SQL限流是限制数据库上执行SQL的并发度,通过限制问题SQL的并发度后,保障数据库正常响应业务请求,保障大部分的业务正常运转,即通过小部分业务受损,保障大部分业务正常运行。
背景信息
随着技术的发展,尤其是云数据库的普及,数据库系统变得越来越稳定,运维工作也越来越轻松,版本升级、实例迁移等都可以自动完成,上层业务不会有太大的感知。即使硬件设备或者网络出现故障,巡检系统也可以快速迁移、及时重启,保证服务稳定。但现有的这些手段几乎都是针对服务端的稳定性保证,来自业务端的异常使用造成的问题还需要人工介入处理,比如业务变化中引入了新的慢SQL,突然涌入的洪峰等。这些业务层面的异常发生时,上述的运维手段几乎都不能快速处理异常,防止系统崩溃。
问题
- 流量问题:突发的流量急剧上升,影响正常业务,比如缓存穿透、异常调用、大促等等,造成原来并发不大的SQL,并发量突然上升。
- 数据问题:有数据倾斜的SQL,影响正常业务,例如订单数据中存在大账号,查询该账号的相关SQL拖慢数据库。
- SQL问题:资源消耗型SQL,俗称为“烂SQL”,影响正常业务,比如新上线SQL调用量特别大,又没有创建索引,造成整体系统繁忙。
用户问题
- 怎么能够在异常发生的时候,及时发现异常?
- 发现异常后,怎么识别需要限流的SQL?
- 怎么提取限流SQL的关键字,既能帮助业务恢复正常,又保障业务的受损最小?
- 限流执行后,怎么快速确认执行的限流操作是正确的?
除了上述的问题,在现实生活中可能还会出现各种特殊情况,比如值班人员联系不上、工作人员身边没有电脑、信息太多分析难度大、压力大紧张操作失误等。
因此需要尽可能的把异常发现、异常SQL定位、SQL限流、跟踪/回滚的整体流程自动化处理。
说明 自动SQL限流的解决方案应运而生,该服务已经在阿里巴巴集团内部运行了2年多,并且在2020年2月在阿里云上发布,您可以在数据库自治服务DAS进行体验和使用。
解读
整体流程:
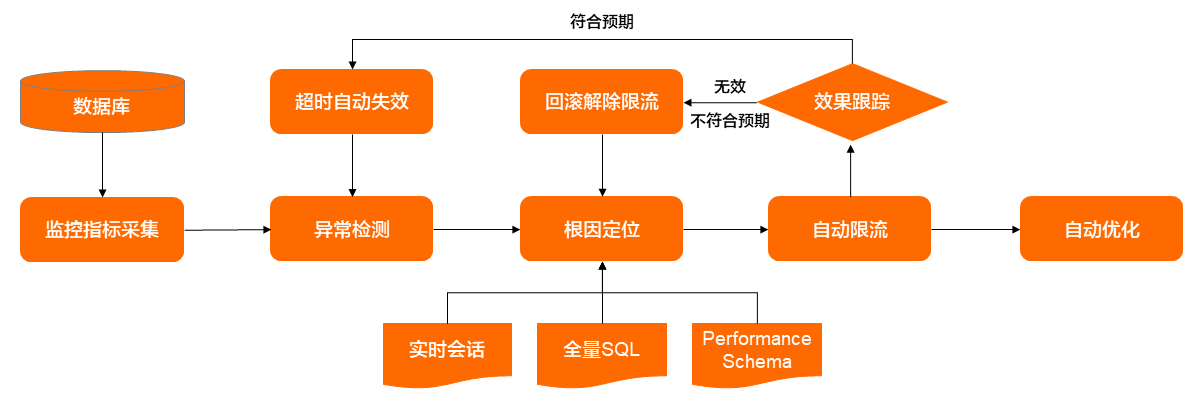
- 监控指标采集:在阿里云申请的RDS实例默认开启主机和引擎的性能指标采集,包括CPU,IOPS,QPS,活跃会话等,这些实时数据是后续所有分析和处理的基础。
- 异常检测:该模块通过机器学习对实例历史性能数据进行离线训练获得相关模型,然后利用该模型对实时指标数据进行异常检测,相比基于阈值的告警,能够更及时的发现异常,该部分的内容将在后续的系列文章中进行详细介绍。
- 根因定位:该模块会订阅实例上的异常事件,并采集异常时刻的会话信息,然后结合SQL审计中的全量SQL,performance_schema中的统计信息进行判断,找出实例异常的原因。我们将根因分为四种场景:
- 阻塞型SQL:DAS会利用实时会话,锁等待,运行中的事务等进行分析,分析是否存在DDL变更,大事务,锁等待等场景,同时判断被影响会话的数量和执行时间,如果影响的会话比较多或者执行时间很长,那这不需要通过限流来解决问题,而是终止异常会话。
