本章节介绍如何使用DataWorks实现MaxCompute与文件引擎之间的双向数据同步。您可以将MaxCompute数据同步至文件引擎,也可以将文件引擎的数据同步至MaxCompute。
说明 请确保Maxcompute、文件引擎、Dataworks在同一个地域(region)下。
准备工作
- 开通文件引擎,详情请参见开通指南。
- 开通MaxCompute,详情请参见开通MaxCompute。
- 开通DataWorks,详情请参见入门概述。
配置步骤
- 配置DataWorks独享数据集成资源组。开通配置及使用步骤请参见购买独享资源,并且注意以下几方面配置。
- 配置数据同步任务。
配置数据任务的步骤请参见通过向导模式配置任务,详细参数设置如下:
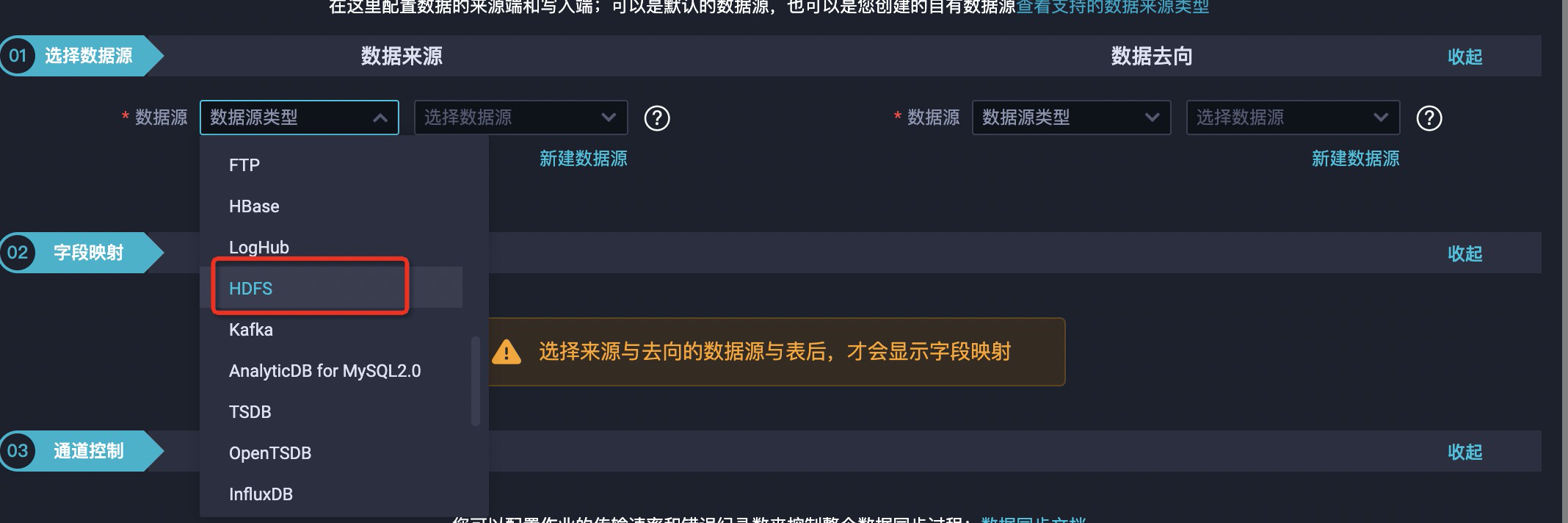
- 配置数据走向。
如果配置从MaxCompute数据同步到文件引擎时,配置的数据去向的数据源为HDFS 。
 如果配置从文件引擎同步数据到MaxCompute时,配置的数据来源的数据源为HDFS。
如果配置从文件引擎同步数据到MaxCompute时,配置的数据来源的数据源为HDFS。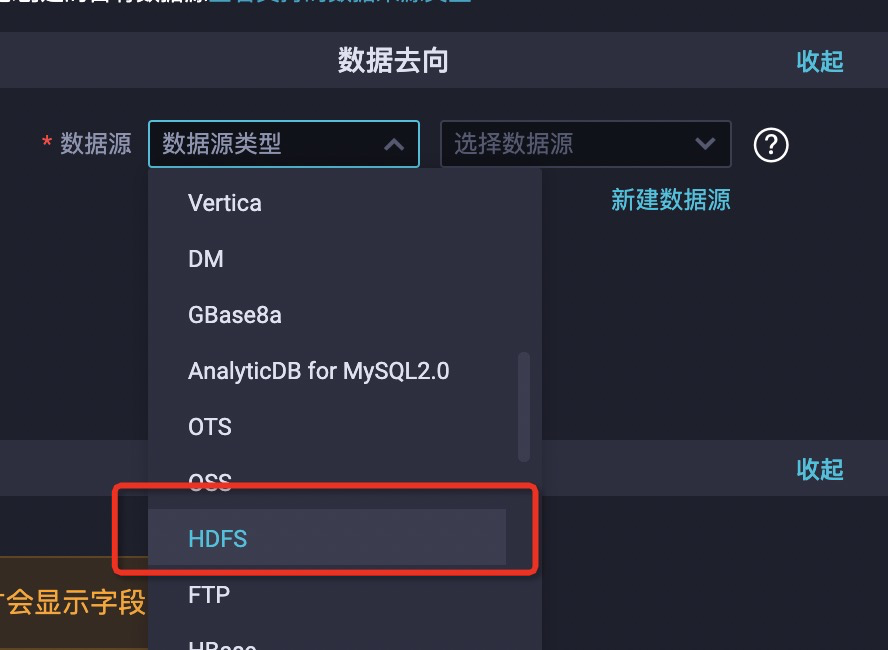
