MaxCompute
更新时间:
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。本文主要介绍如何通过DLA Serverless Spark访问MaxCompute。
重要
云原生数据湖分析(DLA)产品已退市,云原生数据仓库 AnalyticDB MySQL 版湖仓版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相关使用文档,请参见访问MaxCompute数据源。
前提条件
已经开通对象存储OSS(Object Storage Service)服务。具体操作请参考开通OSS服务。
已经创建MaxCompute的项目空间。具体操作请参考创建MaxCompute项目。假设本文中项目空间为spark_on_maxcompute,模式为简单模式(单环境)。
已经在MaxCompute的项目空间中创建了表。假设本文中表名称为sparktest。建表示例如下:
CREATE TABLE `sparktest` ( `a` int, `b` STRING ) PARTITIONED BY (pt string);已经为MaxCompute的项目空间添加RAM用户及对应角色。具体操作请参考授权给其他用户。
操作步骤
准备以下测试代码和依赖包来访问MaxCompute,并将此测试代码和依赖包分别编译打包生成jar包上传至您的OSS。
测试代码示例:
package com.aliyun.spark import org.apache.spark.sql.{SaveMode, SparkSession} object MaxComputeDataSourcePartitionSample { def main(args: Array[String]): Unit = { val accessKeyId = args(0) val accessKeySecret = args(1) val odpsUrl = args(2) val tunnelUrl = args(3) val project = args(4) val table = args(5) var numPartitions = 1 if(args.length > 6) numPartitions = args(6).toInt val ss = SparkSession.builder().appName("Test Odps Read").getOrCreate() import ss.implicits._ val dataSeq = (1 to 1000000).map { index => (index, (index-3).toString) }.toSeq val df = ss.sparkContext.makeRDD(dataSeq).toDF("a", "b") System.out.println("*****" + table + ",before overwrite table") df.write.format("org.apache.spark.aliyun.odps.datasource") .option("odpsUrl", odpsUrl) .option("tunnelUrl", tunnelUrl) .option("table", table) .option("project", project) .option("accessKeySecret", accessKeySecret) .option("partitionSpec", "pt='2018-04-01'") .option("allowCreateNewPartition", true) .option("accessKeyId", accessKeyId).mode(SaveMode.Overwrite).save() System.out.println("*****" + table + ",after overwrite table, before read table") val readDF = ss.read .format("org.apache.spark.aliyun.odps.datasource") .option("odpsUrl", odpsUrl) .option("tunnelUrl", tunnelUrl) .option("table", table) .option("project", project) .option("accessKeySecret", accessKeySecret) .option("accessKeyId", accessKeyId) .option("partitionSpec", "pt='2018-04-01'") .option("numPartitions",numPartitions).load() readDF.collect().foreach(println) } }MaxCompute依赖的pom文件:
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-commons</artifactId> <version>0.28.4-public</version> </dependency> <dependency> <groupId>com.aliyun.apsaradb</groupId> <artifactId>maxcompute-spark</artifactId> <version>0.28.4-public_2.4.3-1.0-SNAPSHOT</version> </dependency>在页面左上角,选择MaxCompute项目空间所在地域。
单击左侧导航栏中的。
在作业编辑页面,单击创建作业。
在创建作业模板页面,按照页面提示进行参数配置后,单击确定创建Spark作业。
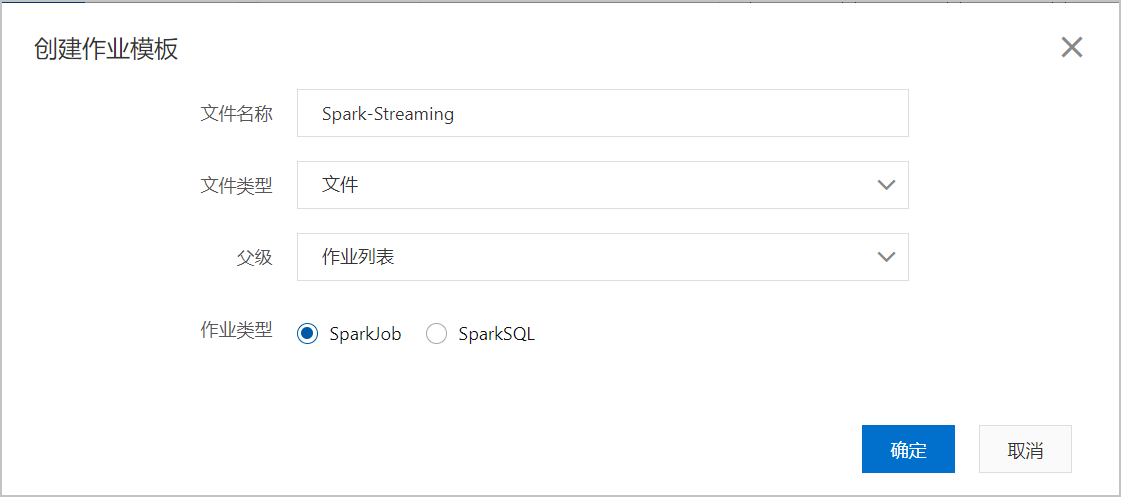
单击Spark作业名,在Spark作业编辑框中输入以下作业内容,并按照以下参数说明进行参数值替换。保存并提交Spark作业。
{ "args": [ "xxx1", #具备访问MaxCompute权限的AccessKey ID。 "xxx2", #具备访问MaxCompute权限的AccessKey Secret。 "http://service.cn.maxcompute.aliyun-inc.com/api", #MaxCompute的VPC网络Endpoint。 "http://dt.cn-shenzhen.maxcompute.aliyun-inc.com", #MaxCompute的VPC网络Tunnel Endpoint。 "spark_on_maxcompute", #MaxCompute的工作空间名称。 "sparktest", #MaxCompute的数据表名。 "2" #MaxCompute数据表的分区数。 ], "file": "oss://spark_test/jars/maxcompute/spark-examples-0.0.1-SNAPSHOT.jar", #存放测试软件包的OSS路径。 "name": "Maxcompute-test", "jars": [ ##存放测试软件依赖包的OSS路径。 "oss://spark_test/jars/maxcompute/maxcompute-spark-0.28.4-public_2.4.3-1.0-SNAPSHOT.jar", "oss://spark_test/jars/maxcompute/odps-sdk-commons-0.28.4-public.jar", "oss://spark_test/jars/maxcompute/odps-sdk-core-0.28.4-public.jar", "oss://spark_test/jars/maxcompute/mail-1.4.7.jar" ], "className": "com.aliyun.spark.MaxComputeDataSourcePartitionSample", "conf": { "spark.driver.resourceSpec": "small", "spark.executor.instances": 2, "spark.executor.resourceSpec": "small" } }
执行结果
作业运行成功后,在任务列表中单击,查看作业日志。出现如下日志说明作业运行成功: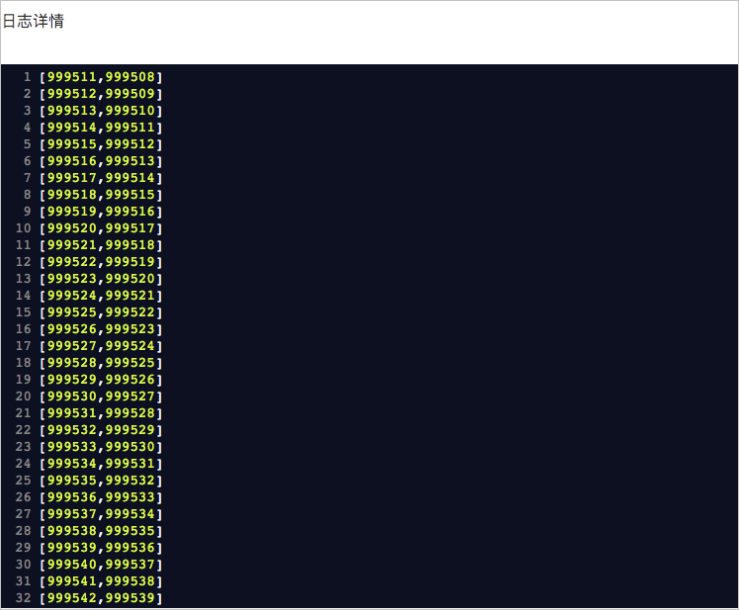
反馈
- 本页导读 (1)
文档反馈