

本文介绍了如何使用DLA Spark访问Lindorm文件引擎。
前提条件
- 已经创建了Spark虚拟集群。具体操作请参见创建虚拟集群。
- 已经开通对象存储OSS(Object Storage Service)服务。具体操作请参见开通OSS服务。
- 前往Lindorm控制台,把要访问的Lindorm实例VPC网段加入到访问控制白名单中。具体操作请参见设置白名单。
- 准备DLA Spark访问Lindorm实例文件引擎所需的安全组ID和交换机ID。具体操作请参见配置数据源网络。
操作步骤
- 准备以下测试代码来读写Lindorm文件引擎的HDFS,并将测试代码打包成AccessLindormHDFS.py文件上传至您的OSS。
from pyspark.sql import SparkSession if __name__ == '__main__': def f(a): print(a) spark = SparkSession.builder.getOrCreate() welcome_str = "hello, dla-spark" #hdfs目录用于存放内容 hdfsPath = sys.argv[1] #将welcome字符串存入指定的hdfs目录 spark.sparkContext.parallelize(list(welcome_str)).saveAsTextFile(hdfsPath) #从指定的hdfs目录中读取内容,并打印 print("----------------------------------------------------------") res = spark.sparkContext.textFile(hdfsPath).collect() [f(e) for e in res] print("-----------------------------------------------------------") - 登录Lindorm控制台,定位到Lindorm实例文件引擎,一键生成配置项。具体操作请参见开通指南。
- 登录Data Lake Analytics管理控制台。
- 在页面左上角,选择Lindorm实例文件引擎所在地域。
- 单击左侧导航栏中的Serverless Spark > 作业管理。
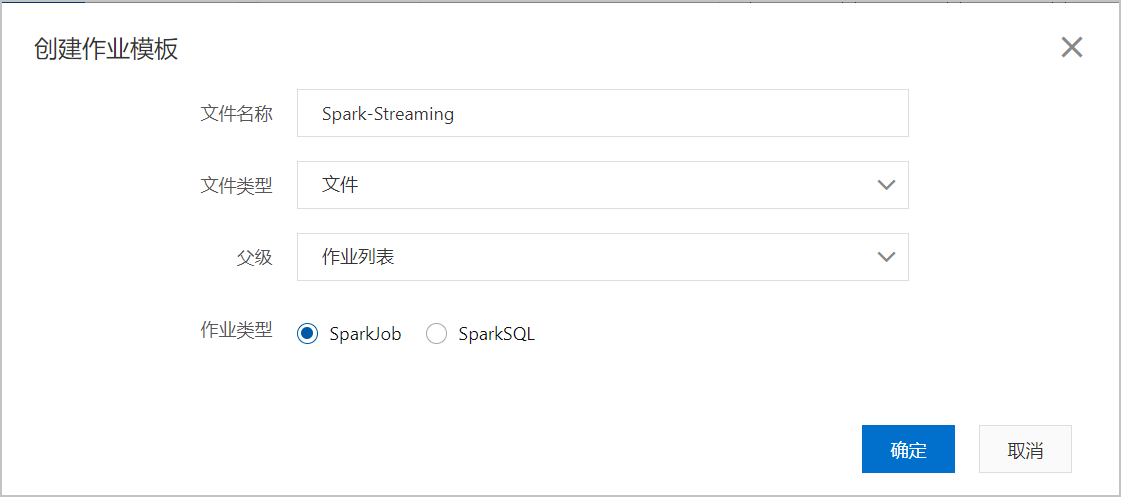
- 在作业编辑页面,单击创建作业模板。
- 在创建作业模板页面,按照页面提示进行参数配置后,单击确定创建Spark作业。
- 单击Spark作业名,在Spark作业编辑框中输入以下作业内容,并按照以下参数说明进行参数值替换。保存并提交Spark作业。
{ "name": "Lindorm", "args": [ "<fs.defaultFS>/tmp/test-lindorm.txt" ], "conf": { "spark.driver.resourceSpec": "medium", "spark.executor.resourceSpec": "medium", "spark.executor.instances": 1, "spark.kubernetes.pyspark.pythonVersion": "3", "spark.dla.job.log.oss.uri": "oss://<存放您UI日志的OSS路径>", "spark.dla.eni.enable": "true", "spark.dla.eni.security.group.id": "<您的安全组ID>", "spark.dla.eni.vswitch.id": "<您的交换机ID>", "spark.hadoop.dfs.nameservices": "<dfs.nameservices>", "spark.hadoop.dfs.client.failover.proxy.provider.<dfs.nameservices>": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider", "spark.hadoop.dfs.ha.namenodes.<dfs.nameservices>": "nn1,nn2", "spark.hadoop.dfs.namenode.rpc-address.