本文主要介绍如何使用DLA Spark访问用户VPC中的HADOOP集群(开启kerberos认证的集群暂不支持)。
前提条件
- 您已开通数据湖分析DLA(Data Lake Analytics)服务。如何开通,请参见开通云原生数据湖分析服务。
- 您已登录云原生数据库分析DLA控制台,在云原生数据湖分析DLA控制台上创建了Spark虚拟集群。

- 您已开通对象存储OSS(Object Storage Service)服务。如何开通,请参见开通OSS服务。
- 准备创建Spark计算节点所需要的交换机id和安全组id,可以选择已有的交换机和安全组,也可以新建交换机和安全组。交换机和安全组需要满足以下条件。
- 交换机需要与您的Hadoop服务集群在同一VPC下。可使用您Hadoop集群控制台上的交换机ID。
- 安全组需要与您的Hadoop服务集群在同一VPC下。您可以前往ECS控制台-网络与安全-安全组按照专有网络(VPC)ID搜索该VPC下的安全组,任意选择一个安全组ID即可。
- 如果您的Hadoop服务有白名单控制,需要您将交换机网段加入到您Hadoop服务的白名单中。
注意 对于Xpack-Spark用户首先联系云X-Pack Spark答疑(钉钉号:dgw-jk1ia6xzp)开通HDFS, 由于HDFS的开放可能造成用户的恶意攻击,引起集群不稳定甚至造成破坏。因此XPack-Spark的HDFS功能暂时不直接开放给用户。
操作步骤
- 获取需要在DLA Spark配置的Hadoop相关参数。说明 如果您的Hadoop服务所在集群无法执行spark作业,可以跳过这步。我们提供了工具来读取您Hadoop服务所在集群的配置,您可以按照下面的地址下载
spark-examples-0.0.1-SNAPSHOT-shaded.jar并上传至OSS, 然后提交Spark作业到用户的Hadoop服务所在集群上执行,即可在作业输出中获得访问Hadoop所需的配置。wget https://dla003.oss-cn-hangzhou.aliyuncs.com/GetSparkConf/spark-examples-0.0.1-SNAPSHOT-shaded.jar- EMR用户将Jar包上传至OSS后,可以通过以下命令提交获取配置作业:
--class com.aliyun.spark.util.GetConfForServerlessSpark --deploy-mode client ossref://{path/to}/spark-examples-0.0.1-SNAPSHOT-shaded.jar get hadoop作业运行完毕后,可以通过SparkUI查看driver的stdout输出或者从作业详情中的提交日志中查看输出的配置。
- 云Hbase-Spark用户将Jar包上传至资源管理目录后,以用以下命令提交获取配置作业:
--class com.aliyun.spark.util.GetConfForServerlessSpark /{path/to}/spark-examples-0.0.1-SNAPSHOT-shaded.jar get hadoop等待作业完成后,通过SparkUI的driver中的stdout查看输出配置。
- 其他HADOOP集群,如果您在集群上未设置
HADOOP_CONF_DIR环境变量,则需要手动输入HADOOP_CONF_DIR路径。--class com.aliyun.spark.util.GetConfForServerlessSpark /{path/to}/spark-examples-0.0.1-SNAPSHOT-shaded.jar get --hadoop-conf-dir </path/to/your/hadoop/conf/dir> hadoop
- EMR用户将Jar包上传至OSS后,可以通过以下命令提交获取配置作业:
- 在DLA Spark中提交作业并进行计算。
- 如果您的HDFS服务以非高可用的模式部署(即只有一个Mater节点/NameNode),详情请参见创建和执行Spark作业和作业配置指南。
