Ambari提供Hadoop组件的安装、运维、监控等功能,您可以使用Ambari管理您的Hadoop集群。 本文介绍如何将Ambari与Lindorm文件引擎集成,来替换底层HDFS存储。您可以基于Ambari+Lindorm文件引擎构建云原生存储计算分离的开源大数据系统。
前提条件
- 请保证您的Lindorm实例和Ambari集群在同一VPC网络内。
- 请保证您的Ambari节点在Lindorm白名单中,如何添加白名单请参见设置白名单。
配置文件引擎为默认的存储引擎
- 开通Lindorm文件引擎,具体步骤请参见开通指南。
- 配置Lindorm文件引擎链接。
- 登录Ambari管理系统,单击左侧导航栏HDFS>CONFIGS >ADVANCED,进入HDFS配置页面。
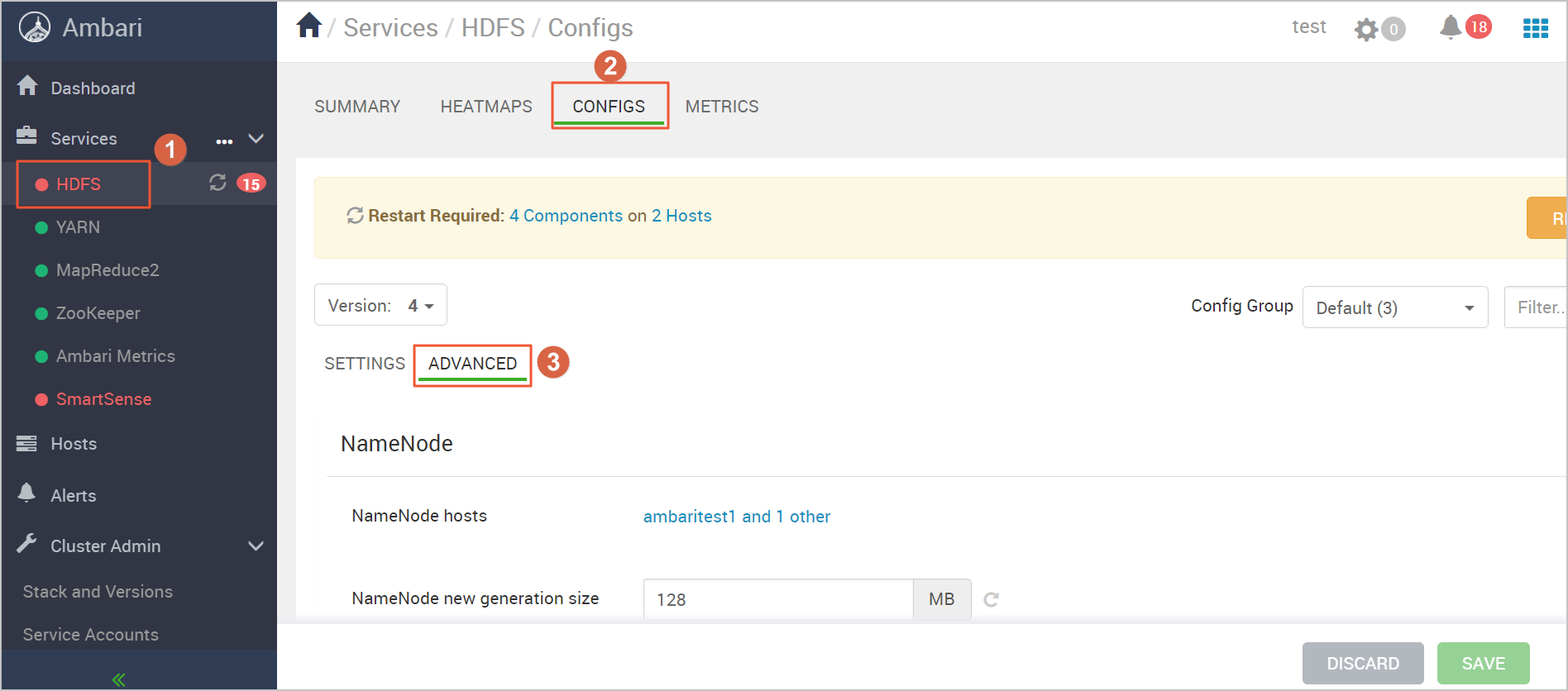
- 原HDFS采用HA模式(HDFS NameNode主备模式)部署,如果原HDFS非HA模式部署,请将其初始化为HA模式。
- 找到Custom hdfs-site区块,单击Custom hdfs-site>Add Property。配置Lindorm文件引擎配置项Key、Value、Property Type参数值如下:
Key Value Property Type 描述 dfs.client.failover.proxy.provider.{实例Id} org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider TEXT 无 dfs.ha.namenodes.{实例Id} nn1、nn2 TEXT HA模式下主备 NameNode的服务ID名称 dfs.namenode.rpc-address.{实例Id} {实例Id}-master1-001.lindorm.rds.aliyuncs.com:8020 TEXT 无 dfs.namenode.rpc-address.{实例Id} {实例Id}-master2-001.lindorm.rds.aliyuncs.com:8020 TEXT 无 dfs.nameservices {实例Id} TEXT 无 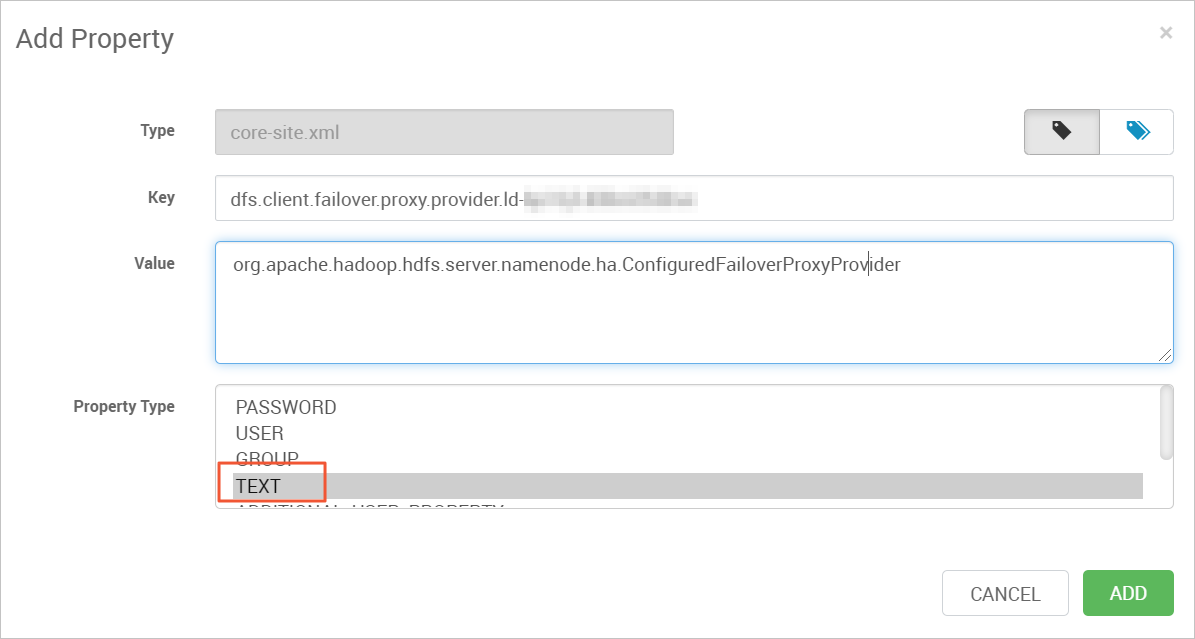
- 单击ADD完成配置。
- 登录Ambari管理系统,单击左侧导航栏HDFS>CONFIGS >ADVANCED,进入HDFS配置页面。
