报警配置功能提供统一管理容器报警场景的功能,包括容器服务异常事件报警、集群相关基础资源的关键指标报警、集群核心组件及集群中应用的指标报警。支持在创建集群时默认开启报警功能。容器服务的报警规则支持通过集群内部署CRD的方式配置管理。本文介绍容器服务报警中心功能使用场景、如何接入报警功能,以及专有集群如何授予报警功能资源的访问权限等。
背景信息
容器服务报警管理包含的功能:
功能使用场景
容器服务报警配置功能集合容器场景的监控报警能力,提供报警的统一配置管理,有如下几个典型的使用场景:
集群运维
可以通过监控报警了解集群管控、存储、网络、弹性扩缩容等异常事件。例如:
通过集群资源异常报警规则集感知集群基础资源的关键指标是否异常。例如,CPU、Memory、网络等关键指标是否出现高水位情况,避免影响集群稳定性。
通过配置并查看集群异常事件报警规则集感知集群节点或容器节点异常。例如,集群节点Docker进程异常、集群节点进程异常及集群容器副本启动失败等异常。
通过配置并查看集群存储异常事件报警规则集感知集群存储的变更与异常。
通过配置并查看集群网络异常事件报警规则集感知集群网络的变更与异常。
通过配置并查看集群管控运维异常报警规则集感知集群管控的变更与异常等。
应用开发
可以通过监控报警了解在集群中运行应用的异常事件、指标是否异常。例如,集群容器副本异常或者应用Deployment的CPU、内存水位指标是否超过阈值等。可通过开启报警配置功能中的默认报警规则模板,即可快速接收集群内应用容器副本的异常事件报警通知。例如,通过配置并订阅关注集群容器副本异常报警规则集感知所属应用的Pod是否异常。
应用管理
关注运行在集群上的应用健康、容量规划、集群运行稳定性及异常甚至是错误报警等贯穿应用生命周期的一系列问题。例如,通过配置并订阅关注集群重要事件报警规则集感知集群内所有Warning、Error等异常报警;关注集群资源异常报警规则集感知集群的资源情况,从而更好地做容量规划等。
多集群管理
当您有多个集群需要管理,为集群配置报警规则往往会是一个重复繁琐且难以同步的操作。容器服务报警配置功能,支持通过集群内部署CRD配置的方式管理报警规则。可通过维护多个集群中同样配置的CRD资源,来方便快捷地实现多集群中报警规则的同步配置。
组件安装与升级
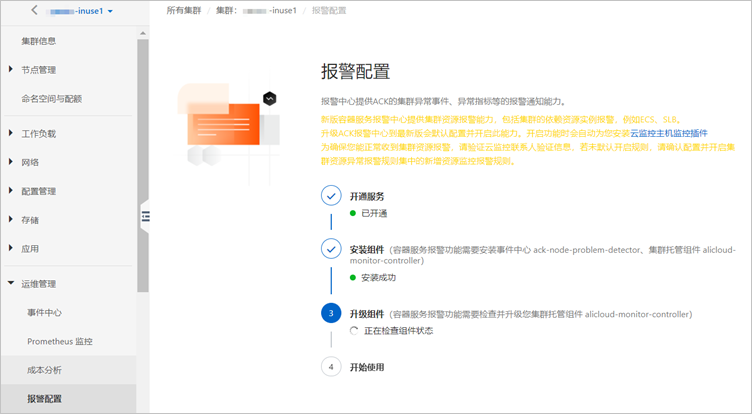
控制台会自动检测报警配置环境是否符合要求,并会引导进行开通或安装、升级组件。
登录容器服务管理控制台。
在控制台左侧导航栏,单击集群。
在集群列表页面,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页左侧导航栏,选择。
在报警配置页面控制台会自动检查以下条件。
若不符合条件,请按以下提示完成操作。
已开通SLS日志服务云产品。当您首次使用日志服务时,需要登录日志服务控制台,根据页面提示开通日志服务。
说明关于日志服务的详细计费,请参见按使用功能付费模式计费项。
已安装事件中心。具体操作,请参见事件监控。
集群托管组件alicloud-monitor-controller升级到最新版本。更多信息,请参见alicloud-monitor-controller。
如何接入报警配置功能
目前容器服务报警规则配置功能支持ACK托管版集群、ACK专有版集群。
步骤一:开启默认报警规则
创建ACK托管版集群时,打开使用默认报警模板配置报警开关,并选择报警通知联系人分组。
开启后将会创建默认报警规则,并默认发送报警通知到此联系人分组。
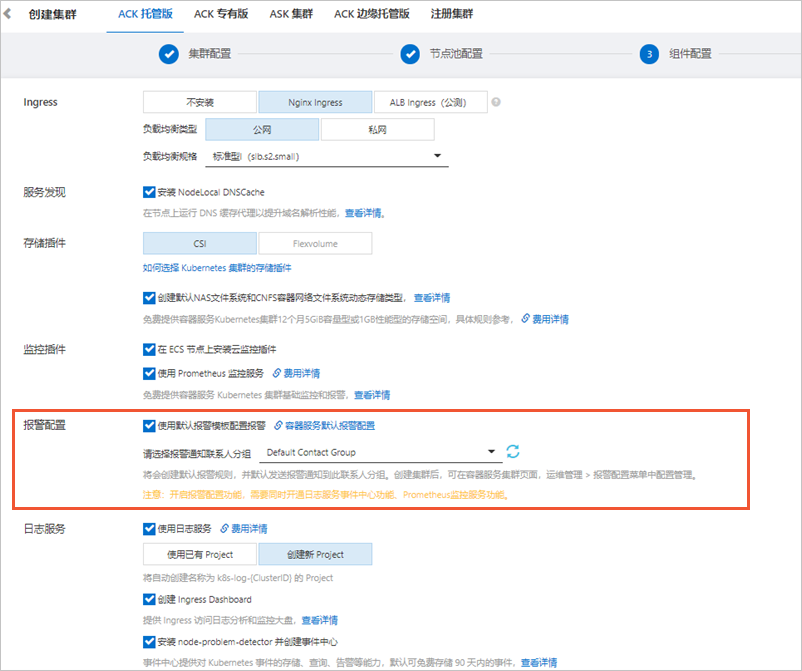
具体操作,请参见创建Kubernetes托管版集群。
若已创建集群,可在目标集群开启对应报警规则。
在目标集群左侧导航栏选择配置管理。
在报警规则管理页签,打开启动状态可开启对应报警规则集。
 具体操作,请参见步骤二:手动配置报警规则。
具体操作,请参见步骤二:手动配置报警规则。
步骤二:手动配置报警规则
ACK托管版集群、ACK专有版集群创建后,可进行报警规则、联系人和联系人分组管理。
登录容器服务管理控制台。
在控制台左侧导航栏,单击集群。
在集群列表页面,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页左侧导航栏,选择。
