本章节介绍如何通过自建的Presto使用文件引擎。
背景信息
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持从GB到PB字节。Presto支持在线数据查询,包括Hive、Cassandra、关系数据库以及专有数据存储。
本文中Presto是通过连接Hive的元数据服务来读取文件存储HDFS上的数据,在文件引擎上使用Presto时需要额外配置一些依赖包,详细操作步骤请参见配置Presto。
准备工作
搭建和使用Presto读写文件引擎,需要先完成以下准备工作。
配置Presto
您可以参见以下步骤配置Presto,Presto官方配置文档请参见Deploying Presto。
解压Presto压缩包到指定目录。
tar -zxvf presto-server-0.241.tar.gz -C /usr/local/在Presto解压目录下创建etc目录。
mkdir /usr/local/presto-server-0.241/etc配置Node Properties。
创建
etc/node.properties文件。vim /usr/local/presto-server-0.241/etc/node.properties在
etc/node.properties文件中添加如下内容。node.environment=test node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.data-dir=/tmp/presto/data
配置JVM Config。
创建
etc/jvm.config文件。vim /usr/local/presto-server-0.241/etc/jvm.config在
etc/jvm.config文件中添加如下内容。-server -Xmx8G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
配置Config Properties。
本文将coordinator和worker配置在同一台机器上,您可以参见Presto官方文档将coordinator和worker配置到不同的机器。
创建
etc/config.properties文件。vim /usr/local/presto-server-0.241/etc/config.properties在
etc/config.properties中添加如下内容。coordinator=true node-scheduler.include-coordinator=true http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://xx.xx.xx.xx:8080 #xx.xx.xx.xx为当前机器的IP地址
配置日志级别。
创建
etc/log.properties文件。vim /usr/local/presto-server-0.241/etc/log.properties在
etc/log.properties文件中添加如下内容。com.facebook.presto=INFO
配置Catalog Properties。
创建
etc/catalog文件夹。mkdir /usr/local/presto-server-0.241/etc/catalog创建
etc/catalog/hive.properties文件。vim /usr/local/presto-server-0.241/etc/catalog/hive.properties在