- 配置Ambari默认访问Lindorm文件引擎。
- 登录Ambari管理系统,单击左侧导航栏HDFS>CONFIGS >ADVANCED,进入HDFS配置页面。

- 找到Advanced core-site区块,修改fs.defaultFS配置项为您文件引擎的HDFS连接串,获取该连接串请参见开通指南。

- 修改hdfs-site配置文件。
- 在Ambari管理系统主页面,单击HDFS > CONFIGS > ADVANCED ,找到Custom hdfs-site区块。
- 修改配置项dfs.internal.nameservices值为实例Id。
- 添加配置项dfs.namenode.http-address.{实例Id}.nn1,设置参数值:
{实例Id}-master1-001.lindorm.rds.aliyuncs.com:50070。 - 添加配置项dfs.namenode.http-address.{实例Id}.nn2,设置参数值:
{实例Id}-master2-001.lindorm.rds.aliyuncs.com:50070。
- 单击SAVE保存修改。
- 单击页面右上角ACTIONS>Restart All,重启HDFS。重要 该步骤是为了将修改后的配置信息分发到Ambari的各个节点上,并且由于配置已经被修改,HDFS启动会失败,直接将服务关闭即可。验证Ambari群能否成功访问文件引擎。在Ambari集群中的任意节点上执行如下指令。若返回结果如下,则表示链接配置成功。
- 单击页面右上角ACTIONS>Stop,关闭HDFS。
- 登录Ambari管理系统,单击左侧导航栏HDFS>CONFIGS >ADVANCED,进入HDFS配置页面。
- 验证Ambari集群是否成功访问文件引擎。
- 在 Ambari集群中任意节点上执行如下指令。
$ hadoop fs -ls / - 执行结果如下,表示链接配置成功。
 重要 如果验证时发现配置没有生效,可以在Ambari管理系统页面右上角单击ACTIONS>Restart All来重新启动HDFS,然后再单击Stop关闭HDFS,配置即可生效。
重要 如果验证时发现配置没有生效,可以在Ambari管理系统页面右上角单击ACTIONS>Restart All来重新启动HDFS,然后再单击Stop关闭HDFS,配置即可生效。