功能特性
说明
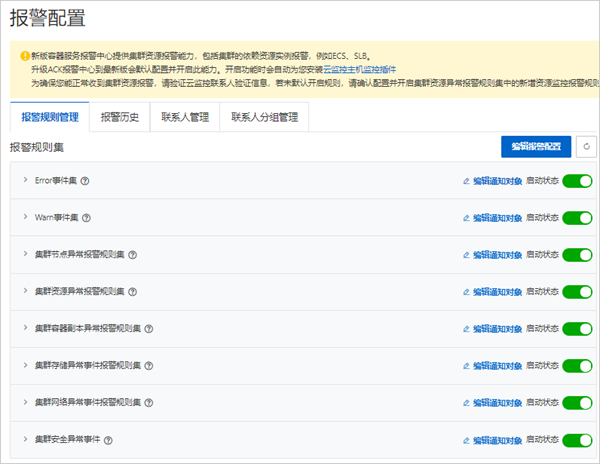
报警规则管理
容器服务报警规则功能会默认生成容器场景下的报警模板(包含异常事件报警、异常指标报警)。
报警规则被分类为若干个报警规则集,可为报警规则集关联多个联系人分组,并启动或关闭报警规则集。
报警规则集中包含多个报警规则,一个报警规则对应单个异常的检查项。多个报警规则集可以通过一个YAML资源配置到对应集群中,修改YAML会同步生成报警规则。
关于报警规则YAML配置,请参见如何通过CRD配置报警规则。
关于默认报警规则模板,请参见默认报警规则模板。
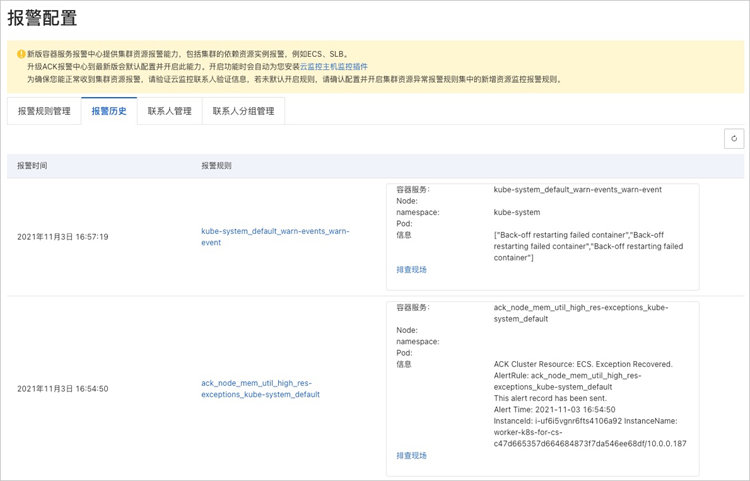
报警历史
目前可查看最近发送的近100条历史记录。单击报警规则列下的链接,可以跳转到对应监控系统中查看详细规则配置;单击排查现场,可以快速定位到异常发生的资源页面(异常事件、指标异常的资源)。
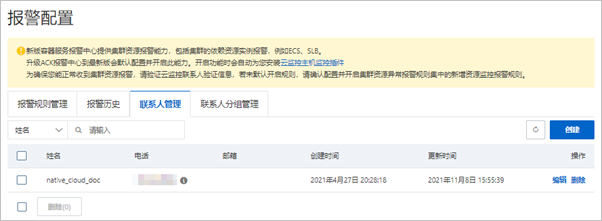
联系人管理
对联系人进行管理,可创建、编辑或删除联系人。
集群资源异常报警规则集中集群节点基础资源报警,联系人短信、邮箱等联系方式需要在云监控中先验证联系方式,才能正常接收集群基础资源报警信息。可在云监控控制台查看同步联系人,若验证信息过期,可删除云监控中对应联系人并重新刷新容器服务报警中心的联系人页面。
联系人分组管理
对联系人分组进行管理,可创建、编辑或删除联系人分组。当无联系人分组时,控制台会从您的阿里云账号注册信息中同步创建一个默认联系人分组。
在报警规则管理页签,单击编辑通知对象可设置关联的通知对象;打开启动状态可开启对应报警规则集。
如何通过CRD配置报警规则
报警配置功能开启时,会默认在kube-system Namespace下创建一个AckAlertRule类型的资源配置,包含默认报警规则模板。容器服务报警规则集可通过此资源配置在集群中。
登录容器服务管理控制台。
在控制台左侧导航栏,单击集群。
在集群列表页面,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页左侧导航栏,选择。
在报警规则管理页签中,单击右上角编辑报警配置,可查看当前集群中的AckAlertRule资源配置,并可通过YAML文件修改。
报警规则配置的YAML文件示例如下:
apiVersion: alert.alibabacloud.com/v1beta1 kind: AckAlertRule metadata: name: default spec: groups: #以下是一个集群事件报警规则配置样例。 - name: pod-exceptions #报警规则分组名,对应报警模板中的Group_Name字段。 rules: - name: pod-oom #报警规则名。 type: event #报警规则类型(Rule_Type),枚举值为event(事件类型)、metric-cms(云监控指标类型)。 expression: sls.app.ack.pod.oom #报警规则表达式,当规则类型为event时,表达式的值为本文默认报警规则模板中Rule_Expression_Id值。 enable: enable #报警规则开启状态,枚举值为enable、disable。 - name: pod-failed type: event expression: sls.app.ack.pod.failed enable: enable #以下是一个集群基础资源报警规则配置样例。 - name: res-exceptions #报警规则分组名,对应报警模板中的Group_Name字段。 rules: - name: node_cpu_util_high #报警规则名。 type: metric-cms #报警规则类型(Rule_Type),枚举值为event(事件类型)、metric-cms(云监控指标类型)。 expression: cms.host.cpu.utilization #报警规则表达式,当规则类型为metric-cms时,表达式的值为本文默认报警规则模板中Rule_Expression_Id值。 contactGroups: #报警规则映射的联系人分组配置,由ACK控制台生成,同一个账号下联系人相同,可在多集群中复用。 enable: enable #报警规则开启状态,枚举值为enable、disable。 thresholds: #报警规则阈值,详情见文档如何更改报警规则阈值部分。 - key: CMS_ESCALATIONS_CRITICAL_Threshold unit: percent value: '1'