{ "args": [ "${fs.defaultFS}/tmp/dla_spark_test" ], "name": "spark-on-hdfs", "className": "com.aliyun.spark.SparkHDFS", "conf": { "spark.dla.eni.enable": "true", "spark.dla.eni.vswitch.id": "{您的交换机id}", "spark.dla.eni.security.group.id": "{您的安全组id}", "spark.dla.job.log.oss.uri": "oss://<指定您存放SparkUI日志的目录/>", "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium" }, "file": "oss://{您的jar包所属的oss路径}" }参数说明如下:参数 说明 备注 fs.defaultFS 您的hdfs配置文件中core-site.xml 中的配置,注意如果fs.defaultFS配置的是机器的域名,需要转换成域名所对应的IP。典型格式 hdfs://${域名对应的ip}:9000/path/to/dir。 用户可以通过登录集群master节点,通过/etc/hosts文件查看域名和IP的对应关系,或者直接采取ping域名的方式获取,或者通过步骤1获取相应配置。 spark.dla.eni.vswitch.id 您的交换机ID。 无 spark.dla.eni.security.group.id 您的安全组ID。 无 spark.dla.eni.enable 控制开启或关闭ENI。 无 作业运行成功后,单击,查看作业日志。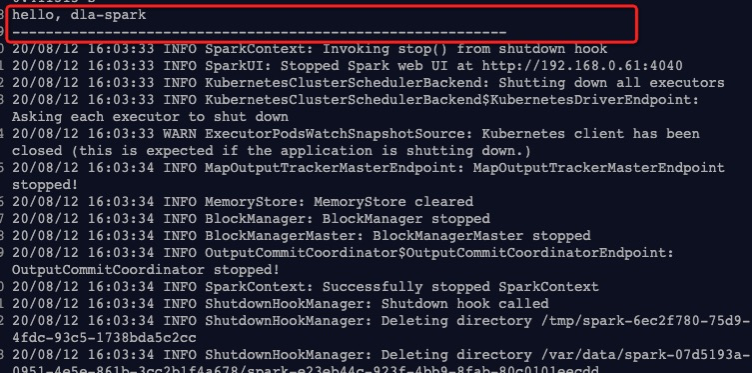
- 如果您的HDFS以高可用模式部署(即有一个以上Master节点/NameNode)。
{ "args": [ "${fs.defaultFS}/tmp/test" ], "name": "spark-on-hdfs", "className": "com.aliyun.spark.SparkHDFS", "conf": { "spark.dla.eni.enable": "true", "spark.dla.eni.vswitch.id": "{您的交换机id}", "spark.dla.eni.security.group.id": "{您的安全组id}", "spark.driver.resourceSpec": "medium", "spark.dla.job.log.oss.uri": "oss://<指定您存放SparkUI日志的目录/>", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", "spark.hadoop.dfs.nameservices":"{您的nameservices名称}", "spark.hadoop.dfs.client.failover.proxy.provider.${nameservices}":"{您的failover proxy provider实现类全路径名称}", "spark.hadoop.dfs.ha.namenodes.${nameservices}":"{您的nameservices所属namenode列表}", "spark.hadoop.dfs.namenode.rpc-address.${nameservices}.${nn1}":"namenode0所属的ip:port", "spark.hadoop.dfs.namenode.rpc-address.${nameservices}.${nn2}":"namenode1所属的ip:port" }, "file": "oss://{{您的jar包所属的oss路径}" }
参数 说明 备注 spark.hadoop.dfs.nameservices 对应hdfs-site.xml中的dfs.nameservices 无 spark.hadoop.dfs.client.failover.proxy.provider.${nameservices} 对应hdfs-site.xml中的dfs.client.failover.proxy.provider.${nameservices} 无 spark.hadoop.dfs.ha.namenodes.${nameservices} 对应hdfs-site.xml中的dfs.ha.namenodes.${nameservices} 无 spark.hadoop.dfs.namenode.rpc-address.${nameservices}.${nn1/nn2} 对用hdfs-site.xml中的dfs.namenode.rpc-address.${nameservices}.${nn1/nn2} 注意这里应该填写namenode域名对应的ip:port,用户可以通过用户集群master节点中的/etc/hosts文件查看域名和IP的对应关系,或者通过步骤1获取相应的配置。 - 如果您的HDFS服务以非高可用的模式部署(即只有一个Mater节点/NameNode),详情请参见创建和执行Spark作业和作业配置指南。