- 在 Ambari集群中任意节点上执行如下指令。
- 若当前已经启动的各个组件的状态如下图,则底层的文件引擎已经替换成功。

安装YARN服务
- 登录Ambari管理系统,单击Services旁边的
 图标,单击Add Service,并将YARN+MapReduce2选项打钩。
图标,单击Add Service,并将YARN+MapReduce2选项打钩。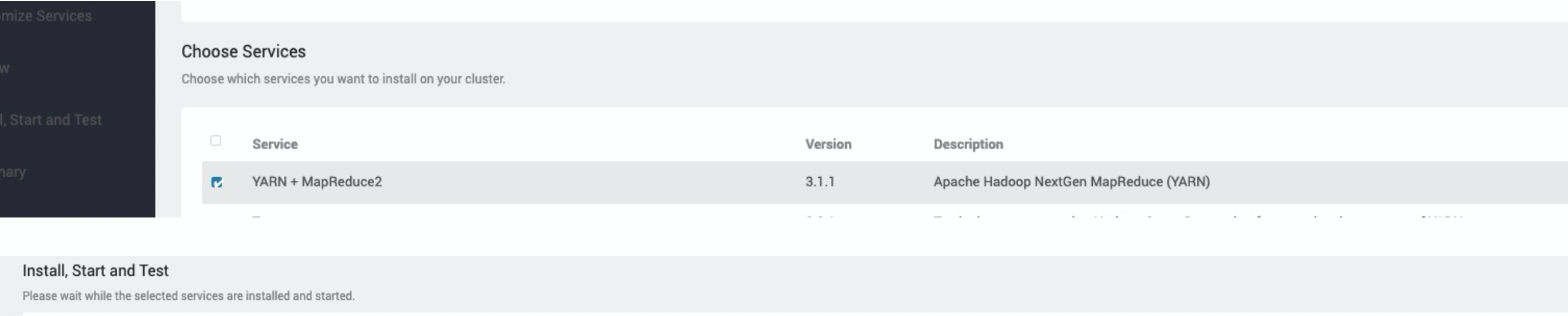
- 在Add Service Wizard页面按照安装向导安装YARN服务,配置完成后单击DEPLOY进行安装,等待安装完成。
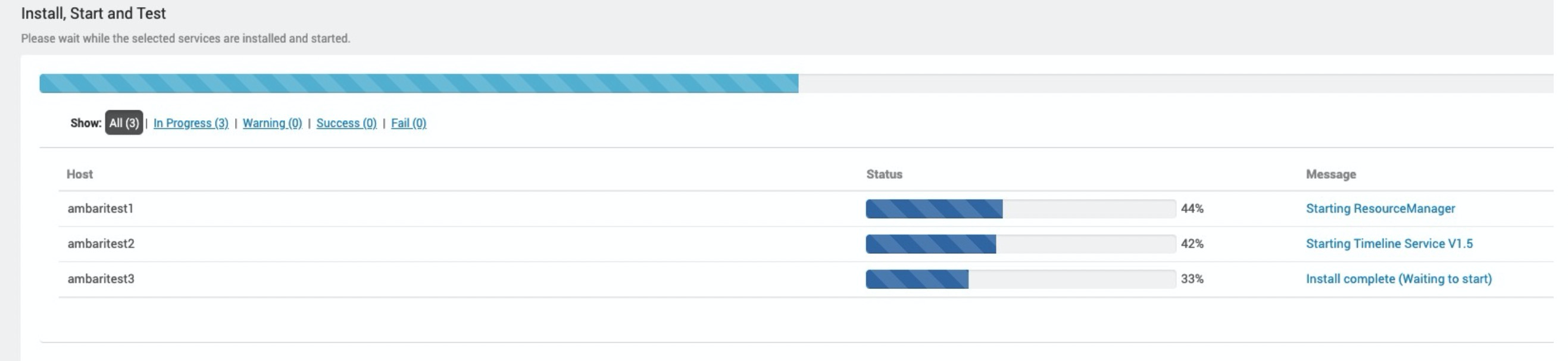
- 验证YARN服务是否启动成功。
使用Ambari Hadoop中自带的测试包
hadoop-mapreduce-examples-3.1.1.3.1.4.0-315.jar进行测试。在Ambari中,该测试包在usr/hdp/3.1.4.0-315/hadoop-mapreduce目录下。- 登入Ambari任意机器,执行以下命令,在/tmp/randomtextwriter 目录下生成128M大小的测试文件。
$ yarn jar /usr/hdp/3.1.4.0-315/hadoop-mapreduce/hadoop-mapreduce-examples-3.1.1.3.1.4.0-315.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=134217728 -D mapreduce.job.maps=4 -D mapreduce.job.reduces=4 /tmp/randomtextwriter说明 其中hadoop-mapreduce-examples-3.1.1.3.1.4.0-315.jar为Ambari中的测试包,请根据实际情况修改。 - 检查任务是否已经提交到YARN服务上执行。在Ambari任意机器执行以下命令。
$ yarn application -list如果返回结果如下,则表示YARN服务正常运行。
- 登入Ambari任意机器,执行以下命令,在/tmp/randomtextwriter 目录下生成128M大小的测试文件。
安装Hive服务
