本文介绍应用集成中典型的逻辑步骤,帮助您理解和使用逻辑步骤。
多播器
多播器可以将同一条消息路由到多个端点并以不同的方式处理它们,并且不会修改源消息;可以在同一线程中按顺序进行,也可以使用多个线程并行处理。
| 参数 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| 是否并行执行 | 是否在多个Flow并行处理。 | 是 | 否 |
| 产生异常是否终止 | 如果在处理期间发生异常或故障,是否停止Flow。 | 是 | 否 |
使用多播器的示例场景,请参见从SFTP服务器获取订单文件并按不同供应商分发。
检查器
您可以在检查器中设置简单语言表达式,当满足表达式中的定义条件时停止集成运行,并引发检查错误异常。
| 参数 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| simpleExpression | Camel支持的正则表达式,用于定义检查条件。 | 是 | 无 |
高级过滤器
说明
- 高级过滤器不支持用在输出结果为Collection类型的步骤后面,如Datebase和MongoDB连接器等。
- 高级过滤器支持用在输出结果为JSON类型的步骤后面。
高级过滤器用于筛选数据,以便仅在满足定义的条件时集成才会继续执行。
| 参数 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| filter | Camel支持的正则表达式,用于定义过滤条件。 | 是 | 无 |
日志记录器
发送消息到集成日志。
| 参数 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| 消息上下文 | 打印消息的Header。 | 否 | 无 |
| 定制消息内容 | 自定义消息的Body。 | 否 | 无 |
| 消息内容 | 打印消息的Body。 | 否 | 无 |
模板器
将当前集成流中数据进行文本替换,适用于大文本替换类型的集成场景。
| 参数 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| Freemarker | 自定义设置Freemarker表达式,携带的变量值为上一步骤的输出,变量格式为${变量名},变量名必须为大小写字母。 | 是 | 无 |
使用模板器的示例场景,请参见定制化内容并发送到目标邮箱。
转换器
您可以自定义脚本将数据转换为任何格式。
| 参数 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| groovy脚本 | 需要执行的groovy脚本。 | 是 | 无 |
使用转换器的示例场景,请参见从SFTP服务器获取订单文件并按不同供应商分发。
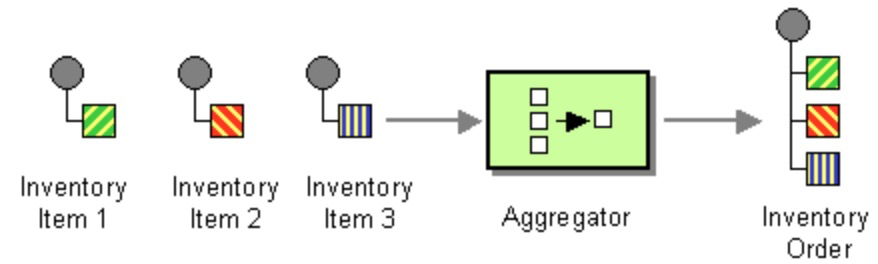
聚合器
聚合器可以将多个消息组合在一起,成为一条消息。可以将其视为拆分器的反向模式。
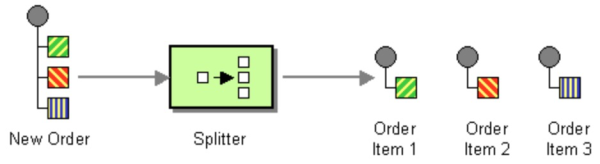
拆分器
拆分器可以将一条消息拆分为多个部分,然后分别进行处理。
选择器
选择器根据设置的条件来决定最终运行哪个分支。它有一个默认分支,当其他所有分支的条件都不满足时会运行该分支。
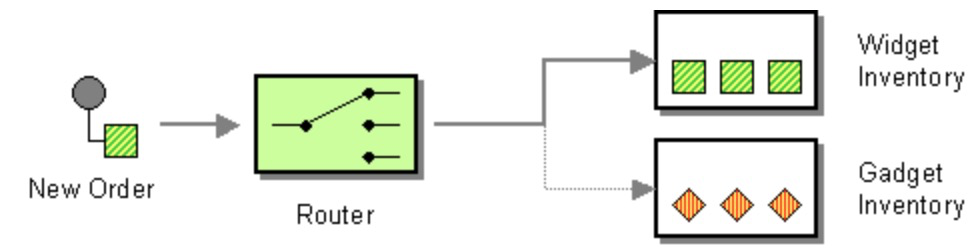
数据映射器
数据映射是两个不同数据模型之间的映射过程,是数据集成的关键因素。数据模型存在许多现有标准,由各个组织或委员会管理,因此,需要添加数据映射器,从自定义数据模型映射到标准数据模型时,即在创建新的集成或编辑集成。