默认报警规则模板
在以下情况下ACK会默认创建相应报警规则:
开启默认报警规则功能。
未开启默认报警规则,首次进入报警规则页面。
默认创建的报警规则如下表所示。
规则集类型 | 规则名 | 规则说明 | Rule_Type | ACK_CR_Rule_Name | SLS_Event_ID |
critical-events集群重要事件报警规则集 | 集群Error事件 | 集群中所有Error Level异常事件触发该报警。 | event | error-event | sls.app.ack.error |
集群Warn事件 | 集群中关键Warn Level异常事件触发该报警,排除部分可忽略事件。 | event | warn-event | sls.app.ack.warn | |
cluster-error集群异常事件报警规则集 | 集群节点Docker进程异常 | 集群中节点Dockerd或Containerd 运行时异常。 | event | docker-hang | sls.app.ack.docker.hang |
集群驱逐事件 | 集群中发生驱逐事件。 | event | eviction-event | sls.app.ack.eviction | |
集群GPU的XID错误事件 | 集群中GPU XID异常事件。 | event | gpu-xid-error | sls.app.ack.gpu.xid_error | |
集群节点下线 | 集群中节点下线。 | event | node-down | sls.app.ack.node.down | |
集群节点重启 | 集群中节点重启。 | event | node-restart | sls.app.ack.node.restart | |
集群节点时间服务异常 | 集群中节点时间同步系统服务异常。 | event | node-ntp-down | sls.app.ack.ntp.down | |
集群节点PLEG异常 | 集群中节点PLEG异常。 | event | node-pleg-error | sls.app.ack.node.pleg_error | |
集群节点进程异常 | 集群中节点进程数异常。 | event | ps-hang | sls.app.ack.ps.hang | |
res-exceptions集群资源异常报警规则集 | 集群节点-CPU使用率≥85% | 集群中节点实例CPU使用率超过水位。默认值85%。 剩余资源不足15%时,可能会超过容器引擎层CPU资源预留。更多信息,请参见节点资源预留策略。这可能引起高频CPU Throttle,最终严重影响进程响应速度。请及时优化CPU使用情况或调整阈值。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | node_cpu_util_high | cms.host.cpu.utilization |
集群节点-内存使用率≥85% | 集群中节点实例内存使用率超过水位。默认值85%。 剩余资源不足15%时,若仍然使用,水位将超过容器引擎层内存资源预留。更多信息,请参见节点资源预留策略。此场景下,Kubelet将发生强制驱逐行为。请及时优化内存使用情况或调整阈值。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | node_mem_util_high | cms.host.memory.utilization | |
集群节点-磁盘使用率≥85% | 集群中节点实例磁盘使用率超过水位。默认值85%。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | node_disk_util_high | cms.host.disk.utilization | |
集群节点-公网流出带宽使用率≥85% | 集群中节点实例公网流出带宽使用率超过水位。默认值85%。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | node_public_net_util_high | cms.host.public.network.utilization | |
集群节点-inode使用率≥85% | 集群中节点实例inode使用率超过水位。默认值85%。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | node_fs_inode_util_high | cms.host.fs.inode.utilization | |
集群资源-负载均衡最大连接数使用率≥85% | 集群中负载均衡实例最大连接数超过水位。默认值85%。 说明 负载均衡实例,即API-Server、Ingress所关联的SLB负载均衡实例。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | slb_qps_util_high | cms.slb.qps.utilization | |
集群资源-负载均衡网络流出带宽使用率≥85% | 集群中负载均衡实例网络流出带宽使用率超过水位。默认值85%。 说明 负载均衡实例,即API-Server、Ingress所关联的SLB负载均衡实例。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | slb_traff_tx_util_high | cms.slb.traffic.tx.utilization | |
集群资源-负载均衡最大连接数使用率≥85% | 集群中负载均衡实例最大连接数使用率超过水位。默认值85%。 说明 负载均衡实例,即API-Server、Ingress所关联的SLB负载均衡实例。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | slb_max_con_util_high | cms.slb.max.connection.utilization | |
集群资源-负载均衡监听每秒丢失连接数持续≥1 | 集群中负载均衡实例每秒丢失连接数持续超过水位。默认值1次。 说明 负载均衡实例,即API-Server、Ingress所关联的SLB负载均衡实例。 关于如何调整阈值,请参见如何修改集群基础资源报警规则的阈值。 | metric-cms | slb_drop_con_high | cms.slb.drop.connection | |
集群节点文件句柄过多 | 集群中节点文件句柄数过多异常。 | event | node-fd-pressure | sls.app.ack.node.fd_pressure | |
集群节点磁盘空间不足 | 集群中节点磁盘空间不足异常事件。 | event | node-disk-pressure | sls.app.ack.node.disk_pressure | |
集群节点进程数过多 | 集群中节点进程数过多异常事件。 | event | node-pid-pressure | sls.app.ack.node.pid_pressure | |
集群节点调度资源不足 | 集群中无调度资源异常事件。 | event | node-res-insufficient | sls.app.ack.resource.insufficient | |
集群节点IP资源不足 | 集群中IP资源不足异常事件。 | event | node-ip-pressure | sls.app.ack.ip.not_enough | |
pod-exceptions集群容器副本异常报警规则集 | 集群容器副本OOM | 集群容器副本Pod或其中进程出现OOM(Out of Memory)。 | event | pod-oom | sls.app.ack.pod.oom |
集群容器副本启动失败 | 集群容器副本Pod启动失败事件(Pod Start Failed)。 | event | pod-failed | sls.app.ack.pod.failed | |
集群镜像拉取失败事件 | 集群容器副本Pod出现镜像拉取失败事件。 | event | image-pull-back-off | sls.app.ack.image.pull_back_off | |
cluster-ops-err集群管控运维异常报警规则集 | 无可用LoadBalancer | 集群无法创建LoadBalancer事件。请提交工单联系容器服务团队。 | event | slb-no-ava | sls.app.ack.ccm.no_ava_slb |
同步LoadBalancer失败 | 集群创建LoadBalancer同步失败事件。请提交工单联系容器服务团队。 | event | slb-sync-err | sls.app.ack.ccm.sync_slb_failed | |
删除LoadBalancer失败 | 集群删除LoadBalancer失败事件。请提交工单联系容器服务团队。 | event | slb-del-err | sls.app.ack.ccm.del_slb_failed | |
删除节点失败 | 集群删除节点失败事件。请提交工单联系容器服务团队。 | event | node-del-err | sls.app.ack.ccm.del_node_failed | |
添加节点失败 | 集群添加节点失败事件。请提交工单联系容器服务团队。 | event | node-add-err | sls.app.ack.ccm.add_node_failed | |
创建VPC网络路由失败 | 集群创建VPC网络路由失败事件。请提交工单联系容器服务团队。 | event | route-create-err | sls.app.ack.ccm.create_route_failed | |
同步VPC网络路由失败 | 集群同步VPC网络路由失败事件。请提交工单联系容器服务团队。 | event | route-sync-err | sls.app.ack.ccm.sync_route_failed | |
托管节点池命令执行失败 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-run-cmd-err | sls.app.ack.nlc.run_command_fail | |
托管节点池未提供任务的具体命令 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-empty-cmd | sls.app.ack.nlc.empty_task_cmd | |
托管节点池出现未实现的任务模式 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-url-m-unimp | sls.app.ack.nlc.url_mode_unimpl | |
托管节点池发生未知的修复操作 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-opt-no-found | sls.app.ack.nlc.op_not_found | |
托管节点池销毁节点发生错误 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-des-node-err | sls.app.ack.nlc.destroy_node_fail | |
托管节点池节点排水失败 | 集群托管节点池排水异常事件。请提交工单联系容器服务团队。 | event | nlc-drain-node-err | sls.app.ack.nlc.drain_node_fail | |
托管节点池重启ECS未达到终态 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-restart-ecs-wait | sls.app.ack.nlc.restart_ecs_wait_fail | |
托管节点池重启ECS失败 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-restart-ecs-err | sls.app.ack.nlc.restart_ecs_fail | |
