弹性网卡ENI(Elastic Network Interface)是一种可以绑定到专有网络VPC类型ECS实例上的虚拟网卡。通过弹性网卡,您可以实现高可用集群搭建、低成本故障转移和精细化的网络管理。本文主要介绍如何使用Serverless
Spark通过ENI访问VPC中的HBase集群。
前提条件
保证Serverless Spark能够访问您的VPC,详情请参见
配置数据源网络。
注意 ENI交换机和安全组可以使用用户集群已有的ENI交换机和安全组。
操作步骤
- 将ENI交换机网段添加到HBase服务的白名单/安全组中。
- 获取需要在Severless Spark配置的参数。
Xpack-HBase用户可以登录
HBase集群控制台,单击
集群列表,然后单击相应的实例名称获取对应的
ThriftServer Access。
- 编写访问HBase的SparkApplication。
- 示例代码如下所示:
package com.aliyun.spark
import org.apache.spark.sql.SparkSession
object SparkHbase {
def main(args: Array[String]): Unit = {
//HBase集群的ThriftServer访问链接地址。//HBase集群的ThriftServer访问链接地址。使用时请把此路径替换为你自己的HBase集群的ThriftServer访问地址。
//格式为:xxx-002.hbase.rds.aliyuncs.com:2181,xxx-001.hbase.rds.aliyuncs.com:2181,xxx-003.hbase.rds.aliyuncs.com:2181
val zkAddress = args(0)
//HBase侧的表名,需要在HBase侧提前创建。HBase表创建可以参考使用Java Client访问。
val hbaseTableName = args(1)
//Spark侧的表名。
val sparkTableName = args(2)
val sparkSession = SparkSession
.builder()
// .enableHiveSupport() //使用enableHiveSupport后通过spark jdbc查看到代码中创建的表
.appName("scala spark on HBase test")
.getOrCreate()
import sparkSession.implicits._
//如果存在的话就删除表
sparkSession.sql(s"drop table if exists $sparkTableName")
val createCmd =
s"""CREATE TABLE ${sparkTableName} USING org.apache.hadoop.hbase.spark
| OPTIONS ('catalog'=
| '{"table":{"namespace":"default", "name":"${hbaseTableName}"},"rowkey":"rowkey",
| "columns":{
| "col0":{"cf":"rowkey", "col":"rowkey", "type":"string"},
| "col1":{"cf":"cf", "col":"col1", "type":"String"}}}',
| 'hbase.zookeeper.quorum' = '${zkAddress}'
| )""".stripMargin
println(s" the create sql cmd is: \n $createCmd")
sparkSession.sql(createCmd)
val querySql = "select * from " + sparkTableName + " limit 10"
sparkSession.sql(querySql).show
}
}
- HBase相关依赖可参考下方
pom.xml: <dependency>
<groupId>com.aliyun.apsaradb</groupId>
<artifactId>alihbase-spark</artifactId>
<version>1.1.3_2.4.3-1.0.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.aliyun.hbase</groupId>
<artifactId>alihbase-client</artifactId>
<version>1.1.3</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.aliyun.hbase</groupId>
<artifactId>alihbase-protocol</artifactId>
<version>1.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.aliyun.hbase</groupId>
<artifactId>alihbase-server</artifactId>
<version>1.1.3</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
</dependency>
- 将SparkApplication JAR包和依赖上传至OSS中。
详情请参见
上传文件。
说明 OSS所在的region和Serverless Spark所在的region需要保持一致。
- 在Serverless Spark中提交作业并进行计算。
- 通过HBase集群的HBase Shell准备数据。
bin/hbase shell
hbase(main):001:0> create 'mytable', 'cf'
hbase(main):001:0> put 'mytable', 'rowkey1', 'cf:col1', 'this is value'
- 在Serverless Spark控制台提交访问HBase的Spark作业。详情请参见创建和执行Spark作业。
{
"args": [
"xxx:2181,xxx1:2181,xxx2:2181",
"mytable",
"spark_on_hbase_job"
],
"name": "spark-on-hbase",
"className": "com.aliyun.spark.SparkHbase",
"conf": {
"spark.dla.eni.vswitch.id": "{您的交换机ID}",
"spark.dla.eni.security.group.id": "{您的安全组ID}",
"spark.driver.resourceSpec": "medium",
"spark.dla.eni.enable": "true",
"spark.dla.connectors": "hbase",
"spark.executor.instances": 2,
"spark.executor.resourceSpec": "medium"
},
"file": "oss://{您的JAR包所属的OSS路径}"
}
作业参数说明:
| 参数 |
说明 |
备注 |
| xxx:2181,xxx1:2181,xxx2:2181 |
HBase集群中的ZK链接地址。 |
可按照第二步方法在HBase控制台获取 |
| mytable |
HBase集群中表,本实例使用的HBase表:mytable,使用HBase Shell创建表准备数据 |
无 |
| spark_on_hbase_job |
Spark中创建映射HBase表的表名。 |
无 |
| spark.dla.connectors |
将Serverless Spark内置的读取HBase表格相关JAR包包含到classpath中。 |
如果用户作业JAR包中不包含读取HBase相关依赖,则需要配置该参数,如果用户作业JAR包中包含了读取HBase的相关依赖,则无需配置该参数。 |
| spark.dla.eni.vswitch.id |
您的交换机ID。 |
无 |
| spark.dla.eni.security.group.id |
您的安全组ID。 |
无 |
| spark.dla.eni.enable |
控制开启或关闭ENI。 |
无 |
作业运行成功后,单击,查看作业日志。
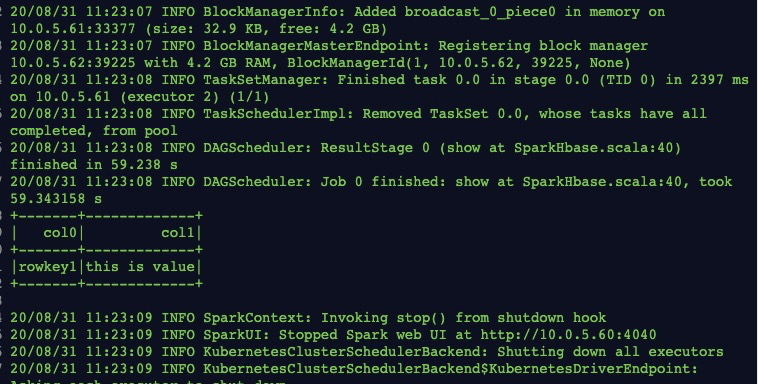
说明 如果用户需要上传自定义的HBase Connector JAR包,则无需设置spark.dla.connectors为HBase,直接在ConfigJson中使用jars:["<oss://path/to/your/hbase/connector/jar>"]上传HBase依赖JAR包即可。