- 资源消耗型SQL,俗称为“烂SQL”:该场景中,可能SQL的并发不大,但是消耗大量的CPU或者IO或者网络资源,并且被持续不断的被提交。
- 流量型SQL :大量正常SQL同时在数据库中运行,触发数据库的资源瓶颈,导致即使KV类的查询SQL的响应时间都出现了异常。
- 其他:暂时还无法归因到上述三种场景的案例。
- 自动限流:当发现实例存在根因分析中描述的资源消耗型SQL和流量型SQL时,会自动提取SQL特征,对异常SQL进行限流(用户授权的情况下触发)。这里面最难的问题是怎么选取SQL的特征,进行精确限流,而不会出现由于特征选取错误而导致业务全面受损。
- 特征选取:如果发现需要限流的异常SQL,下一步就需要确定SQL的特征,理想的情况是特征是唯一的,只对识别到的异常SQL进行限流而不影响其它SQL。这里首先要区分SQL模板限流和SQL文本限流。
- SQL模板限流:SQL模板是指将SQL文本的具体参数抽象化后的文本,这类SQL并发度高都会产生问题且与具体参数无关,对应突增流量,无索引等场景,特征只需要包含模板特征即可。
- SQL文本限流:这类限流主要针对数据倾斜的场景,同一类模板的一些SQL执行正常,一些SQL执行异常,特征中既要包含SQL模板信息,又要包含具体参数信息。
对于SQL模板限流,如果SQL中包含模板ID信息,会优先使用ID类信息,比如使用数据库中间件根据模板自动生成的SQL ID或者开发人员在SQL模板中添加的HINT信息。
使用ID的优点是容易保证模板唯一,不会对其它模板的SQL造成影响,缺点是同样的SQL如果不带ID信息(比如通过命令行手动执行),仍然可以执行,不受限流并发度控制。
如果不包含模板ID信息,那就需要提取文本信息,在分析过程中通过计算获得SQL模板。如下所示,SQL1和SQL2计算后分别可以得到模板1和模板2。那我们对模板1进行限流,可以获得的最全特征为select~id~name~age~from~students~where~name。/*SQL文本1*/ select id,name,age from students where name='张三'; /*SQL模板1*/ select id,name,age from students where name=? /*SQL文本2*/ select id,name,age from students where name='张三' and sid='唯一ID'; /*SQL模板2*/ select id,name,age from students where name=? and sid=?使用该特征进行限流,优点是不管从哪种连接方式发送的SQL,只要满足该特征都受限流并发度控制,缺点是存在误限的可能性,比如模板2包含模板1中的所有特征。
- 自动优化:当根因分析发现可以优化的SQL时,除了发起限流应急处理外,还会将异常SQL发送到自动优化模块,自动创建索引,该部分的内容将在后续的系列文章中进行详细介绍。
- 跟踪/回滚:自动限流后,持续跟踪,如果发现限流后,数据库的负载未降低或者降低的流量和预估出现偏差,自动回滚限流操作,并再次启动根因定位。