托管节点池重置ECS失败 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-reset-ecs-err | sls.app.ack.nlc.reset_ecs_fail | |
托管节点池自愈任务失败 | 集群托管节点池异常事件。请提交工单联系容器服务团队。 | event | nlc-sel-repair-err | sls.app.ack.nlc.repair_fail | |
cluster-network-err集群网络异常事件报警规则集 | Terway资源无效 | 集群Terway网络资源无效异常事件。请提交工单联系容器服务团队。 | event | terway-invalid-res | sls.app.ack.terway.invalid_resource |
Terway分配IP失败 | 集群Terway网络资源分配IP失败异常事件。请提交工单联系容器服务团队。 | event | terway-alloc-ip-err | sls.app.ack.terway.alloc_ip_fail | |
解析Ingress带宽配置失败 | 集群Ingress网络解析配置异常事件。请提交工单联系容器服务团队。 | event | terway-parse-err | sls.app.ack.terway.parse_fail | |
Terway分配网络资源失败 | 集群Terway网络资源分配失败异常事件。请提交工单联系容器服务团队。 | event | terway-alloc-res-err | sls.app.ack.terway.allocate_failure | |
Terway回收网络资源失败 | 集群Terway网络资源回收失败异常事件。请提交工单联系容器服务团队。 | event | terway-dispose-err | sls.app.ack.terway.dispose_failure | |
Terway虚拟模式变更 | 集群Terway网络虚拟模式变更事件。 | event | terway-virt-mod-err | sls.app.ack.terway.virtual_mode_change | |
Terway触发PodIP配置检查 | 集群Terway网络触发PodIP配置检查事件。 | event | terway-ip-check | sls.app.ack.terway.config_check | |
Ingress重载配置失败 | 集群Ingress网络配置重载异常事件。请检查Ingress配置是否正确。 | event | ingress-reload-err | sls.app.ack.ingress.err_reload_nginx | |
cluster-storage-err集群存储异常事件报警规则集 | 云盘容量少于20 GiB限制 | 集群网盘固定限制,无法挂载小于20 GiB的磁盘。请检查所挂载云盘的容量大小。 | event | csi_invalid_size | sls.app.ack.csi.invalid_disk_size |
容器数据卷暂不支持包年包月类型云盘 | 集群网盘固定限制,无法挂载包年包月类型的云盘。请检查所挂载云盘的售卖方式。 | event | csi_not_portable | sls.app.ack.csi.disk_not_portable | |
挂载点正在被进程占用,卸载挂载点失败 | 集群存储挂载点正在被进程占用,卸载挂载点失败。 | event | csi_device_busy | sls.app.ack.csi.deivce_busy | |
无可用云盘 | 集群存储挂载时无可用云盘异常。请提交工单联系容器服务团队。 | event | csi_no_ava_disk | sls.app.ack.csi.no_ava_disk | |
云盘IOHang | 集群出现IOHang异常。请提交工单联系容器服务团队。 | event | csi_disk_iohang | sls.app.ack.csi.disk_iohang | |
磁盘绑定的PVC发生slowIO | 集群磁盘绑定的PVC发生slowIO异常。请提交工单联系容器服务团队。 | event | csi_latency_high | sls.app.ack.csi.latency_too_high | |
