声纹检索,是指通过声音来验证或者识别说话人的声音。声纹识别的关键步是声音向量化,将说话人的声音将其转化成结构化向量。阿里云云原生数据仓库AnalyticDB MySQL版(简称ADB,原分析型数据库MySQL版)向量分析功能,提供了一套声纹验证检索解决方案,即通过SQL命令快速搭建一套高精度声纹检索系统。
系统架构
ADB(声纹库)负责存储和查询声纹检索系统的所有结构化信息(用户注册标识、用户姓名以及其他用户信息)和非结构化信息(声音产生的向量)。查询数据时,系统通过声纹抽取模型,将声音转换成向量,然后进行查询。系统返回相关用户信息,以及l2向量距离[5]。系统架构图如下图所示。
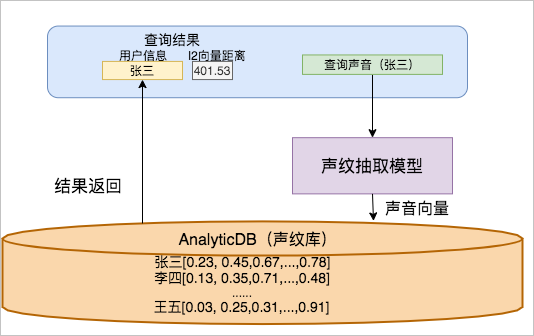
系统采用GMM-UMB模型抽取的i-vector作为检索向量[3]。为方便用户使用,ADB训练了精度更高的深度学习声纹识别模型(x-vector[4]),可以针对特定场景,例如电话通话、手机APP、嘈杂噪声等相关场景进行声纹模型训练。下表列出了ADB在学术界常用的声纹识别数据集(Aishall.v1 [1]数据集和TIMIT [2]数据集)中的(1:N)的准确率(准确率均大于99.5%)。
Aishall 数据集 | TIMIT 数据集 |
99.73% | 99.54% |
系统演示
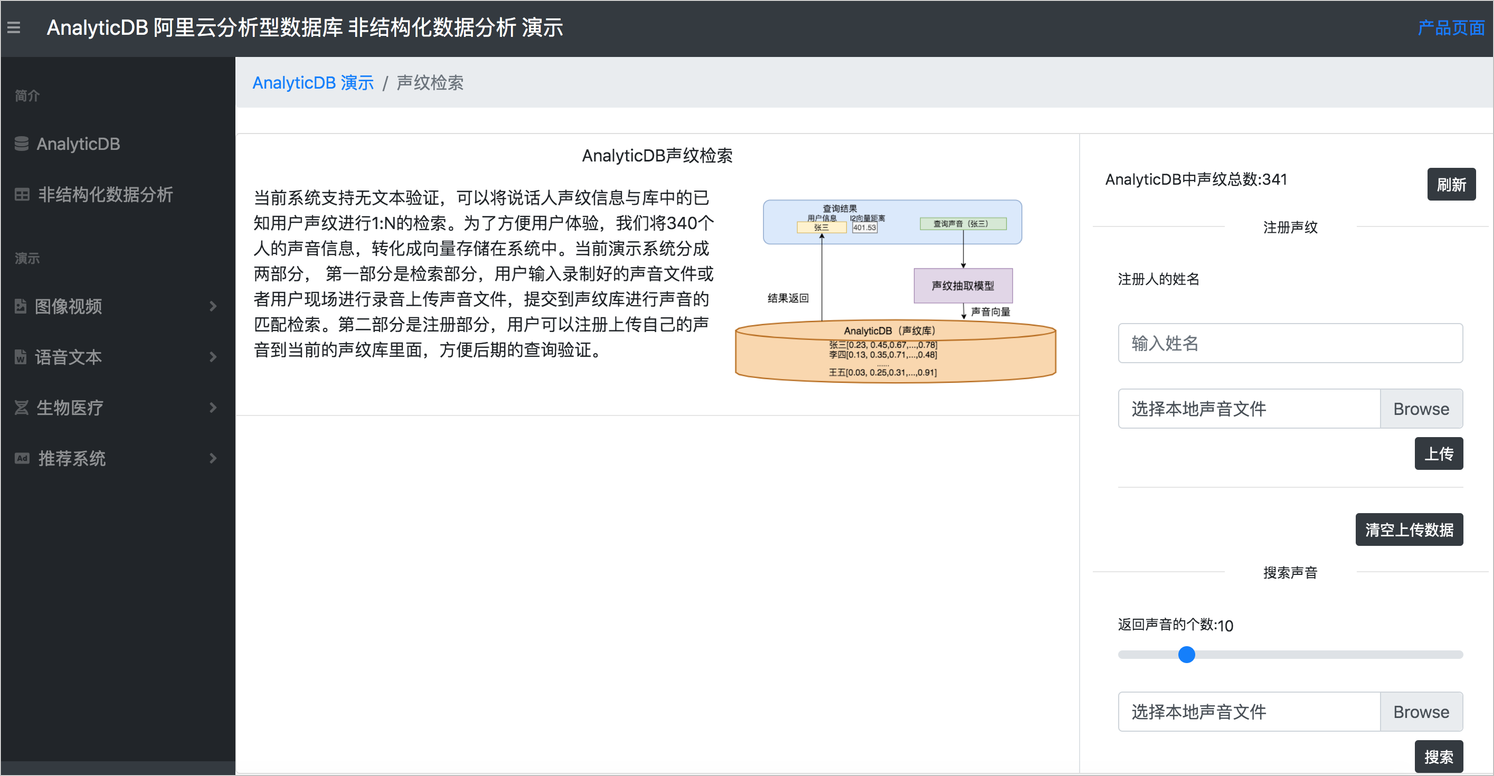
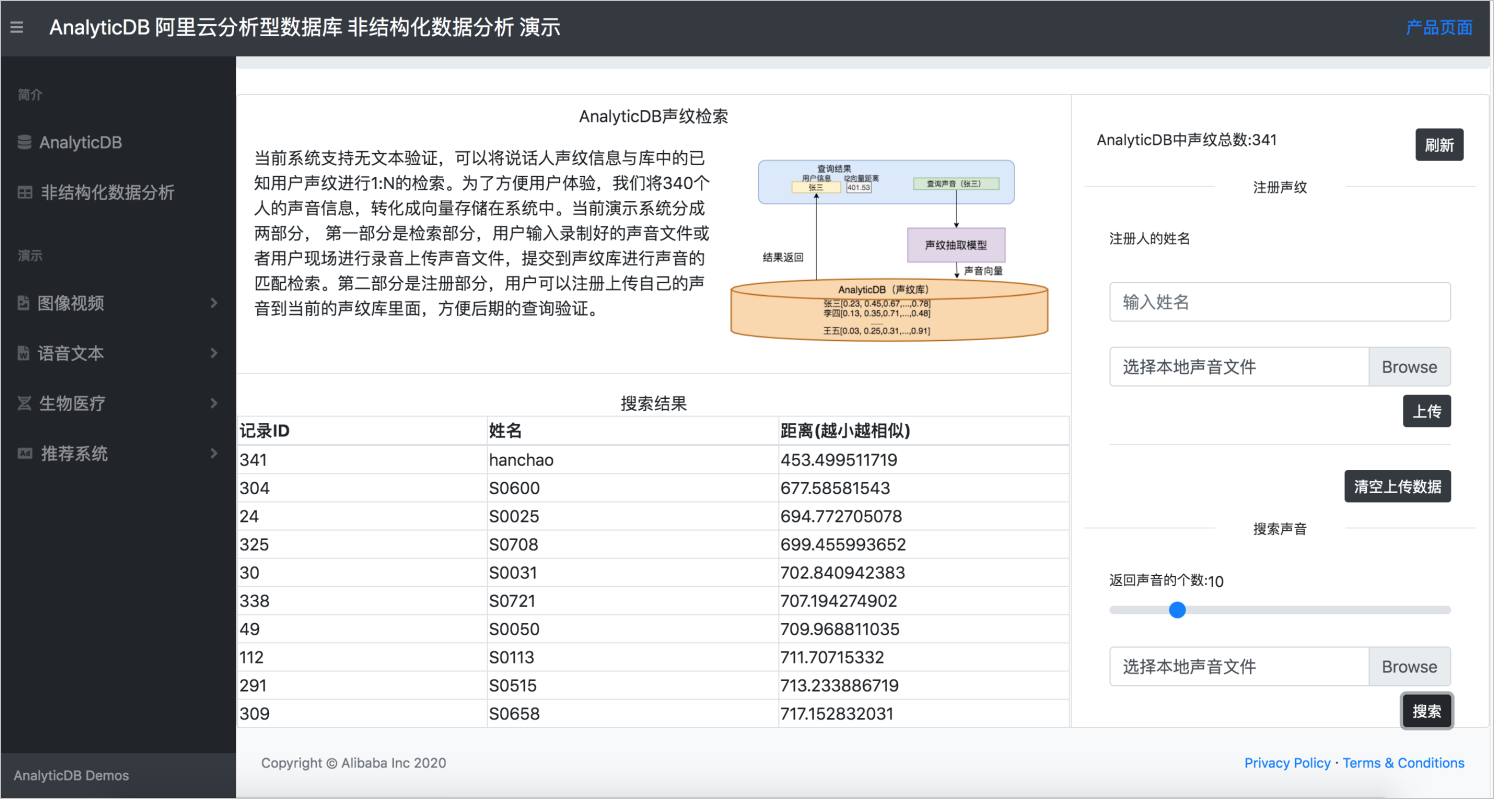
下图是ADB声纹检索系统的演示界面。为方便演示,ADB将380个人的声音信息转化成向量存储在系统中。当前演示系统包含声纹检索和注册两个模块:
