要参照教程文本中的附录内容完成数据清洗操作。同时,推理数据必须存放在./raw目录下。--2023-08-30 08:51:48-- http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/projects/so-vits-svc/data/one.tar.gz Resolving pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com (pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com)... 39.98.1.111 Connecting to pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com (pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com)|39.98.1.111|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 15195943 (14M) [application/gzip] Saving to: ‘./raw/one.tar.gz’ one.tar.gz 100%[===================>] 14.49M 12.5MB/s in 1.2s 2023-08-30 08:51:50 (12.5 MB/s) - ‘./raw/one.tar.gz’ saved [15195943/15195943] one/ one/1_one_(Instrumental).wav one/1_one_(Vocals).wav one/one.mp3 one/1_1_one_(Vocals)_(Vocals).wav one/1_1_one_(Vocals)_(Instrumental).wav将声音替换为C12人物的声音。
load WARNING:xformers:WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for: PyTorch 1.13.1+cu117 with CUDA 1107 (you have 2.0.1+cu117) Python 3.10.9 (you have 3.10.6) Please reinstall xformers (see https://github.com/facebookresearch/xformers#installing-xformers) Memory-efficient attention, SwiGLU, sparse and more won't be available. Set XFORMERS_MORE_DETAILS=1 for more details load model(s) from pretrain/checkpoint_best_legacy_500.pt #=====segment start, 7.76s====== vits use time:0.8072702884674072 #=====segment start, 6.62s====== vits use time:0.11305761337280273 #=====segment start, 6.76s====== vits use time:0.11228108406066895 #=====segment start, 6.98s====== vits use time:0.11324000358581543 #=====segment start, 0.005s====== jump empty segment读取声音。
合并人声和伴奏。
Export successfully!
清理及后续
5
清理
领取免费资源包后,请在免费额度和有效试用期内使用。如果免费额度用尽或试用期结束后,继续使用计算资源,会产生后付费账单。
请前往资源实例管理页面,查看免费额度使用量和过期时间,如下图所示。
如果无需继续使用DSW实例,您可以按照以下操作步骤停止DSW实例。
登录PAI控制台。
在页面左上方,选择DSW实例的地域。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型开发与训练>交互式建模(DSW),进入交互式建模(DSW)页面。
单击目标实例操作列下的停止,成功停止后即停止资源消耗。
如果需要继续使用DSW实例,请务必至少在试用到期1小时前为您的阿里云账号充值,到期未续费的DSW实例会因欠费而被自动停止。
后续
在试用有效期期间,您还可以继续使用DSW实例进行模型训练和推理验证。
总结
常用知识点
问题1:本教程使用了DSW的哪个功能完成了AIGC的训练及推理?(单选题)
Notebook
Terminal
WebIDE
正确答案是Notebook。