磁盘容量超过水位阈值 | 集群磁盘使用量超过水位值异常。请检查您的集群磁盘水位情况。 | event | disk_space_press | sls.app.ack.csi.no_enough_disk_space | |
security-err集群安全异常事件 | 安全巡检发现高危风险配置 | 集群安全巡检发现高危风险配置事件。请提交工单联系容器服务团队。 | event | si-c-a-risk | sls.app.ack.si.config_audit_high_risk |
如何为专有版集群授予报警功能访问权限
专有版集群在使用报警规则功能之前,需要手动添加权限。
托管版集群已自动添加SLS报警功能资源的访问权限。
为专有版集群SLS报警功能及ARMS-Prometheus报警功能授予资源访问权限。更多信息,请参见RAM自定义授权场景及访问控制概述。
登录容器服务管理控制台。
在控制台左侧导航栏,单击集群。
在集群列表页面,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群信息页面,单击集群资源页签Worker RAM角色字段右侧的链接,进入RAM访问控制控制台。
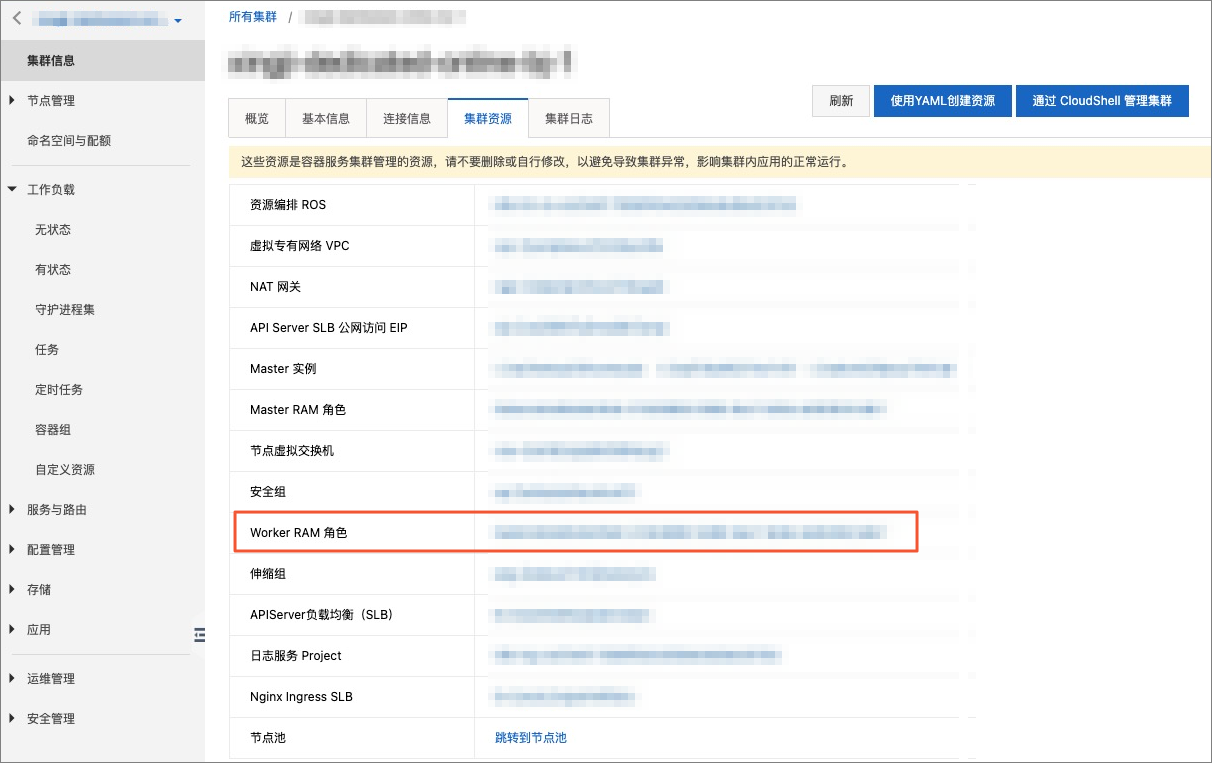
在角色页面的权限管理页签,单击对应权限策略名称的链接。
在策略内容页签单击修改策略内容,然后将以下内容添加到策略内容中。
{ "Action": [ "log:*", "arms:*", "cms:*", "cs:UpdateContactGroup" ], "Resource": [ "*" ], "Effect": "Allow" }单击继续编辑基本信息,然后单击确定完成配置。
通过日志查看报警功能访问权限是否已配置。
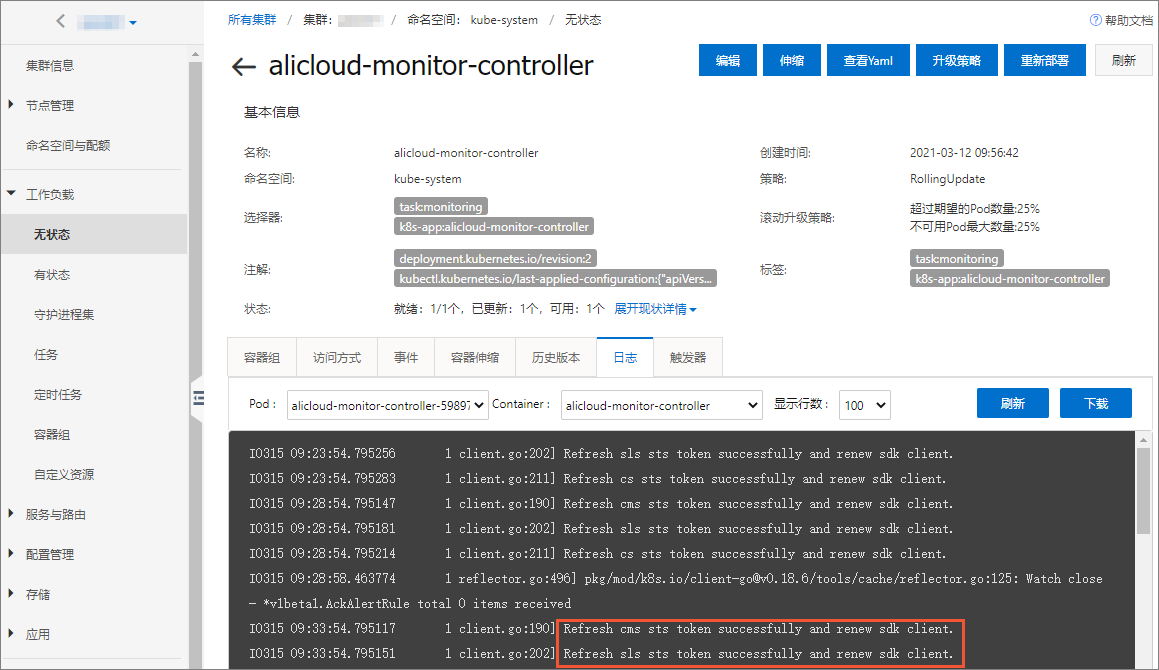
在容器服务管理控制台目标集群管理页左侧导航栏,选择。
选择命名空间kube-system,单击无状态应用列表中alicloud-monitor-controller的名称链接。
单击日志页签,可看到授权成功的Pod日志。
如何修改集群基础资源报警规则的阈值
Rule_Type为metric-cms的报警规则,是同步自云监控的基础资源报警规则,此类规则可通过CRD配置报警规则的阈值。具体操作,请参见如何通过CRD配置报警规则。
本示例通过集群节点-CPU使用率规则的报警规则CRD,增加thresholds参数配置基础监控报警规则的阈值、重试判断次数、静默期配置。
apiVersion: alert.alibabacloud.com/v1beta1
kind: AckAlertRule
metadata:
name: default
spec:
groups:
#以下是一个集群基础资源报警规则配置样例。
- name: res-exceptions #报警规则分组名,对应报警模板中的Group_Name字段。
rules:
- name: node_cpu_util_high #报警规则名。
type: metric-cms #报警规则类型(Rule_Type),枚举值为event(事件类型)、metric-cms(云监控指标类型)。
expression: cms.host.cpu.utilization #报警规则表达式,当规则类型为metric-cms时,表达式的值为本文默认报警规则模板中Rule_Expression_Id值。
contactGroups: #报警规则映射的联系人分组配置,由ACK控制台生成,同一个账号下联系人相同,可在多集群中复用。
enable: enable #报警规则开启状态,枚举值为enable、disable。
thresholds: #报警规则阈值,更多信息,请参见如何通过CRD配置报警规则。
- key: CMS_ESCALATIONS_CRITICAL_Threshold
unit: percent
value: '1'
- key: CMS_ESCALATIONS_CRITICAL_Times
value: '3'
- key: CMS_RULE_SILENCE_SEC
value: '900' 参数名 | 说明 | 默认值 |
| 报警配置阈值。