声纹检索,将声音文件上传到声纹库进行声音匹配检索。
注册,将声音注册到声纹库,方便后期查询检索。
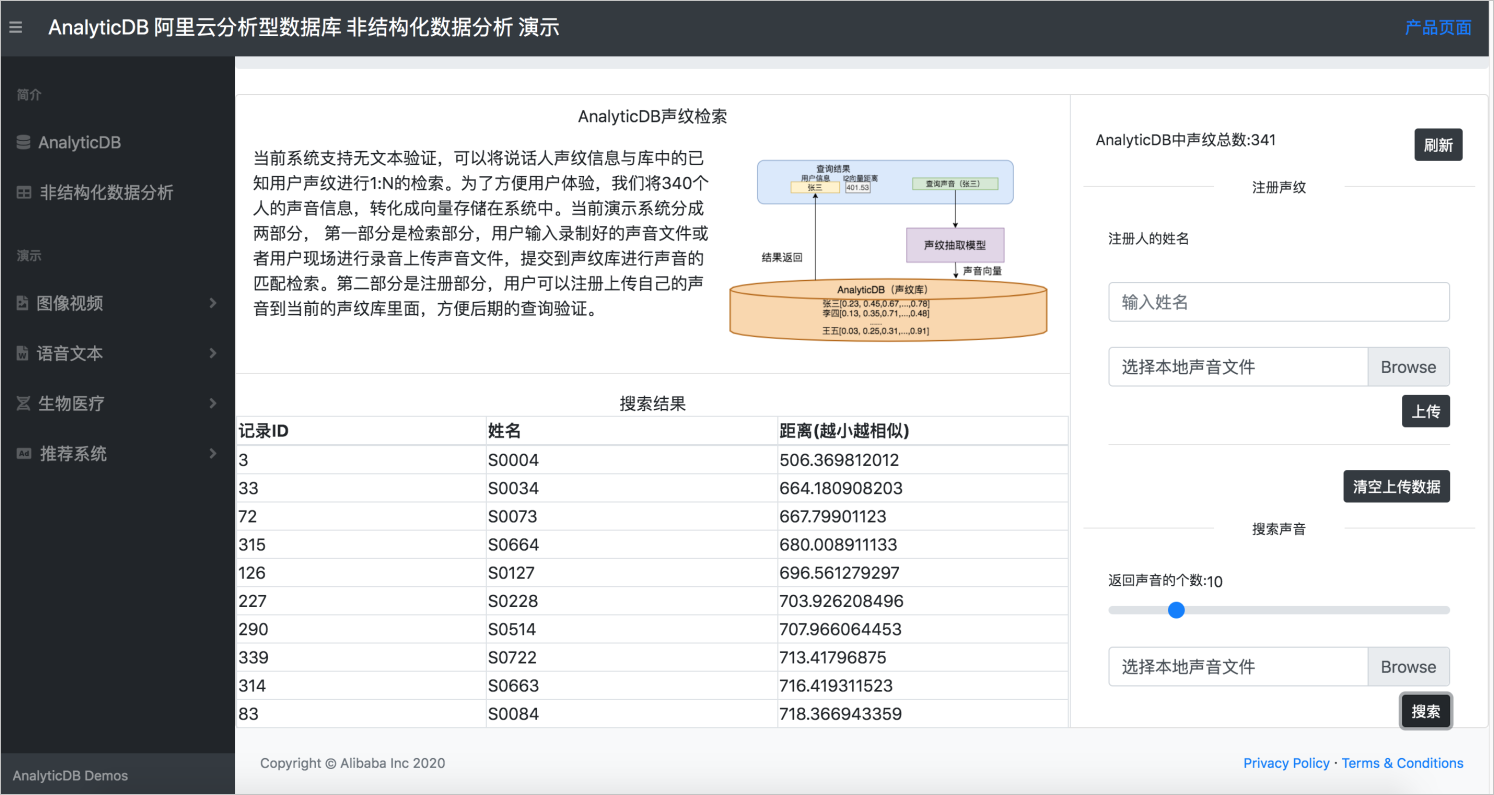
例如下图所示,上传一段名为S0004的测试音频BAC009S0004W0486.wav,然后到声纹数据库中进行检索,返回结果中top1即为正确结果。
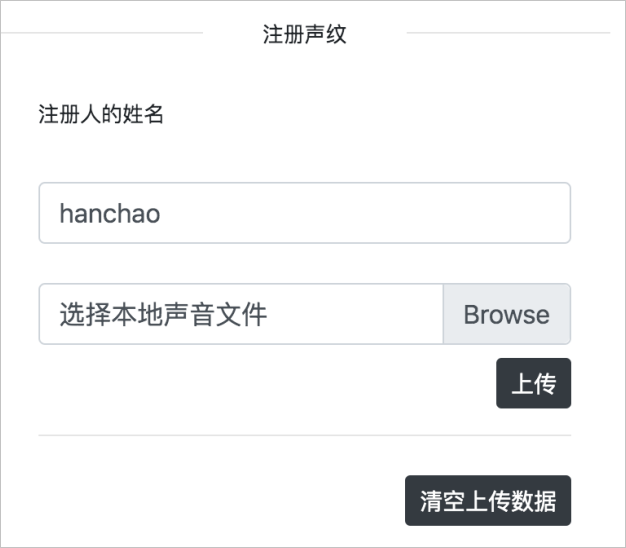
下图为声纹注册系统,支持无文本注册,您可以注册自己的声音到声纹数据库。例如某用户Hanchao注册自己的声音(声音时长7秒)到声纹数据库。
支持现场录制声音上传到声纹检索系统,例如下图所示,某用户Hanchao录制了一段5秒的语音上传到声纹系统。由于该用户之前注册过Hanchao的声音,返回结果中排名第一的声音就是Hanchao的声音。
ADB采用1:N演示结果,可应用于会议室中,通过声音识别会议发言者。当前,对于身份验证,采用1:1演示,要求距离小于550。
三步搭建声纹系统
初始化
ADB声纹检索系统支持声音转向量函数,您可以将从前端获取的声音通过POST请求,发送给ADB声纹特征提取服务,系统自动选择对应的声纹模型,将声音转成对应的向量。
import requests import json import numpy as np # sound:声音二进制文件。 # model_id:模型id。 