- 登录Ambari管理系统,单击Services旁边的图标,单击Add Service,并将Hive选项打钩。

- 在Add Service Wizard页面按照安装向导安装Hive服务,配置完成后单击DEPLOY进行安装,等待安装完成。
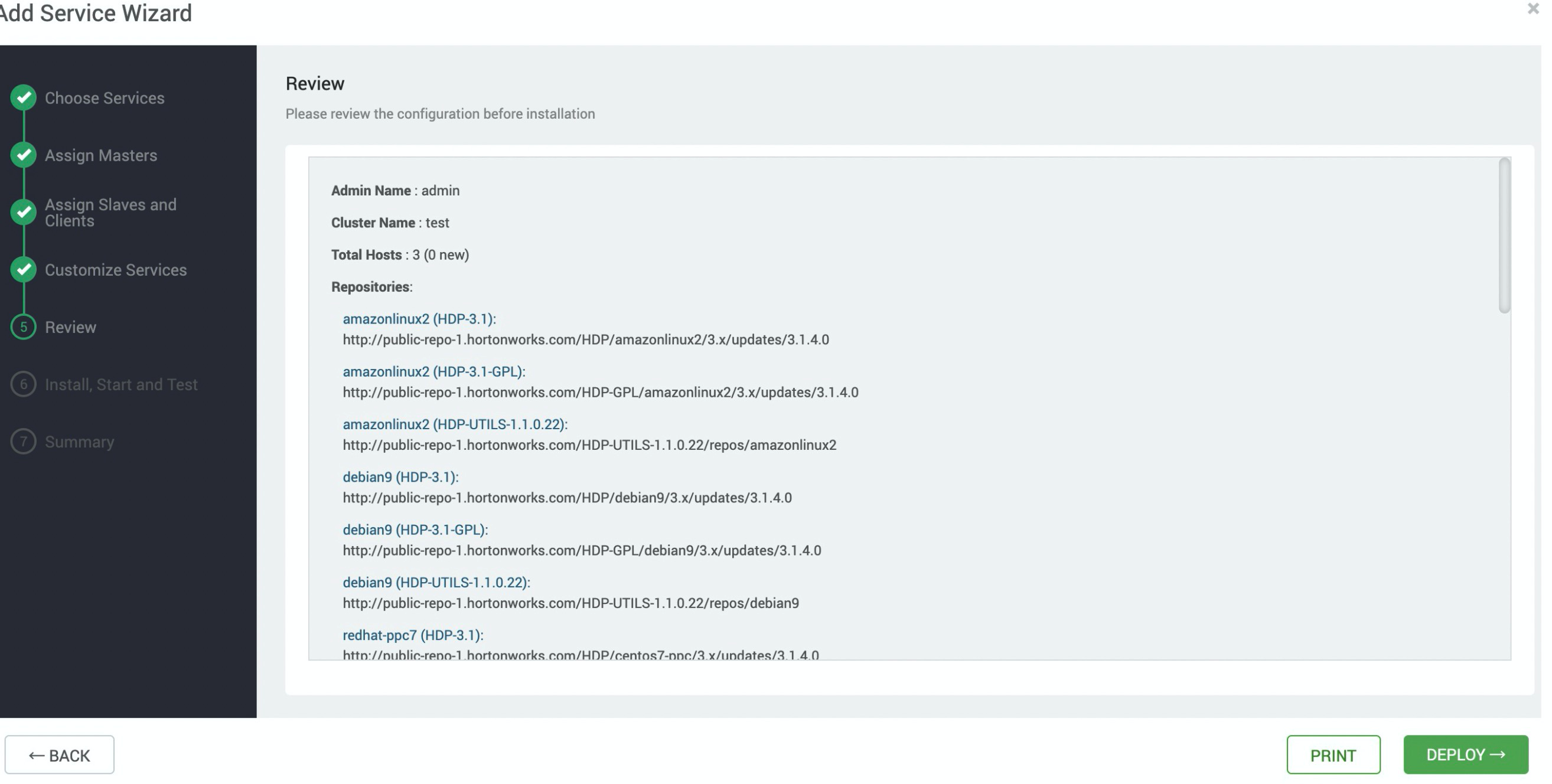
- 如下页面表示安装成功。
- 设置proxyuser代理。由于Hive是通过proxyuser代理方式访问文件引擎,所以我们提前先配置了一些常用用户的proxy访问权限,如Hive、spark等。当您有其他用户需要添加的时候,可以咨询技术支持帮您手动添加。
- 重启YARN服务。由于Hive为了加速任务的执行而使用Tez组件,而Tez组件依赖于YARN服务,因此在安装Hive时Ambari会添加部分YARN的配置,为了是配置可以生效您需要重启YARN服务。
单击左侧导航栏的YARN服务,单击页面右上角ACTIONS>Restart All,重启 YARN服务 。
- 验证Hive服务是否成功启动。
- 登入Ambari任意机器,执行以下命令。
# su - hive # 登入 hive 客户端 hive@ambaritest2 ~]$ hive Beeline version 3.1.0.3.1.4.0-315 by Apache Hive 0: jdbc:hive2://ambaritest1:2181,ambaritest2:> create table foo (id int, name string); INFO : Compiling command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49): create table foo (id int, name string) INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null) INFO : Completed compiling command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49); Time taken: 1.337 seconds INFO : Executing command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49): create