云原生数据仓库AnalyticDB MySQL版是阿里巴巴自主研发、经过超大规模以及核心业务验证的PB级实时数据仓库。
概述
自2012年第一次在集团发布上线以来,AnalyticDB MySQL版至今已累计迭代发布近百个版本,支撑起集团内的电商、广告、物流、文娱、旅游、风控等众多在线分析业务。AnalyticDB MySQL版从2014年开始正式对外提供服务,覆盖十多个行业,既包括传统的大中型企业和政府机构,也包括众多的互联网公司。
AnalyticDB MySQL版是基于数据库大数据一体化的理念和趋势,在工程上深度打磨出的云原生数据仓库。
技术架构
AnalyticDB MySQL版采用云原生架构,计算存储分离、冷热数据分离,支持高吞吐实时写入和数据强一致,兼顾高并发查询和大吞吐批处理的混合负载。
AnalyticDB MySQL数仓版(3.0)主要用来处理高性能在线分析场景的数据。随着数据规模的暴增和数据格式的多样化,通常需要离线处理ETL前,先对数据进行加工规整。AnalyticDB MySQL新推出的湖仓版(3.0)新增了高吞吐离线处理能力,通过一体化的方式解决离线处理和在线分析两种场景的需求,恰好可以解决该问题。
数仓版(3.0)
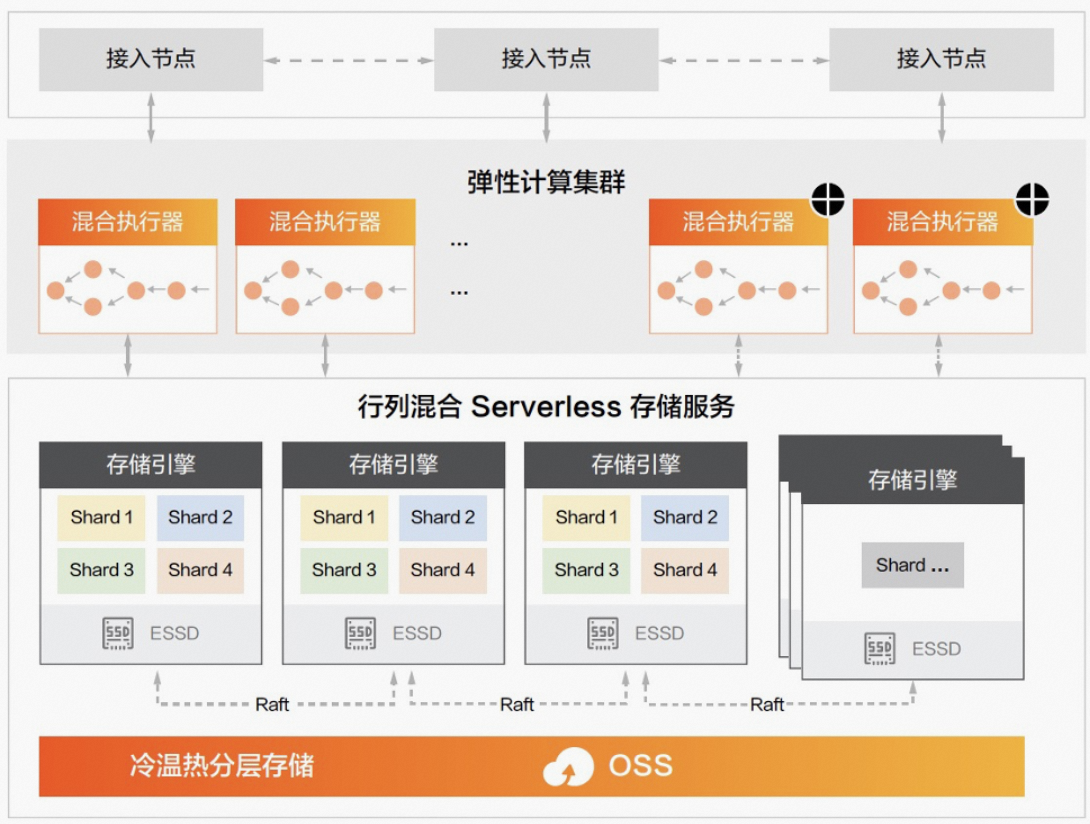
接入层
接入层由Mulit-Master可线性扩展的协调节点构成,主要负责协议层接入、SQL解析和优化、实时写入Sharding、数据调度和查询调度。
计算引擎
计算引擎具备分布式MPP和DAG融合执行能力,结合智能优化器,可支持高并发和复杂SQL混合负载。同时借助云原生基础设施,计算节点实现了弹性调度,可根据业务需求做到分钟级甚至秒级扩展,实现了资源的有效利用。
存储引擎
存储引擎是基于Raft协议实现的分布式实时强一致高可用的引擎,通过数据分片和Multi-Raft实现并行,利用分层存储实现冷热分离降低成本,通过行列存储和智能索引达到很好的性能。
在这三层架构之上,通过服务秒级恢复,支持跨可用区部署,自动故障检测、摘除和副本重搭。配合三副本存储、全量和增量备份,提供金融级别的数据可靠性。在周边生态上,提供数据迁移、数据同步、数据管理、数据集成、数据安全等配套工具,方便使用,使您能更加专注于业务发展。
湖仓版(3.0)