def get_vector(sound, model_id='i-vector'): url = 'http://47.XXX.XXX.XXX:18XXX/demo/vdb/v1/retrieve' d = {'resource': sound, 'model_id': model_id} r = requests.post(url, data=d) js = json.loads(r.text) return np.array(js['emb']) # 读取用户文件。 file = 'xxx.wav' data = f.read() print(get_vector(data)) f.close()初始化过程中,您需要创建相关声纹表,为表中向量列添加向量索引,加速数据查询。当前声纹模型支持输出400维的向量,索引参数dim设置为400。
--创建用户声纹表 CREATE TABLE person_voiceprint_detection_table( id serial primary key, name varchar, voiceprint_feature float4[] ); --创建向量索引 CREATE INDEX person_voiceprint_detection_table_idx ON person_voiceprint_detection_table USING ann(voiceprint_feature) WITH(distancemeasure=L2,dim=400,pq_segments=40);注册声音
声音注册过程中,先注册用户,系统将声音文件上传到特征提取服务,由特征提取服务将声音转换成向量,然后在ADB中进行查询。
--注册用户'张三'到当前的系统中。 --通过HTTP服务,将声纹转化成相关的向量。 INSERT INTO person_voiceprint_detection_table(name, voiceprint_feature) SELECT '张三', array[-0.017,-0.032,...]::float4[])检索或验证声纹