table foo (id int, name string) INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49); Time taken: 0.814 seconds INFO : OK No rows affected (2.596 seconds) 0: jdbc:hive2://ambaritest1:2181,ambaritest2:> insert into table foo select * from (select 12,"xyz")a; # su - hive # 登入 hive 客户端 hive@ambaritest2 ~]$ hive Beeline version 3.1.0.3.1.4.0-315 by Apache Hive 0: jdbc:hive2://ambaritest1:2181,ambaritest2:> create table foo (id int, name string); INFO : Compiling command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49): create table foo (id int, name string) INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null) INFO : Completed compiling command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49); Time taken: 1.337 seconds INFO : Executing command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49): create table foo (id int, name string) INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=hive_20201111193943_5471ede8-e51f-44b8-a91a-b6fde9f58b49); Time taken: 0.814 seconds INFO : OK No rows affected (2.596 seconds) 0: jdbc:hive2://ambaritest1:2181,ambaritest2:> insert into table foo select * from (select 12,"xyz")a; - 执行以下命令,查询Hive上的数据。
0: jdbc:hive2://ambaritest1:2181,ambaritest2:> select * from foo;若返回结果如下,则表示Hive服务安装并启动成功。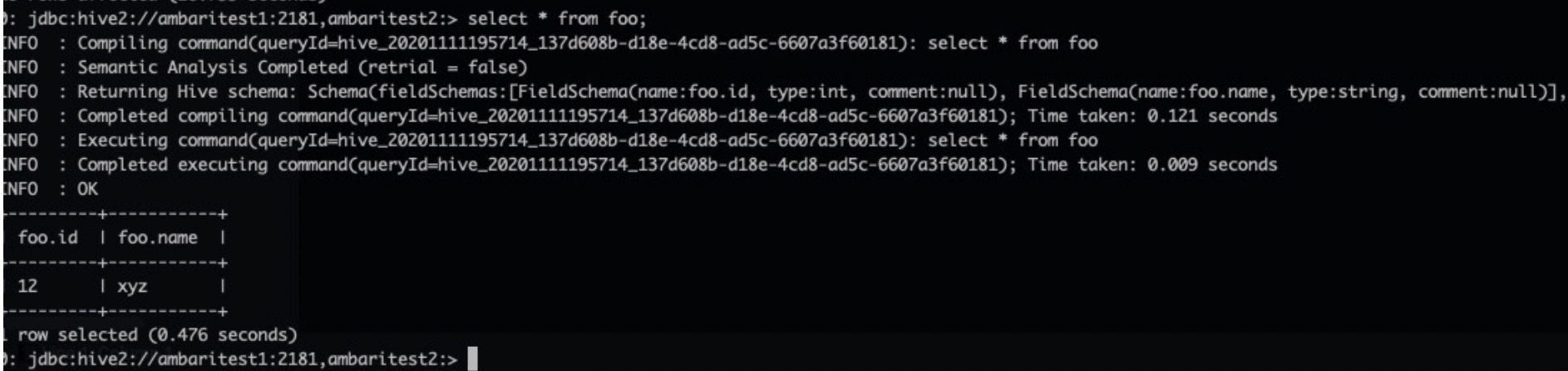
- 登入Ambari任意机器,执行以下命令。
安装Spark服务
- 登录Ambari管理系统,单击Services旁边的图标,单击Add Service,并将Spark2选项打钩。

- 按照安装向导,安装Spark2服务,配置完后单击DEPLOY进行安装,等待安装完成。
- 验证Spark是否启动成功。
使用Ambari spark中自带的测试包
spark-examples_2.11-x.x.x.x.x.x.0-315.jar进行测试。在Ambari中,该测试包在/usr/hdp/3.1.4.0-315/spark2/examples/jars/下。- 登入Ambari任意机器,执行以下命令,在/tmp/randomtextwriter目录下生成128M大小的测试文件,如果之前已经生成请跳过该步骤。
$ yarn jar /usr/hdp/3.1.4.0-315/hadoop-mapreduce/hadoop-mapreduce-examples-3.1.1.3.1.4.0-315.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=134217728 -D mapreduce.job.maps=4 -D mapreduce.job.reduces=4 /tmp/randomtextwriter说明 其中hadoop-mapreduce-examples-3.1.1.3.1.4.0-315.jar为Ambari中的测试包,请根据实际情况进行修改。 - 登入Ambari任意机器,执行以下命令,使用spark测试包从文件引擎上读取测试文件并输出word count程序运行结果。