- 根据提示使用脚本模式配置同步任务。
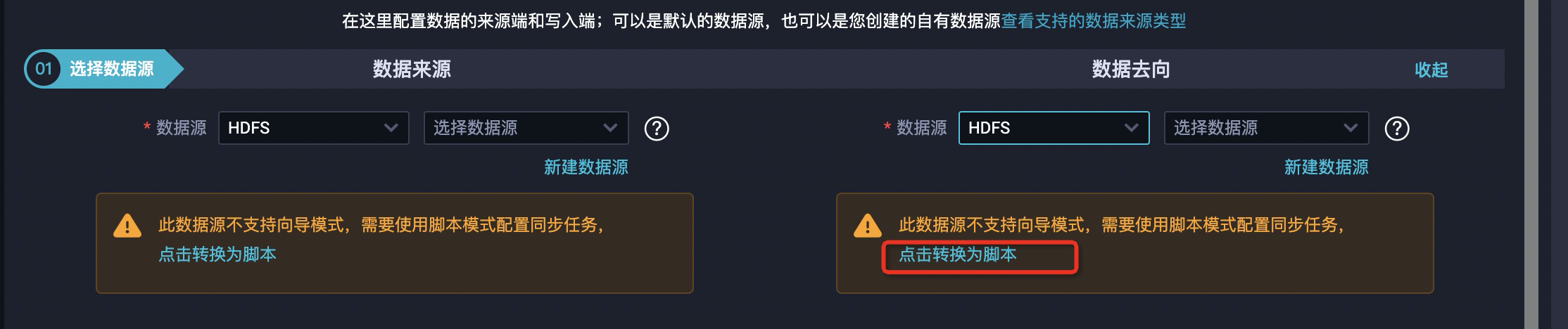
- 在配置脚本中,添加文件引擎配置参数。
- 同步数据到文件引擎时,需要配置HDFS Writer,详情请参见配置HDFS Writer。
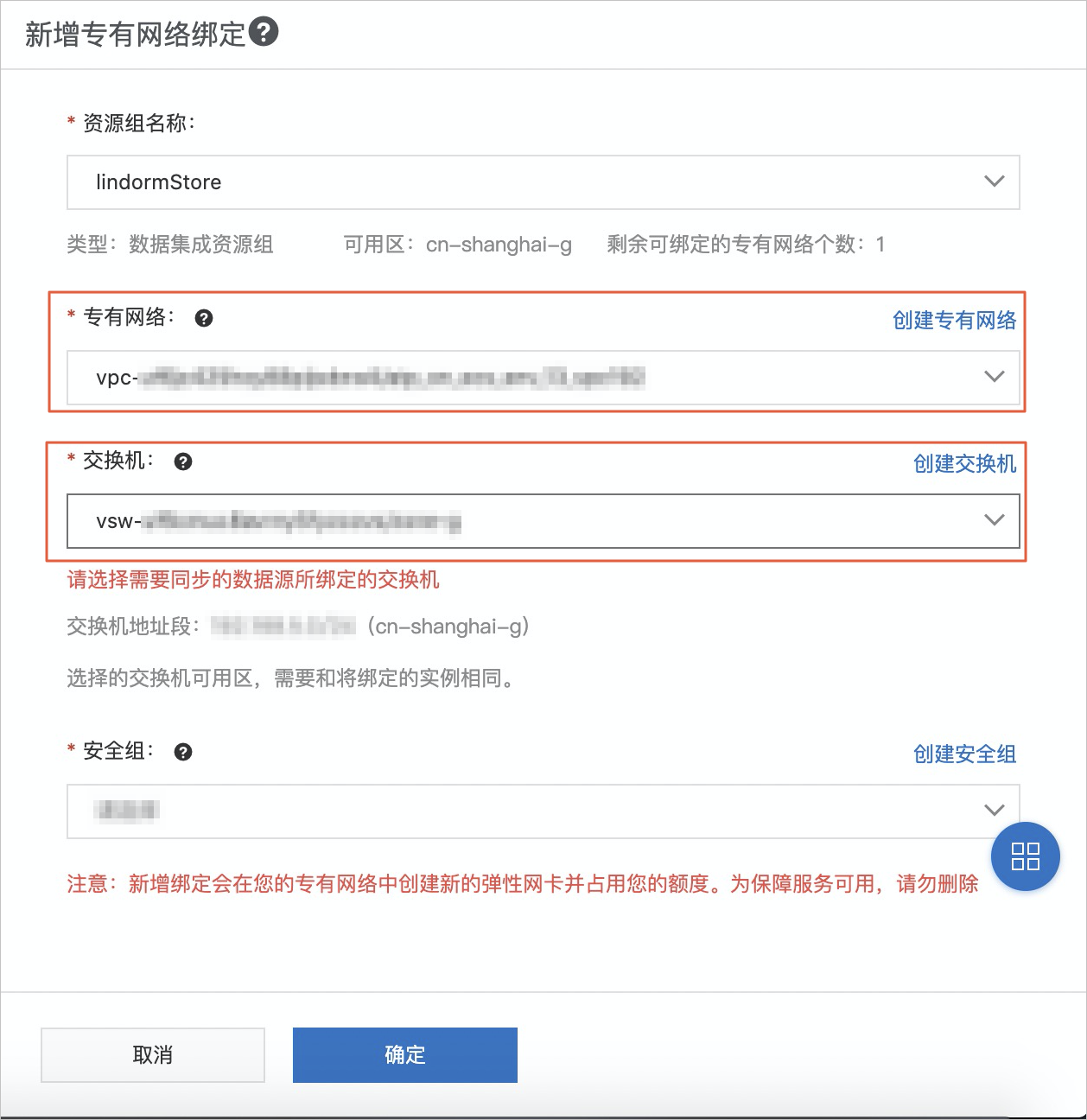
- 从文件引擎同步数据时,需要配置HDFS Reader,详情请参见配置HDFS Reader。在配置HDFS Writer和HDFS Reader时,需要指定数据源,数据源配置详见:配置HDFS数据源,目前该数据源仅支持独享数据集成资源组,所以在配置之前需要先配置独享数据集成资源组,如下图所示。
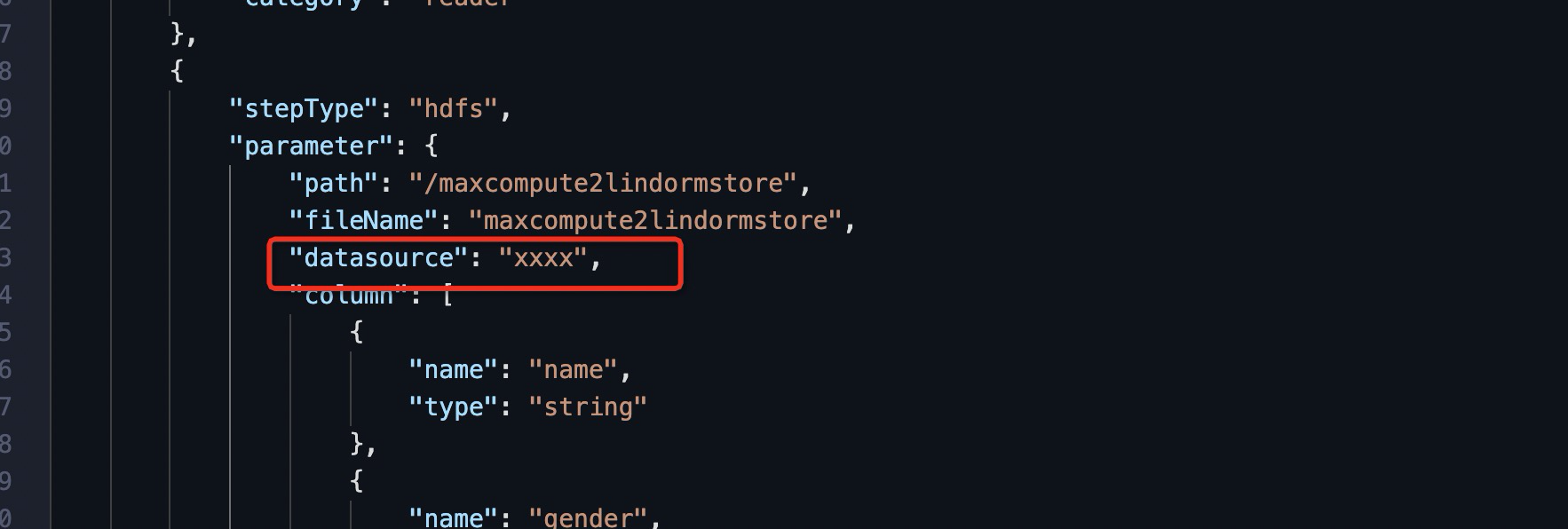
xxxx 是前面已经配置完成的数据源。
说明- 由于MaxCompute默认资源组不支持Hadoop高级参数HA的配置,如果想通过HA的模式访问文件引擎,那么请新增自定义资源,详情请参见文档新增和使用自定义数据集成资源组,并且在数据源中配置对应的 defaultFS 和 hadoopConfig 配置需要的信息都可以在文件引擎控制界面上,通过一键生成配置按钮查看。
- 如果在创建数据源的时候出现网络超时的报错可以根据配置资源组与网络连通进行解决,如果还是有问题,可以提交工单联系DataWorks工作人员获取支持。
- 配置数据走向。
验证MaxCompute数据同步至文件引擎
以下示例用来验证MaxCompute数据是否同步到文件引擎上。
- 在MaxCompute中创建测试表。详情请参见创建表。
CREATE TABLE IF NOT EXISTS maxcompute2lindormstore ( name STRING COMMENT '姓名', gender STRING COMMENT '性别', age INT COMMENT '年龄', ); - 在测试表中插入测试数据。
insert into maxcompute2lindormstore values('测试用户1','男',20); insert into maxcompute2lindormstore values('测试用户2','男',20); insert into maxcompute2lindormstore values('测试用户3','女',20); insert into maxcompute2lindormstore values('测试用户4','女',20); - 在文件存储HDFS上创建目录。
hadoop fs -mkdir hdfs://${实例ID}/maxcompute2lindormstore其中${实例ID} 表示为LindormStore的实例ID。
- 在DataWorks中编写数据同步脚本。
配置MaxCompute Reader和HDFS Writer脚本,详情请参见配置MaxCompute Reader和配置HDFS Writer。
{ "type": "job", "steps": [ { "stepType": "odps", "parameter": { "partition": [], "datasource": "odps_first", "column": [ "*" ], "emptyAsNull": false, "table": "maxcompute2lindormstore" }, "name": "Reader", "category": "reader" }, { "stepType": "hdfs", "parameter": { "path": "/maxcompute2lindormstore", "fileName": "maxcompute2lindormstore", "datasource": "xxxx", "column": [ { "name": "name", "type": "string" }, { "name": "gender", "type": "string" }, { "name": "age", "type": "int" } ], "writeMode": "append", "encoding": "UTF-8", "fieldDelimiter": ",", "fileType": "text" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 2 } } } { "type": "job", "steps": [ { "stepType": "odps", "parameter": { "partition": [], "datasource": "odps_first", "column": [ "*" ], "emptyAsNull": false, "table": "maxcompute2lindormstore" }, "name": "Reader", "category": "reader" }, { "stepType": "hdfs", "parameter": { "path": "/maxcompute2lindormstore", "fileName": "maxcompute2lindormstore", "datasource": "xxxx", "column": [ { "name": "name", "type": "string" }, { "name": "gender", "type": "string" }, { "name": "age", "type": "int" } ], "writeMode": "append", "encoding": "UTF-8", "fieldDelimiter": ",", "fileType": "text" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 2 } } } - 加载创建的独享数据集成资源组并执行数据脚本。
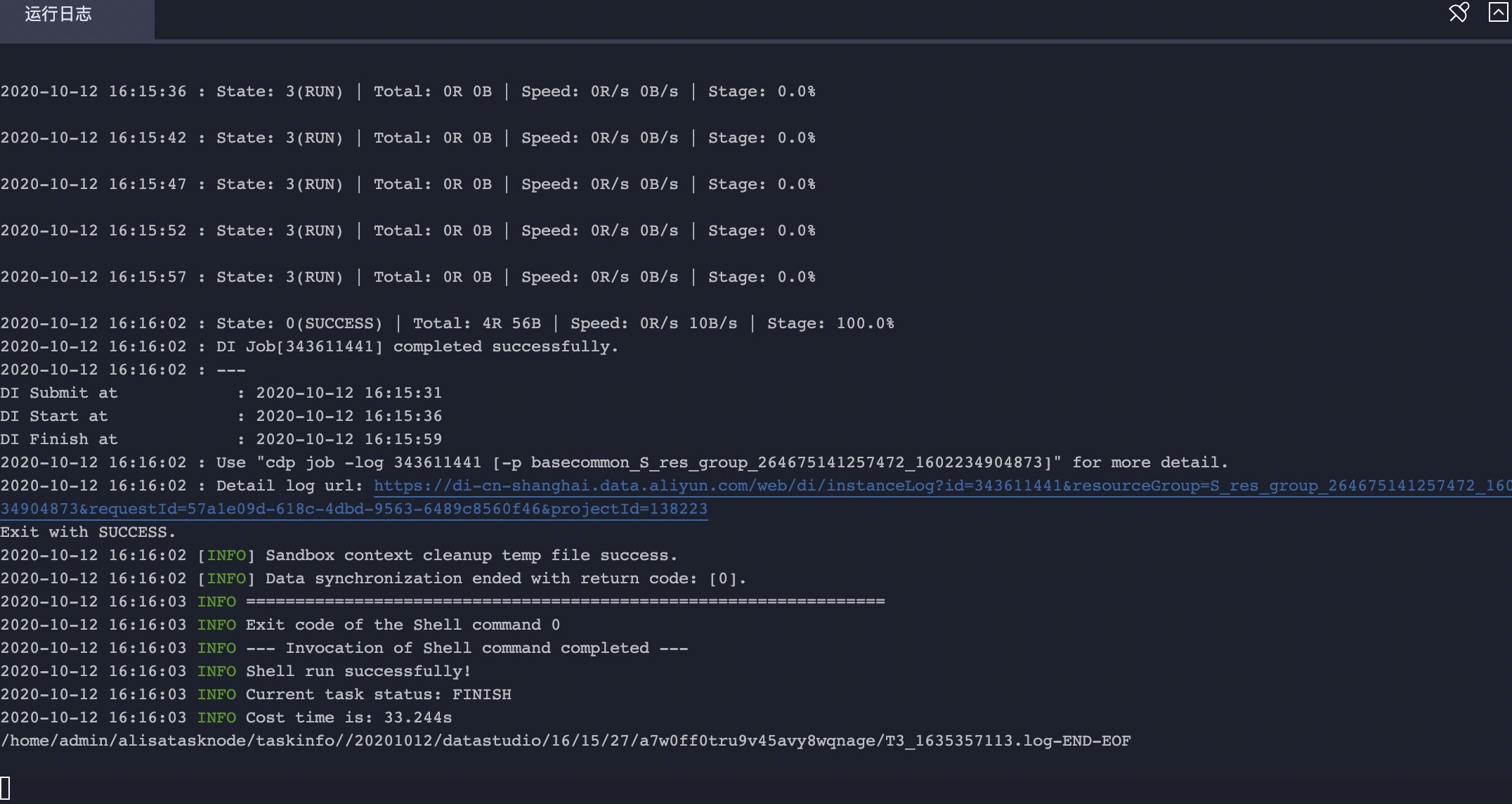
- 查看MaxCompute是否成功同步数据到文件引擎。
hadoop fs -cat /maxcompute2lindormstore/*
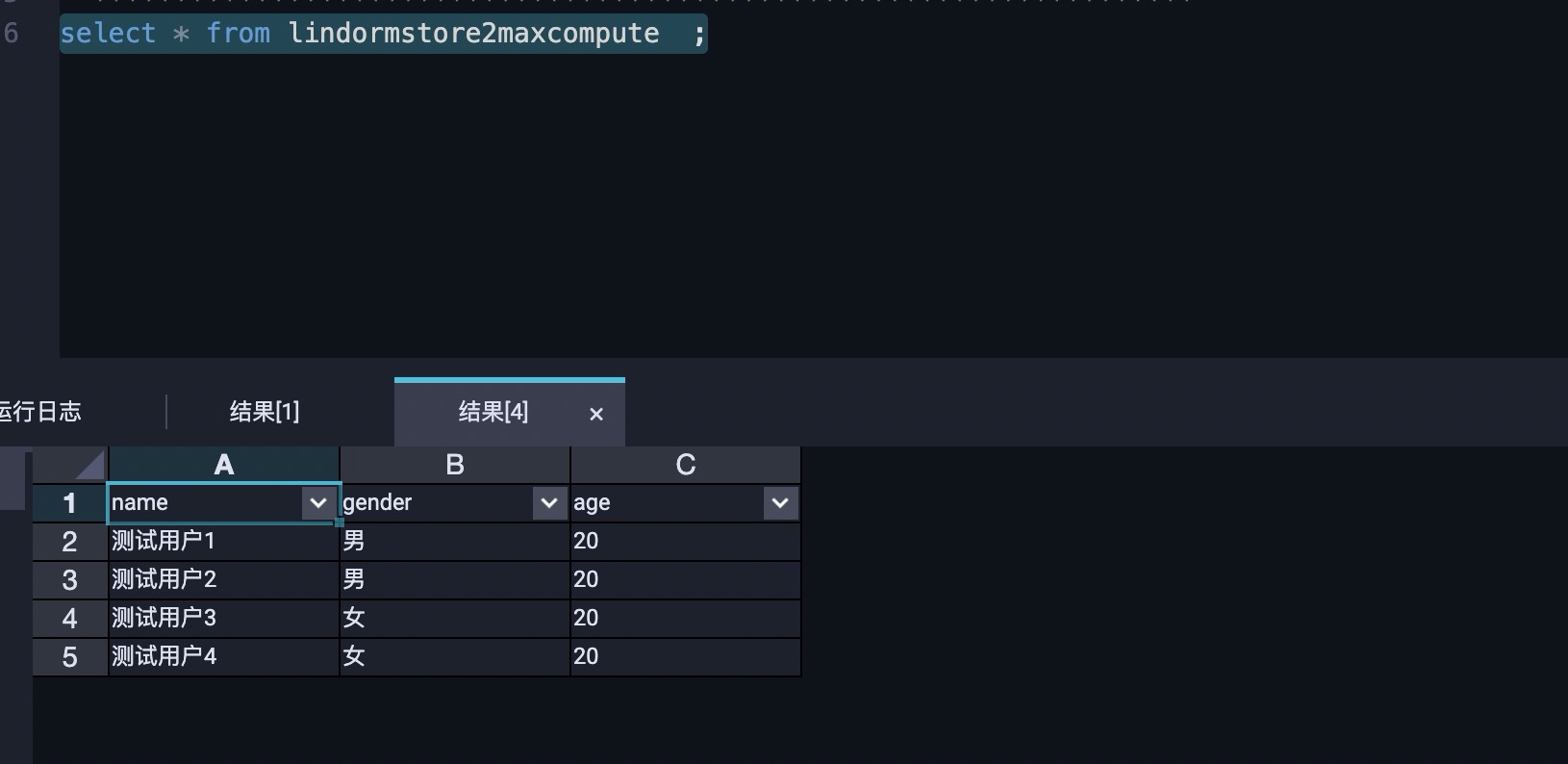
验证文件引擎数据同步至MaxCompute
以下示例用来验证文件引擎数据是否同步到了MaxCompute上。