<dfs.nameservices>.nn1": "<dfs.namenode.rpc-address.<dfs.nameservices>.nn1>", "spark.hadoop.dfs.namenode.rpc-address.<dfs.nameservices>.nn2": "<dfs.namenode.rpc-address.<dfs.nameservices>.nn2>" }, "file": "oss://path/to/AccessLindormHDFS.py" }参数说明参数名称 参考值 参数说明 args args:<fs.defaultsFS>的取值来源于步骤2中一键生成的core-site配置项中的fs.defaultsFS的值。具体请参见开通指南。无。 spark.driver.resourceSpec medium 表示Driver的规格,取值: - small:1c4g
- medium:2c8g
- large:4c16g
- xlarge:8c32g
spark.executor.resourceSpec medium 表示Executor的规格,取值: - small:1c4g
- medium:2c8g
- large:4c16g
- xlarge:8c32g
spark.executor.instances 1 表示Executor的个数。 spark.kubernetes.pyspark.pythonVersion 3 表示Python的运行版本,取值: - 2:Python2
- 3:Python3
spark.dla.job.log.oss.uri oss://<存放您UI日志的OSS路径> 存放Spark日志的路径,只能配置OSS路径。 spark.dla.eni.enable true 开启访问用户VPC网络的权限。当您需要访问用户VPC网络内的数据时,需要开启此选项。 spark.dla.eni.security.group.id <您的安全组ID> 访问用户VPC网络所需要的安全组ID。 spark.dla.eni.vswitch.id <您的交换机ID> 访问用户VPC网络所需要的交换机ID。 spark.hadoop.dfs.nameservices 取值来源于步骤2中一键生成的hdfs-site配置项中的 dfs.nameservices的值。连接Hadoop所需配置项。 spark.hadoop.dfs.client.failover.proxy.provider.<dfs.nameservices> 取值来源于步骤2中一键生成的hdfs-site配置项中的 dfs.client.failover.proxy.provider.<dfs.nameservices>的值。连接Hadoop所需配置项。 spark.hadoop.dfs.ha.namenodes.<dfs.nameservices> 取值来源于步骤2中一键生成的hdfs-site配置项中的 dfs.ha.namenodes.<dfs.nameservices>的值。连接Hadoop所需配置项。 spark.hadoop.dfs.namenode.rpc-address.<dfs.nameservices>.nn1 取值来源于步骤2中一键生成的hdfs-site配置项中的 dfs.namenode.rpc-address.<dfs.nameservices>.nn1的值。连接Hadoop所需配置项。 spark.hadoop.dfs.namenode.rpc-address.<dfs.nameservices>.nn2 取值来源于步骤2中一键生成的hdfs-site配置项中的 dfs.namenode.rpc-address.<dfs.nameservices>.nn2的值。连接Hadoop所需配置项。
常见问题
问题描述:在使用DLA Spark访问Lindorm文件引擎时,遇到如下错误。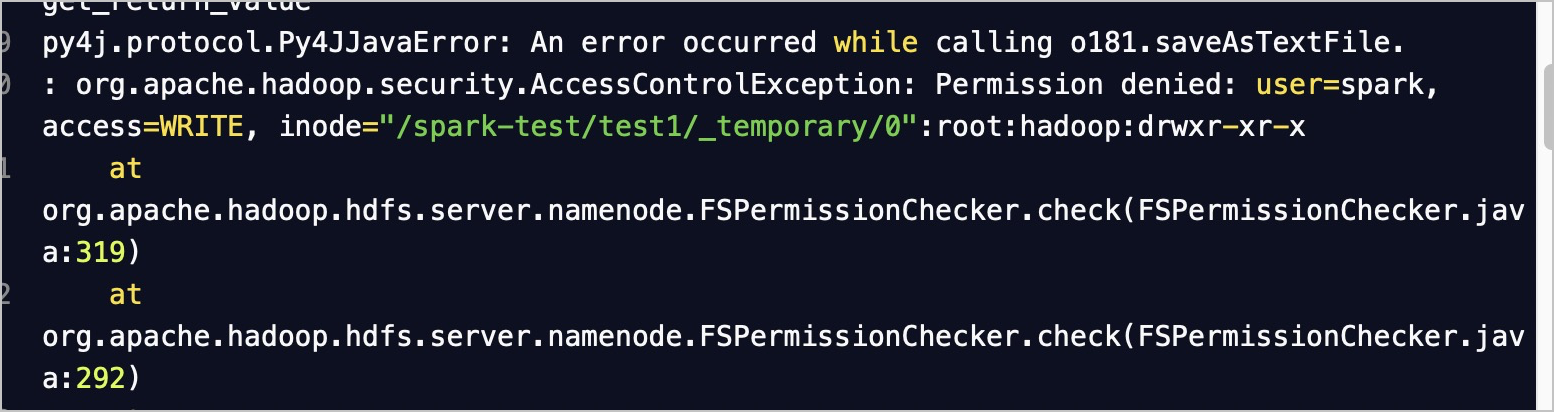
解决办法:您可以在Spark作业的配置项中增加如下参数,改变当前作业的运行用户为有权限的用户。
"spark.driver.extraJavaOptions": "-DHADOOP_USER_NAME=<用户名>",
"spark.executor.extraJavaOptions": "-DHADOOP_USER_NAME=<用户名>"