$ spark-submit --master yarn --executor-memory 2G --executor-cores 2 --class org.apache.spark.examples.JavaWordCount /usr/hdp/3.1.4.0-315/spark2/examples/jars/spark-examples_2.11-2.3.2.3.1.4.0-315.jar /tmp/randomtextwriter若任务运行结果如下图所示,则表示Spark启动成功。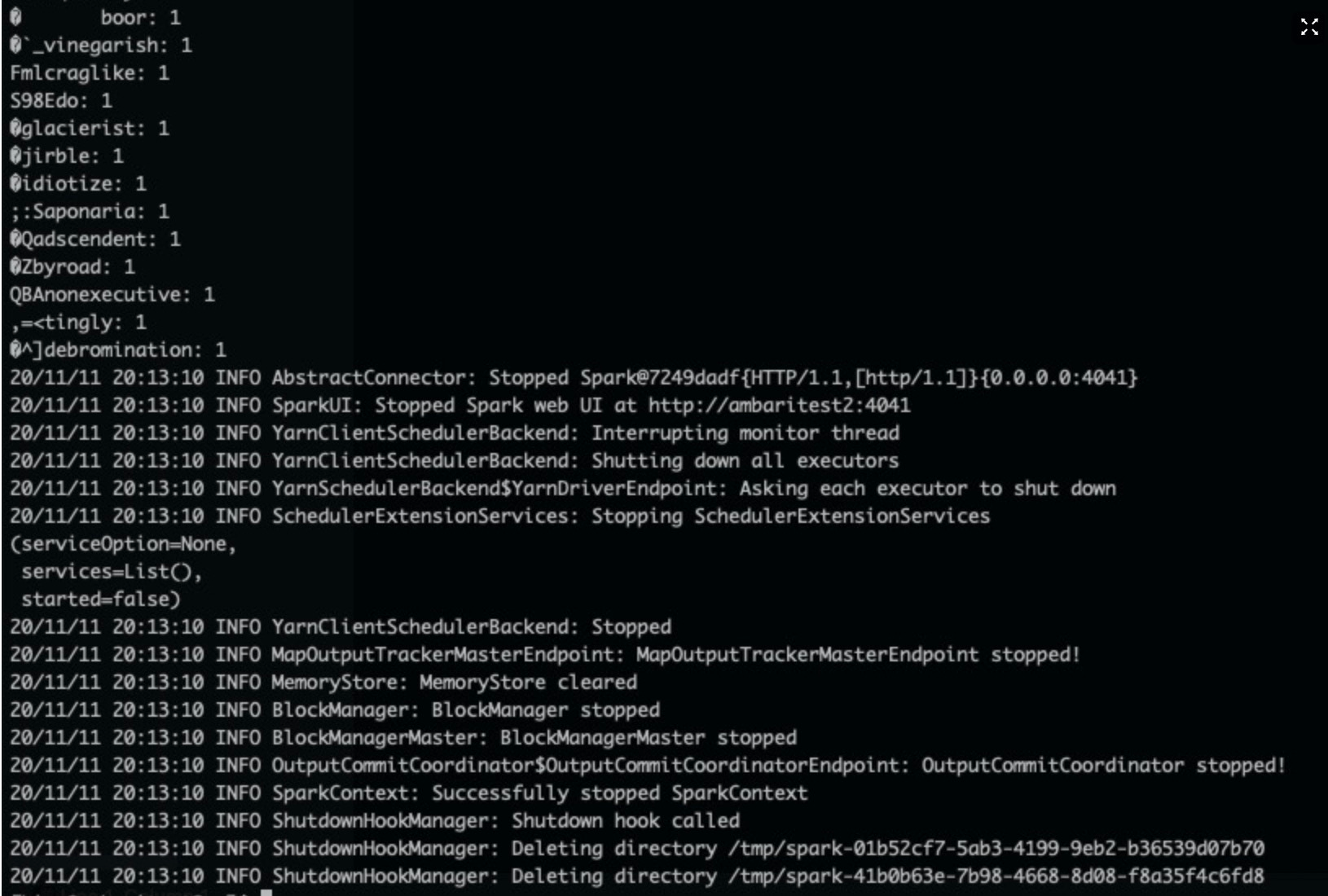
- 登入Ambari任意机器,执行以下命令,在/tmp/randomtextwriter目录下生成128M大小的测试文件,如果之前已经生成请跳过该步骤。
安装Hbase服务
- 登录Ambari管理系统,单击Services旁边的图标,单击Add Service,并将Hbase选项打钩。

- 按照安装向导,安装Hbase服务,配置完后单击DEPLOY进行安装,等待安装完成。
- 验证Hbase服务是否启动成功。
- 登入Ambari任意机器,执行以下命令进入hbase Shell命令界面。
[spark@ambaritest1 ~]$ hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hdp/3.1.4.0-315/phoenix/phoenix-5.0.0.3.1.4.0-315-server.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hdp/3.1.4.0-315/hadoop/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.0.2.3.1.4.0-315, r, Fri Aug 23 05:15:48 UTC 2019 Took 0.0023 seconds hbase(main):001:0> - 执行以下命令,在HBase中创建测试表。
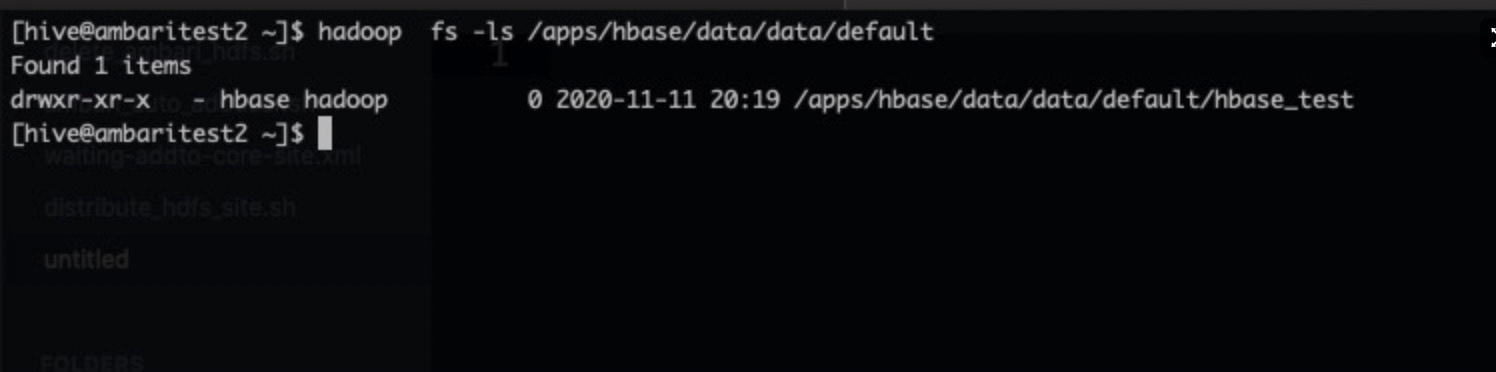