声纹门锁1:1检索
声纹检索时,系统通过用户标识信息(user_id),在声纹库中计算输入的声音向量和声纹库中该用户的声音向量之间的距离。系统将设置一个距离阈值(threshold=550),如果向量之间的距离大于该阈值,表示验证失败;如果小于该阈值,表示声纹验证成功。
SELECT id, -- 用户id信息 name, -- 用户姓名 l2_distance(voiceprint_feature, ARRAY[-0.017,-0.032,...]::float4[]) AS distance -- 向量距离 FROM person_voiceprint_detection_table -- 用户声音表 WHERE distance < threshold -- 通常情况下,threshold为550 AND id = 'user_id' -- 用户要验证的id会议声纹1:N检索
系统通过识别当前会议发言人的声音,返回最相关的注册用户信息。如果没有返回结果,表示当前会议发言人不在声纹库中。
SELECT id, -- 用户id信息 name, -- 用户姓名 l2_distance(voiceprint_feature, ARRAY[-0.017,-0.032,...]::float4[]) AS distance -- 向量距离 FROM person_voiceprint_detection_table -- 用户声音表 WHERE distance < threshold -- 通常情况下,threshold为550 ORDER BY voiceprint_feature <-> ARRAY[-0.017,-0.032,...]::float4[] -- 利用向量进行排序 LIMIT 1; -- 返回最相似的结果
参考文档
Aishell Data set.OpenSLR .
TIMIT Data set.The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus.
Najim Dehak, Patrick Kenny, Réda Dehak, Pierre Dumouchel, and Pierre Ouellet, “Front-end factor analysis for speaker verification,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2011.
David Snyder, Daniel Garcia-Romero, Daniel Povey and Sanjeev Khudanpur, “Deep Neural Network Embeddings for Text-Independent Speaker Verification”, Interspeech , 2017 :999-1003.
Anton, Howard (1994), Elementary Linear Algebra (7th ed.), John Wiley & Sons, pp. 170–171, ISBN 978-0-471-58742-2.
- 本页导读 (1)