在数仓版(3.0)基础上,同时满足低成本离线处理和高性能在线分析的湖仓一体化版本,称为湖仓版(3.0)。湖仓版(3.0)在数据全链路的“采存算管用”5大方面都进行了全面升级。
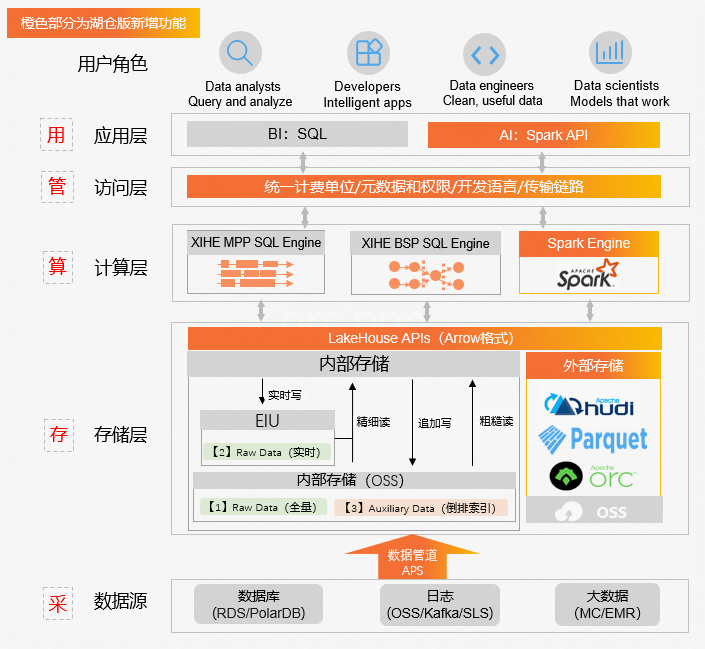
数据源
数据管道APS可以一键低成本接入数据库、日志、大数据中的数据。
存储层+计算层
支持自研引擎,羲和计算引擎和玄武存储引擎。新增集成的开源引擎,Spark计算引擎和Hudi存储引擎。可以借助开源的能力为您提供更丰富的数据分析场景。同时打通自研和开源引擎之间的互相访问,提供更一体化的体验。
- 存储层:只需一份全量数据,满足离线在线场景。
在线分析场景需要数据尽量在高性能存储介质上提高性能,离线场景需要数据尽量在低成本存储介质上降低存储成本。为满足不同场景需求,首先将一份全量数据存储在低成本高吞吐存储介质中,低成本离线处理场景直接读写低成本存储介质中的数据,可降低数据存储和数据IO成本,保证高吞吐。其次将实时数据存储在单独的存储IO节点(EIU)上,保证行级的数据实时性,同时对全量数据构建索引,并通过缓存能力对数据进行加速,满足百毫秒级高性能在线分析场景。
- 计算层:羲和计算引擎,智能选择计算模式。开源Spark计算引擎,满足多种场景。
羲和计算引擎同时提供MPP和BSP两种模式。MPP模式是一种流式计算模式,不适合离线处理低成本和高吞吐场景。BSP模式,通过DAG进行任务切分,分批调度,满足有限资源下大数据量计算,支持计算数据落盘。羲和计算引擎提供自动切换能力,即当查询使用MPP模式无法在一定耗时内完成时,系统会自动切换为BSP模式进行执行。
湖仓版新增的开源Spark计算引擎可以满足更复杂的离线处理场景和机器学习场景。湖仓版中Spark计算层和存储层互相打通,您可以使用计算层资源来处理存储层数据,在创建和配置Spark资源组时更容易。
访问层
访问层通过统一计费单位、统一元数据和权限、统一开发语言、统一传输链路,提升开发效率。
AnalyticDB MySQL版融合了分布式、弹性计算与云计算的优势,对规模性、易用性、可靠性和安全性等方面进行了大规模的改进,充分满足不同场景实时数据仓库的需求。支持更大规模的并发访问、更快读写能力以及更智能的混合查询负载管理等,实现更精细化的资源利用和更低成本的投入,让您能更加专注于业务发展,专注于数据价值。