[hive@ambaritest2 ~]$ hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hdp/3.1.4.0-315/phoenix/phoenix-5.0.0.3.1.4.0-315-server.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hdp/3.1.4.0-315/hadoop/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.0.2.3.1.4.0-315, r, Fri Aug 23 05:15:48 UTC 2019 Took 0.0023 seconds hbase(main):001:0> create 'hbase_test','info' Created table hbase_test Took 1.9513 seconds => Hbase::Table - hbase_test hbase(main):002:0> put 'hbase_test','1', 'info:name' ,'Sariel' Took 0.2576 seconds hbase(main):003:0> put 'hbase_test','1', 'info:age' ,'22' Took 0.0078 seconds hbase(main):004:0> put 'hbase_test','1', 'info:industry' ,'IT' Took 0.0077 seconds hbase(main):005:0> scan 'hbase_test' ROW COLUMN+CELL 1 column=info:age, timestamp=1605097177701, value=22 1 column=info:industry, timestamp=1605097181758, value=IT 1 column=info:name, timestamp=1605097174400, value=Sariel 1 row(s) Took 0.0230 seconds hbase(main):006:0> - 执行以下命令查看文件引擎的/apps/hbase/data/data/default路径,如果/apps/hbase/data/data/default路径下有hbase_test目录,则证明配置链接成功。
- 登入Ambari任意机器,执行以下命令进入hbase Shell命令界面。
安装其他服务
其他服务的安装和上面服务的安装基本类似,安装过程可以查考上述步骤进行安装。