etc/catalog/hive.properties文件中添加如下内容。connector.name=hive hive.metastore.uri=thrift://xxxx:9083 #xxxx为启动hive元数据服务的IP地址 hive.config.resources=/usr/local/hadoop-2.7.3/etc/hadoop/core-site.xml,/usr/local/hadoop-2.7.3/etc/hadoop/hdfs-site.xml #配置为您的Hadoop集群中core-site.xml文件的地址
将
presto-cli-xxx-executable.jar复制到Presto安装的bin目录下,重命名并赋予可执行权限。cp ~/presto-cli-0.241-executable.jar /usr/local/presto-server-0.241/bin/mv /usr/local/presto-server-0.241/bin/presto-cli-0.241-executable.jar /usr/local/presto-server-0.241/bin/prestochmod +x /usr/local/presto-server-0.241/bin/presto
验证Presto
创建测试数据并加载到Hive中。
创建测试数据。
echo -e "tt1\ntt2\ntt1\ntt2\ntt3\ntt4\ntt4\ntt5\ntt6" > ~/test.txt将测试数据上传到文件引擎上。
$HADOOP_HOME/bin/hadoop fs -mkdir /presto $HADOOP_HOME/bin/hadoop fs -put test.txt /presto/使用默认的数据创建test_data并加载数据。
hive> create external table test_data(word string) row format delimited fields terminated by '\n' stored as textfile location '/presto';查看数据是否加载成功。
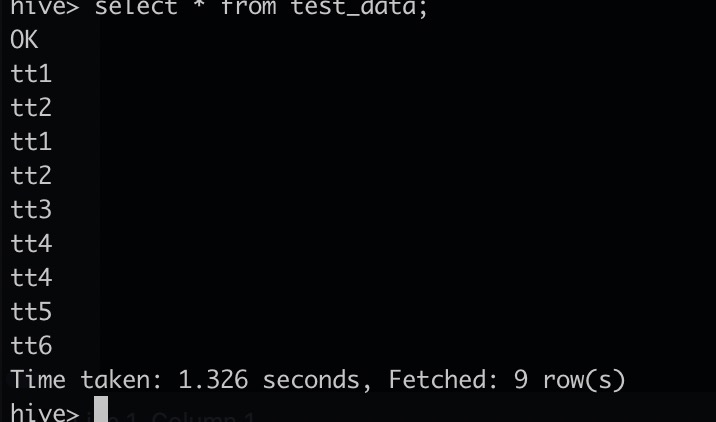
hive> select * from test_data;如果显示如下类似信息,则表示数据加载成功。
使用Presto通过Hive读取文件引擎上的数据并进行计算。
启动presto server。
/usr/local/presto-server-0.241/bin/launcher start使用presto连接Hive。
使用presto连接Hive。
/usr/local/presto-server-0.241/bin/presto --server localhost:8080 --catalog hive --schema default读取文件引擎上的数据。
presto:default> select * from test_data;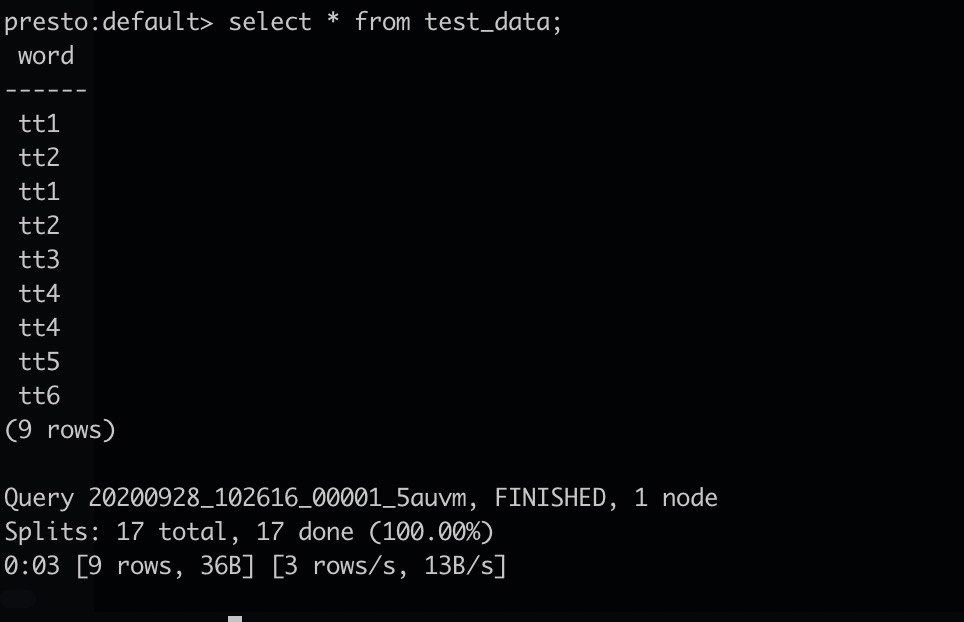
进行word count计算。
presto:default> select word, count(*) from test_data group by word;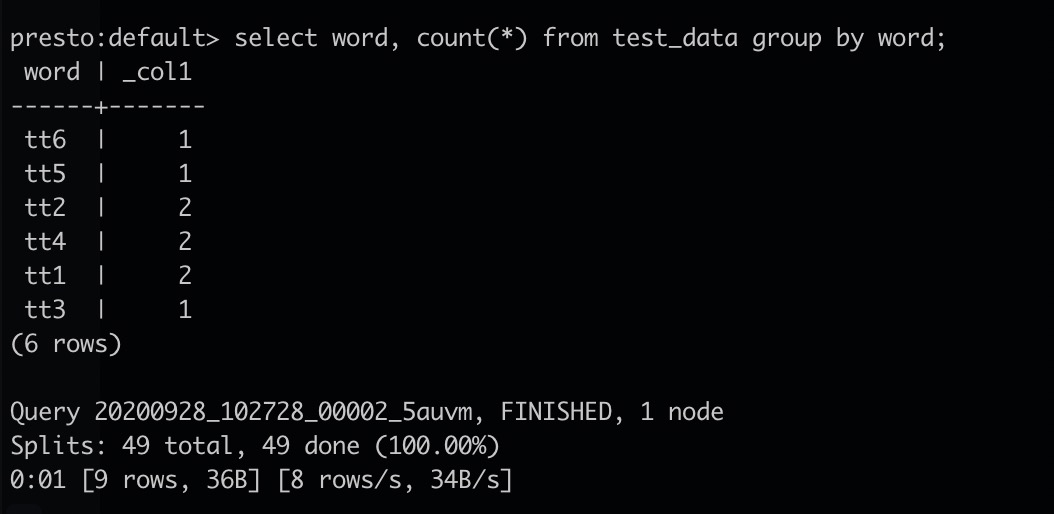
- 本页导读 (1)