说明 在验证文件引擎数据同步到MaxCompute中时,文件引擎上的测试数据是使用验证MaxCompute数据同步至文件引擎中由MaxCompute同步过去的数据,将该数据再同步到MaxCompute的另外一张表中。
- 在MaxCompute中创建新的测试表。详情请参见在MaxCompute创建表。
CREATE TABLE IF NOT EXISTS lindormstore2maxcompute ( name STRING COMMENT '姓名', gender STRING COMMENT '性别', age INT COMMENT '年龄' ); - 在DataWorks中编写数据同步脚本。配置MaxCompute Reader和HDFS Writer脚本,详情请参见配置MaxCompute Reader和配置HDFS Writer。
{ "type": "job", "steps": [ { "stepType": "hdfs", "parameter": { "path": "/maxcompute2lindormstore", "fileName": "maxcompute2lindormstore*", "datasource": "xxxx", "column": [ { "index": 0, "type": "string" }, { "index": 1, "type": "string" }, { "index": 2, "type": "long" } ], "encoding": "UTF-8", "fieldDelimiter": ",", "fileType": "text" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter":{ "partition":"", "truncate":true, "compress":false, "datasource":"odps_first", "column": [ "name", "gender", "age" ], "guid": null, "emptyAsNull": false, "table": "lindormstore2maxcompute" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false } } } - 加载创建的独享数据集成资源组并执行数据脚本。
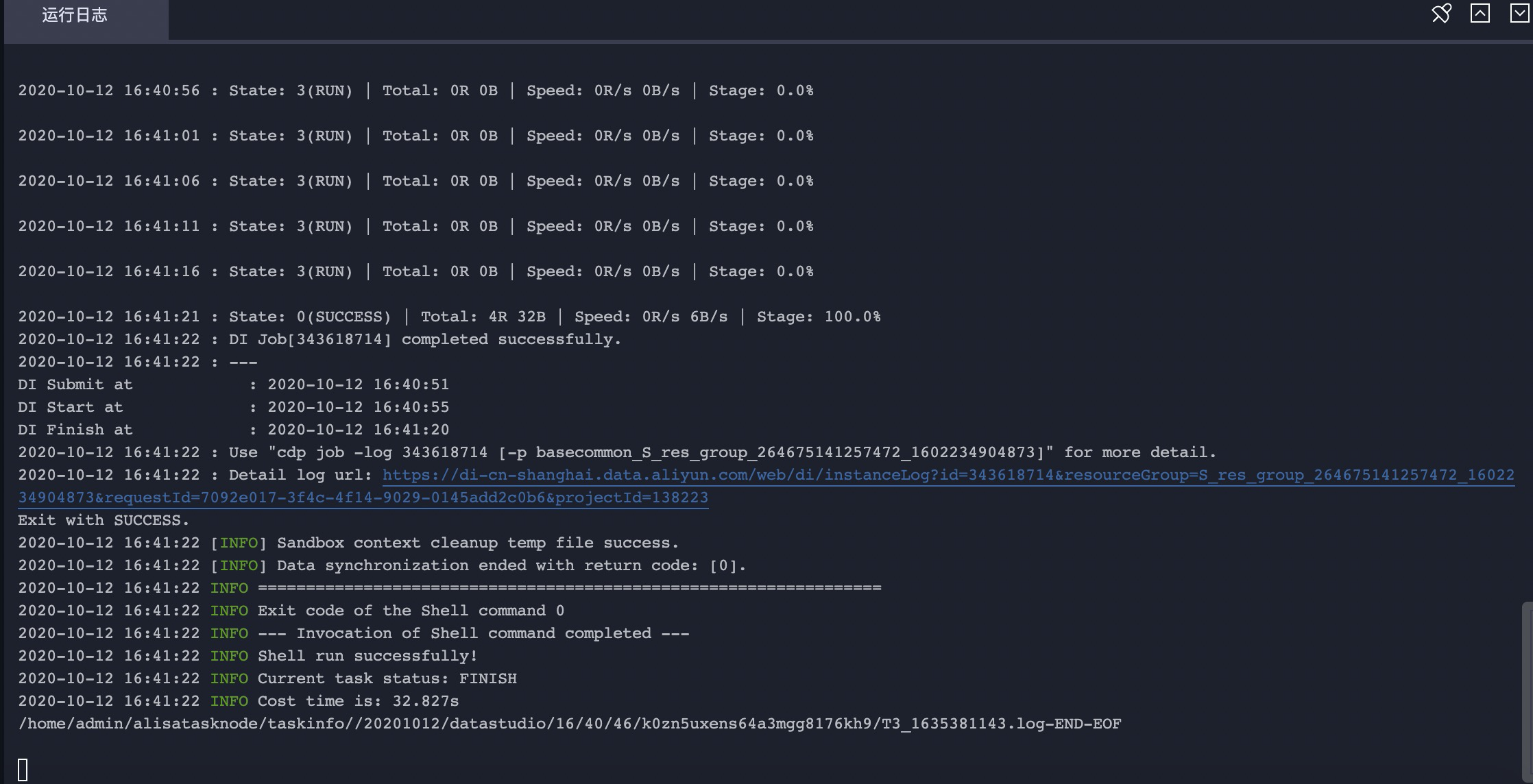
- 查看文件引擎的数据是否成功同步数据到MaxCompute。