此参数必填,未配置时规则将同步失败并关闭。 | 根据默认报警模板配置而定。 |
| 云监控规则重试判断次数。 可选参数,未配置时取默认值。 | 3 |
| 云监控持续发送异常触发规则时,初次上报报警后静默期时长(单位:秒),防止过于频繁报警。 可选参数,未配置时取默认值。 | 900 |
如何在对应监控系统中查看ACK报警中心报警规则
当开启ACK报警中心的默认报警规则后,同步成功即可在报警规则中,通过单击高级设置,分别跳转到此规则的监控系统(ARMS/SLS/CMS)服务的报警规则设置页面。或直接进入对应监控系统,查看此报警规则的详细配置。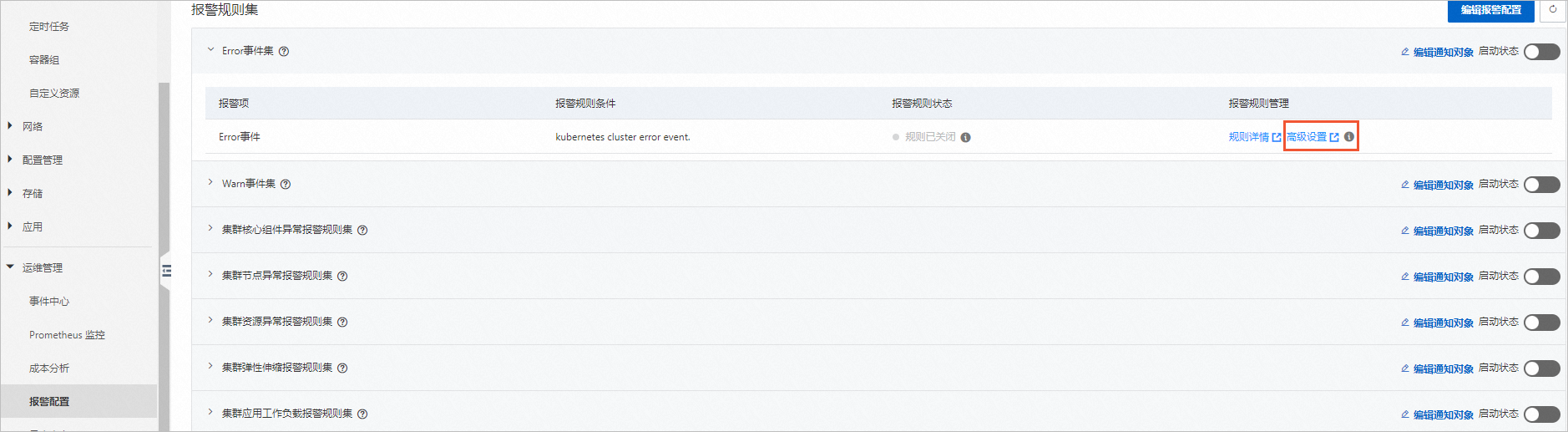
日志服务的报警规则:
登录日志服务控制台。
搜索并进入此集群日志服务对应的Project。集群默认日志服务Project命名为K8s-log-{{clusterId}}。

在左侧导航栏,单击
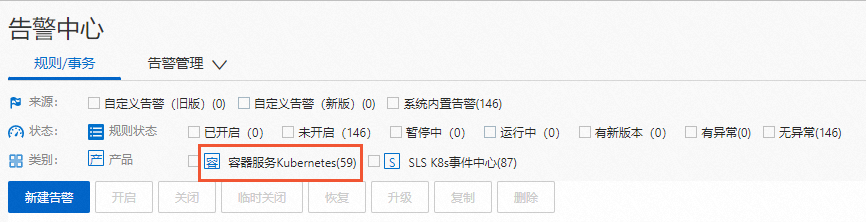
 图标,在告警中心页面中,单击规则/事务页签,查看已开启的规则。类别选择容器服务Kubernetes,可筛选展示ACK报警中心同步的此集群的默认报警规则。说明
图标,在告警中心页面中,单击规则/事务页签,查看已开启的规则。类别选择容器服务Kubernetes,可筛选展示ACK报警中心同步的此集群的默认报警规则。说明需要您开启ACK报警中心的报警规则,否则无法显示类别。
云监控报警规则:
登录云监控控制台。
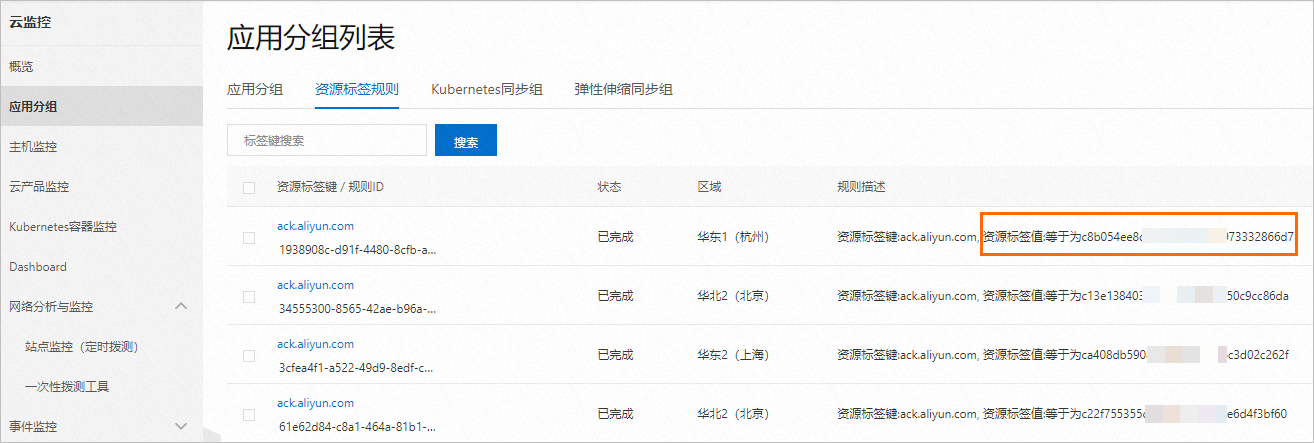
在左侧导航栏,单击应用分组,在应用分组列表页面,单击资源标签规则页签。
在规则描述列,查找资源标签键:ack.aliyun.com,资源标签值:等于为<集群ID>的规则。
Prometheus报警规则:登录ARMS控制台,查看ACK报警中心在此集群已经同步的Prometheus报警规则。报警规则名在Prometheus控制台中以
报警规则名_集群名展示。
常见问题
报警规则同步失败且报错信息为The Project does not exist : k8s-log-xxx
问题现象:
当报警中心中报警规则同步状态出现如下情况: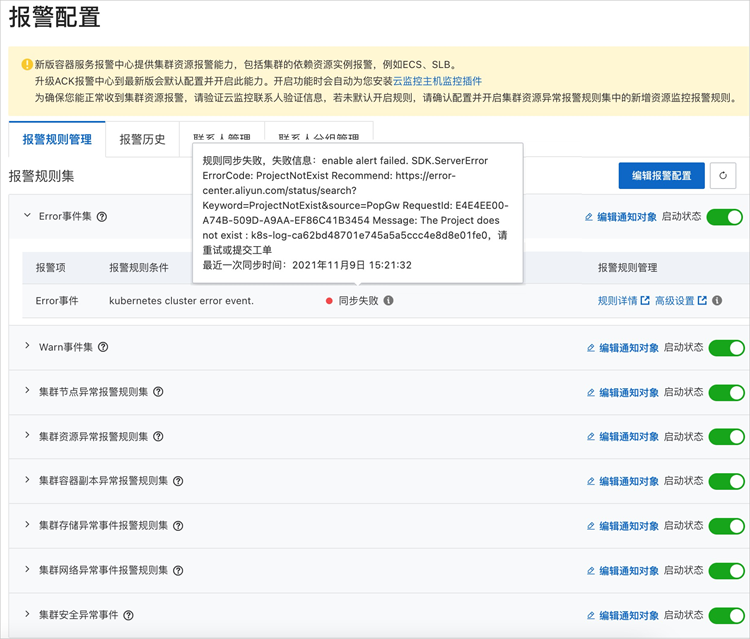
问题原因:
未创建SLS事件中心资源。
解决方案:
在日志服务管理控制台检查Project是否达到Quota上限,删除多余的Project,或提交工单申请扩大Project资源Quota限制。关于如何删除Project,请参见管理Project。
重新安装ack-node-problem-detector组件。
在容器服务管理控制台目标集群管理页左侧导航栏中,选择。
若您需要通过YAML方式重新安装ack-node-problem-detector组件,请通过以下操作备份ack-node-problem-detector组件资源。
在Helm页面,单击ack-node-problem-detector组件右侧操作列的更新。更新完成后,单击ack-node-problem-detector组件右侧操作列详情。在ack-node-problem-detector组件详情页,单击所有资源信息的查看YAML,并保存各资源的YAML到本地。
在Helm页面,单击ack-node-problem-detector组件右侧操作列的删除。
在集群管理页左侧导航栏中,选择。
单击日志与监控页签,在ack-node-problem-detector组件的卡片中单击安装。
在提示对话框中确认版本信息后单击确定。安装成功后,对应组件卡片区域会提示已安装,且可查看组件当前版本。
由于无订阅的联系人组导致报警规则同步失败
问题现象:
当报警中心中报警规则同步状态出现如下情况:
报错信息为类似信息:this rule have no xxx contact groups reference。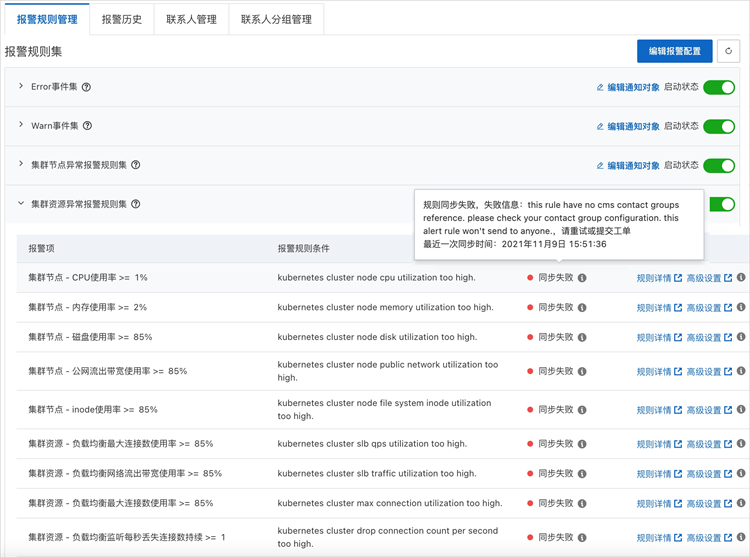
问题原因:
报警规则无订阅的联系人组。
解决方案:
已创建联系人,并将联系人加入联系人分组中。
在对应报警规则集右侧单击编辑通知对象,为该组报警规则配置订阅的联系人分组。
关于上述操作的详情,请参见如何接入报警配置功能。
- 本页导读 (1)