RTC SDK提供了获取音频数据的功能,您可以将获取到的语音数据根据实际需求进行处理。通过阅读本文,您可以了解到获取音频数据的方法。
使用场景
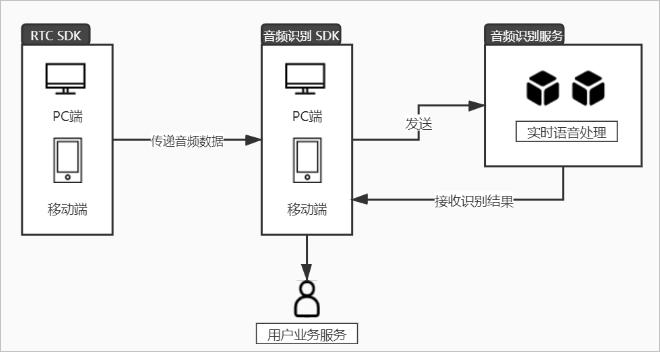
您可以将本地发布端或订阅端的音频数据通过阿里云语音识别服务转换成文字,实现流程如下所示:
- 阿里云RTC会将音频数据发送至音频识别SDK中。
- 音频识别SDK将音频数据发送至音频识别服务进行实时语音处理并返回识别结果。
- 音频识别SDK为用户提供识别结果。
方案架构图
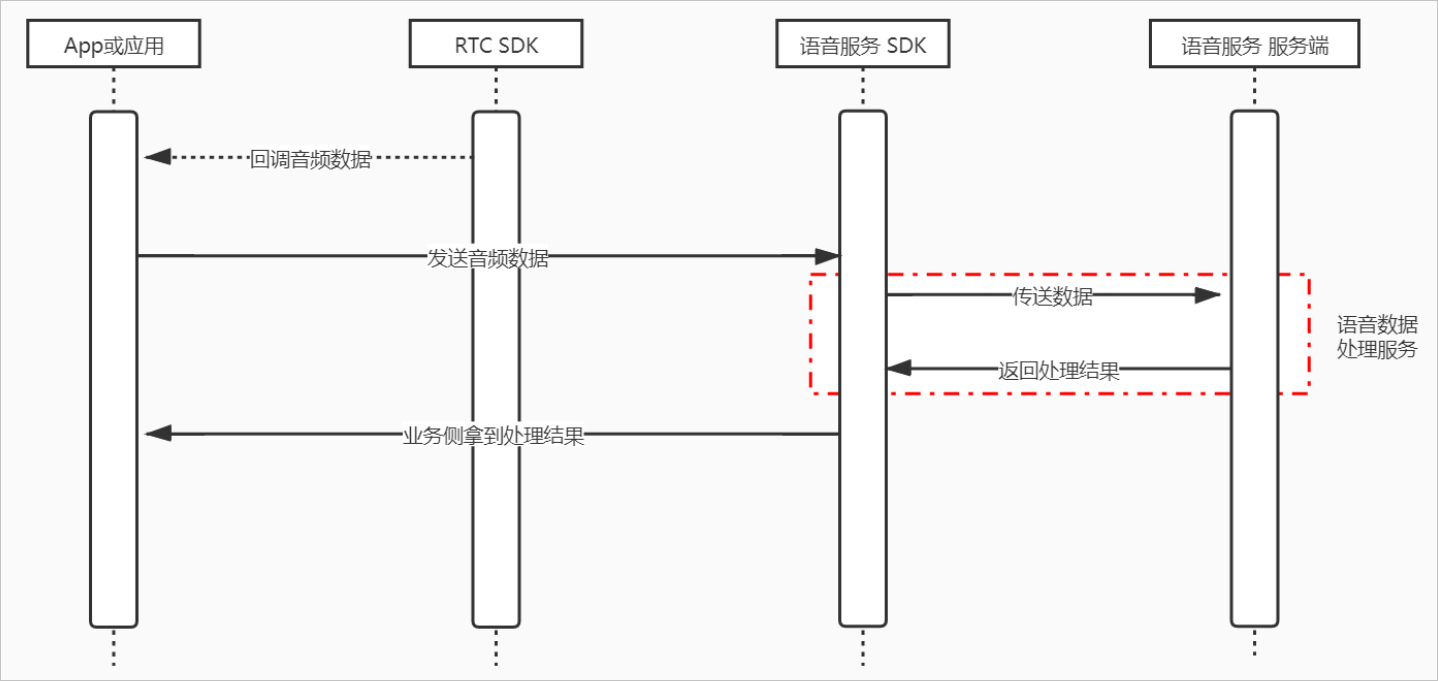
调用时序图
接口及使用
通过调用接口registerAudioObserver注册音频数据回调,注册时通过AliAudioType参数指明当前回调音频数据类型;使用音频回调AliAudioObserver接收音频媒体数据,并根据业务场景使用相应的数据源。
registerAudioObserver:注册音频数据回调。
public abstract void registerAudioObserver(AliRtcEngine.AliAudioType audioType, AliRtcEngine.AliAudioObserver audioObserver);| 名称 | 类型 | 描述 |
|---|---|---|
| audioType | AliAudioType | 回调音频数据的类型。 |
| audioObserver | AliAudioObserver | 音频数据回调接口。 |
语音数据处理
RTC获取音频数据方式如下: