可视化MapReduce模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志,同时支持每个子任务级别的重跑。
注意事项
仅专业版支持。
子任务个数不能超过1000个。
单个子任务的大小不能超过64 KB。
子任务显示自定义标签信息时,子任务对象需要实现指定接口。
ProcessResult的result返回值不能超过1000 Byte。
如果使用reduce,所有子任务结果会缓存在Master节点,该情况对Master节点内存压力较大,建议子任务个数和result返回值不要太大。如果没有reduce需求,使用MapJobProcessor接口即可。
SchedulerX不保证子任务绝对执行一次。在特殊条件下会failover,可能导致子任务重复执行,需要业务方自行实现幂等。
接口
继承MapReduce模型所有接口,任务处理代码开发模型与MapReduce模型完全一致。具体信息,请参见MapReduce模型。
(可选)在MapReduce模型接口基础上,支持设置每个子任务的标签展示(子任务对象需要实现com.alibaba.schedulerx.worker.processor.BizSubTask接口)。
接口
解释
是否必选
public Map<String, String> labelMap()实现输出子任务标签信息,用于展示对应子任务对象的业务自定义特征信息(如:账户名、商品Code、城市区域等)。
否
与MapReduce对比
对比项 | MapReduce | 可视化MapReduce |
子任务数量 | 可支持百万级 | 小于等于1000。 |
任务开发模式 | 两者相同 | |
子任务列表 | 不支持 | 支持。 |
子任务运行详情 | 不支持 | 支持,单个子任务执行记录、执行状态、日志、链路追踪、运行堆栈。 |
子任务标签 | 不支持 | 支持,子任务实现BizSubTask接口可查看业务标签信息。 |
子任务操作 | 不支持 | 支持,单个子任务支持停止、重跑。 |
任务开发演示
账户批量处理
案例描述:对一批银行账户进行批量处理,每个账号作为独立的子任务在整个集群中进行全局并行处理,并且每一个子任务在执行列表中需要显示其对应的账户信息以便查看,可以方便的掌握每一个账号地处理状态及其执行详细信息。如下将提供相应demo代码供参考使用。
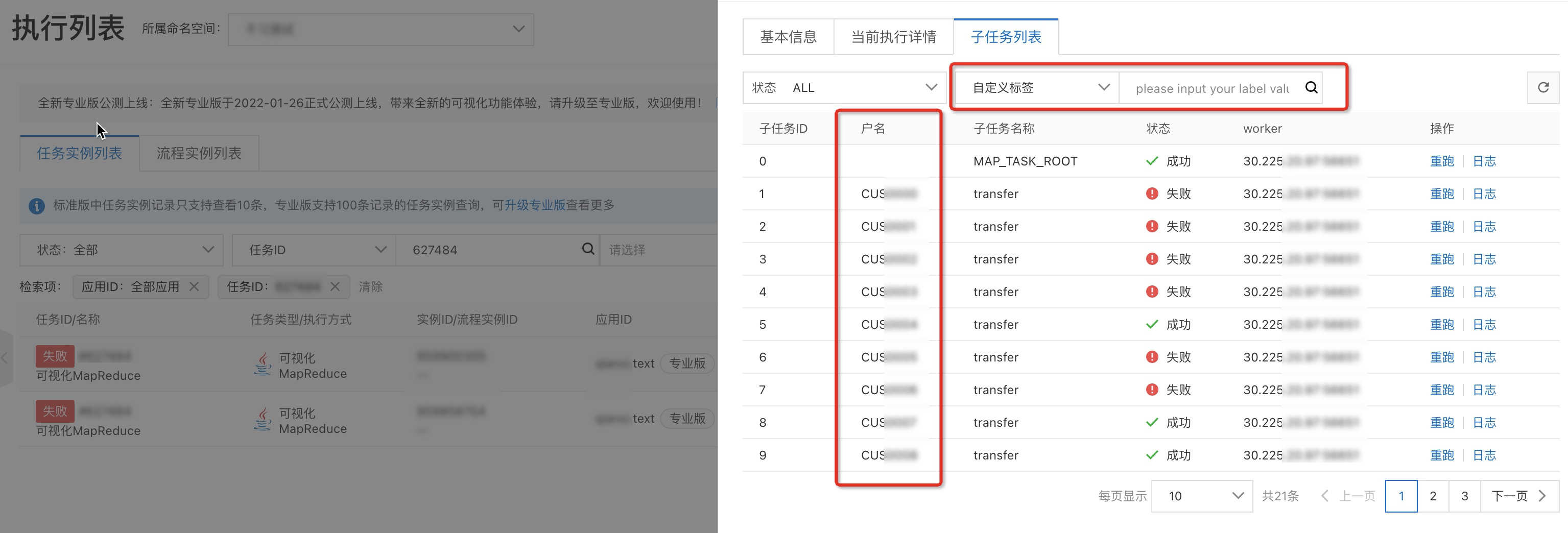
自定义账号信息子任务对象,每个子任务对象支持展示其标签信息,需实现接口com.alibaba.schedulerx.worker.processor.BizSubTask,并实现labelMap方法。
public class ParallelAccountInfo implements BizSubTask { /** * 主键 */ private long id; private String name; private String accountId; public ParallelAccountInfo(long id, String name, String accountId) { this.id = id; this.name = name; this.accountId = accountId; } /** * 实现labelMap方法,用于设置对应子任务的标签信息 * @return */ @Override public Map<String, String> labelMap() { Map<String, String> labelMap = new HashMap(); labelMap.put("户名", name); return labelMap; } }子任务对象实现对应接口后,子任务列表才可展示出每个子任务对象独有的标签信息(例如:案例中的户名)用于区分每一个账户对象的业务处理情况,且支持按标签搜索。
账号业务任务处理Processor,实现对单个账号的业务逻辑处理,继承com.alibaba.schedulerx.worker.processor.MapReduceJobProcessor。
操作步骤
任务配置
登录分布式任务调度平台,在左侧导航栏,单击任务管理。
在任务管理页面,单击创建任务。
在创建任务面板,执行模式下拉列表选择可视化MapReduce。
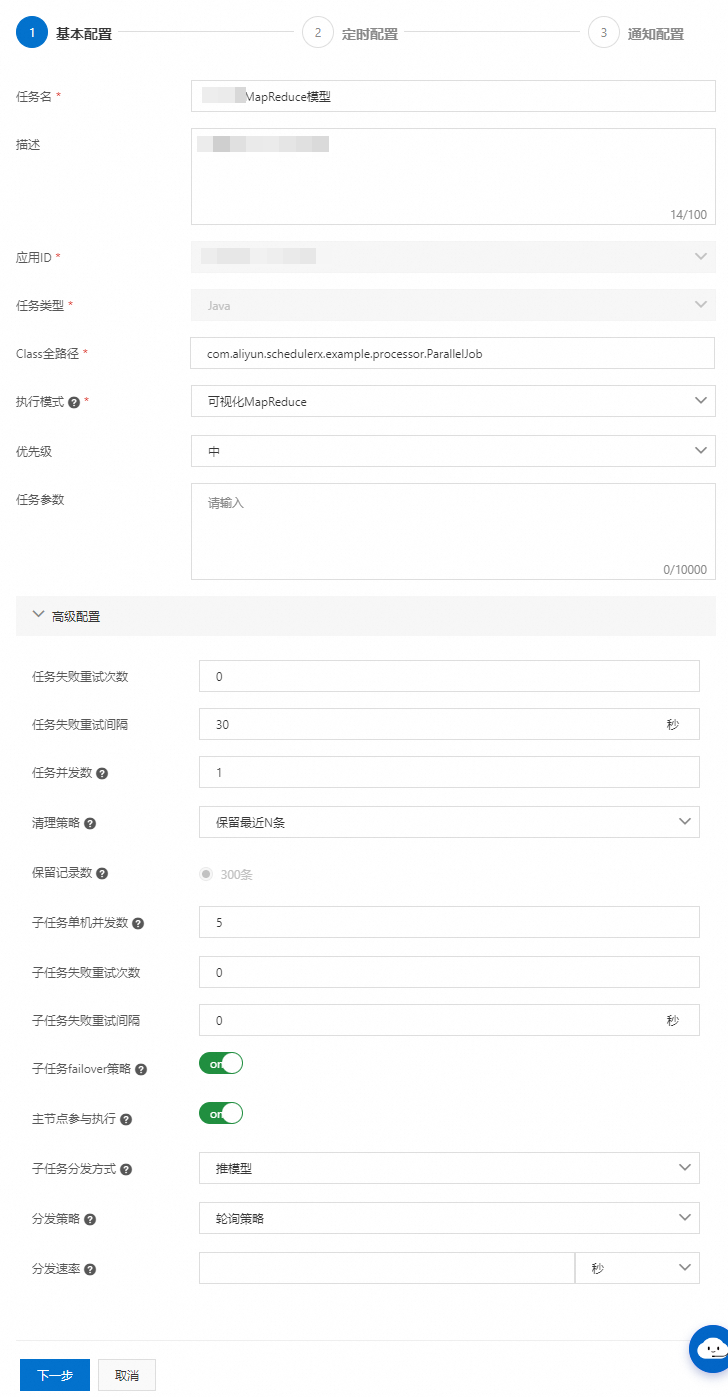
在高级配置区域配置相关信息。其他配置项,请参见任务管理高级配置参数说明。
配置项
说明
分发策略
轮询策略(默认):每个Worker平均分配等量子任务,适用于每个子任务处理耗时基本一致的场景。
WorkerLoad最优策略:由主节点自动感知Worker节点的负载情况,适用于子任务和Worker机器处理耗时有较大差异的场景。
说明客户端版本为1.10.14及以上。
子任务单机并发数
即单机执行线程数,默认为5。如需加快执行速度,可以调大该值。如果下游或者数据库无法承接,可适当调小。
子任务失败重试次数
子任务失败会自动重试,默认为0。
子任务失败重试间隔
子任务失败重试间隔,单位:秒,默认为0。
子任务failover策略
当执行节点宕机下线后,是否将子任务重新分发给其他机器执行。开启该配置后,发生failover时,子任务可能会重复执行,需自行做好幂等。
说明客户端版本为1.8.13及以上。
主节点参与执行
主节点是否参与子任务执行。在线可运行Worker数量必须不低于2台,在子任务数量特别大时,推荐关闭该参数。
说明客户端版本为1.8.13及以上。
可视化能力
任务执行后,您可以在执行列表页面,单击详情查看对应子任务的详细执行信息。
在子任务列表页签查看每个子任务处理的状态。
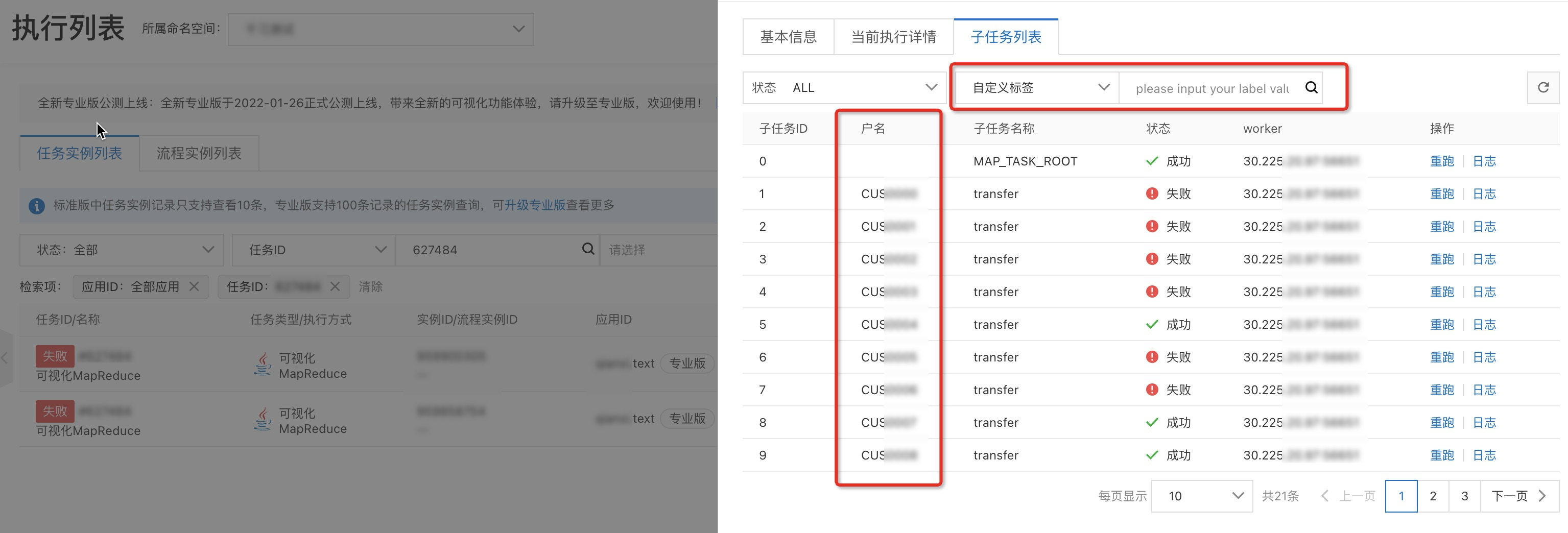
在子任务列表页签,单击子任务操作列的日志,可以查看每个子任务运行的业务日志信息,分析执行状态结果。
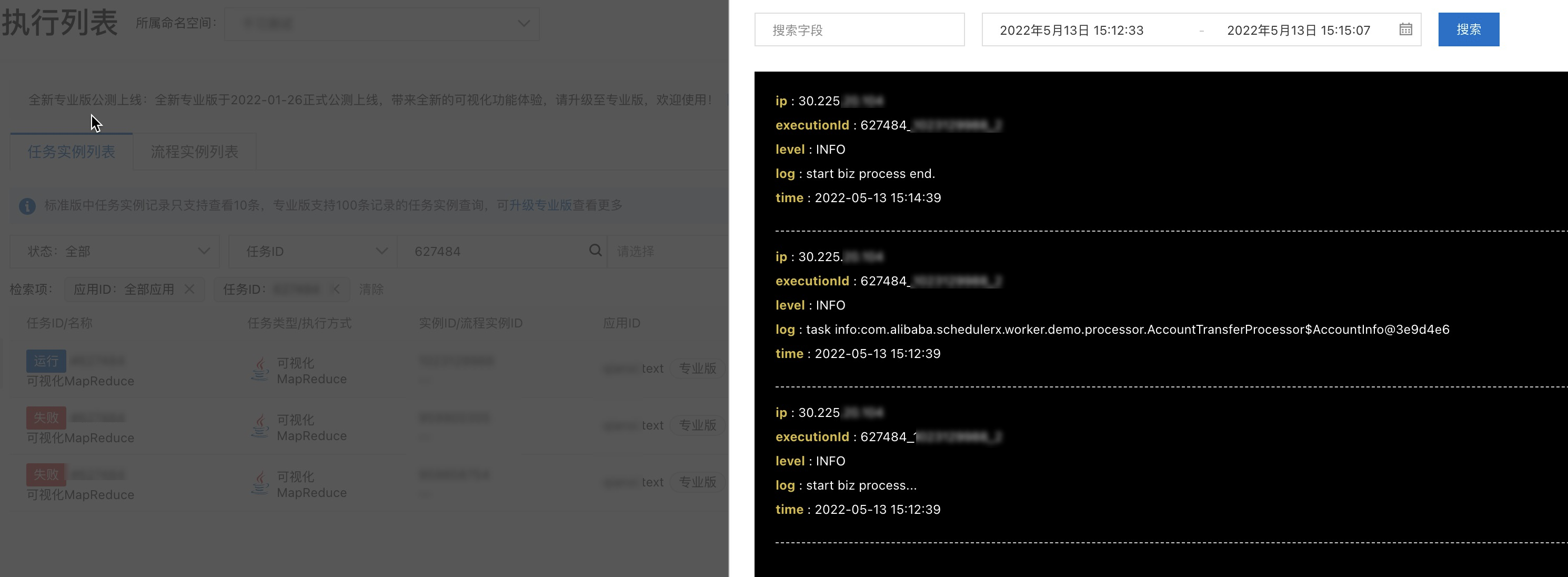
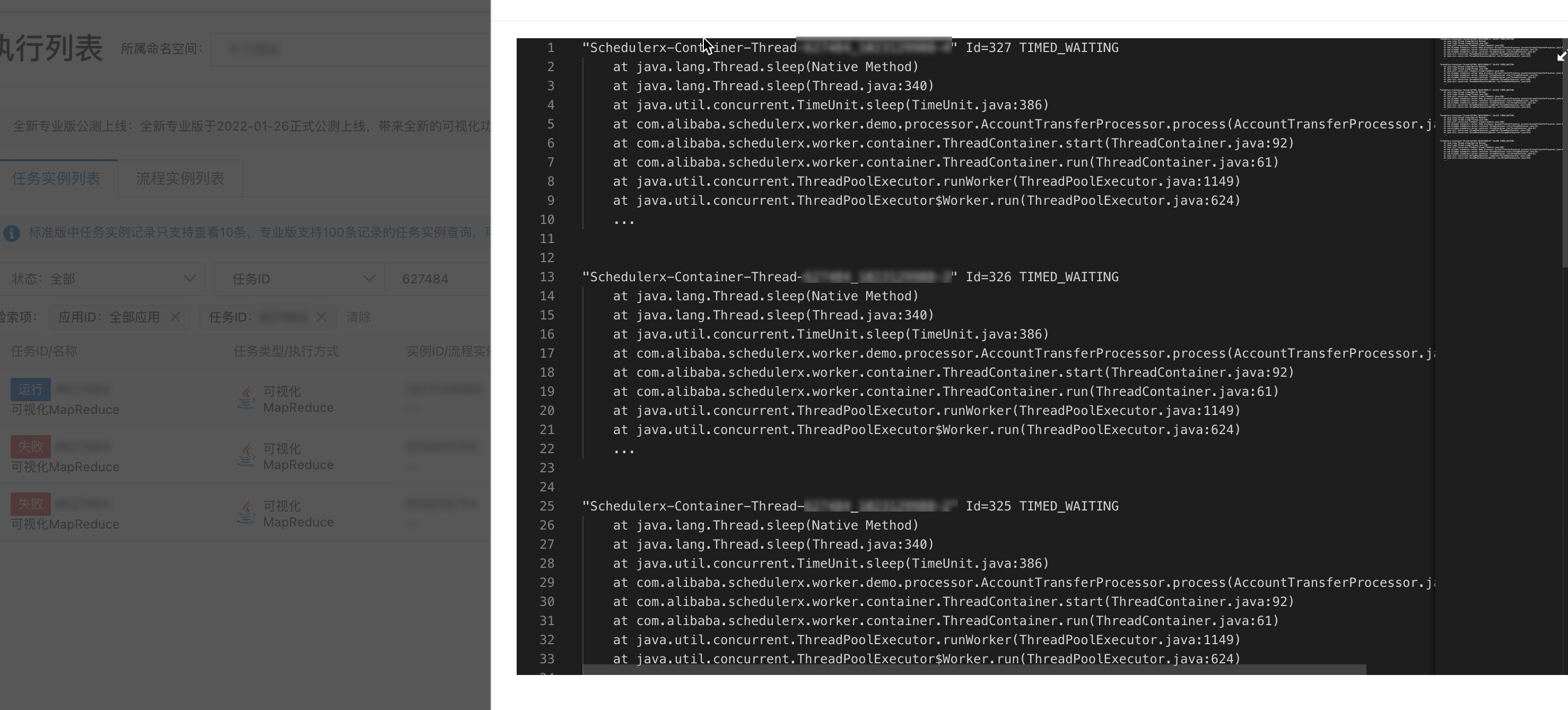
任务执行记录在运行中时,在当前执行详情页签,单击查看堆栈,可以查看对应机器处理线程运行中的情况,分析当前任务运行异常情况。
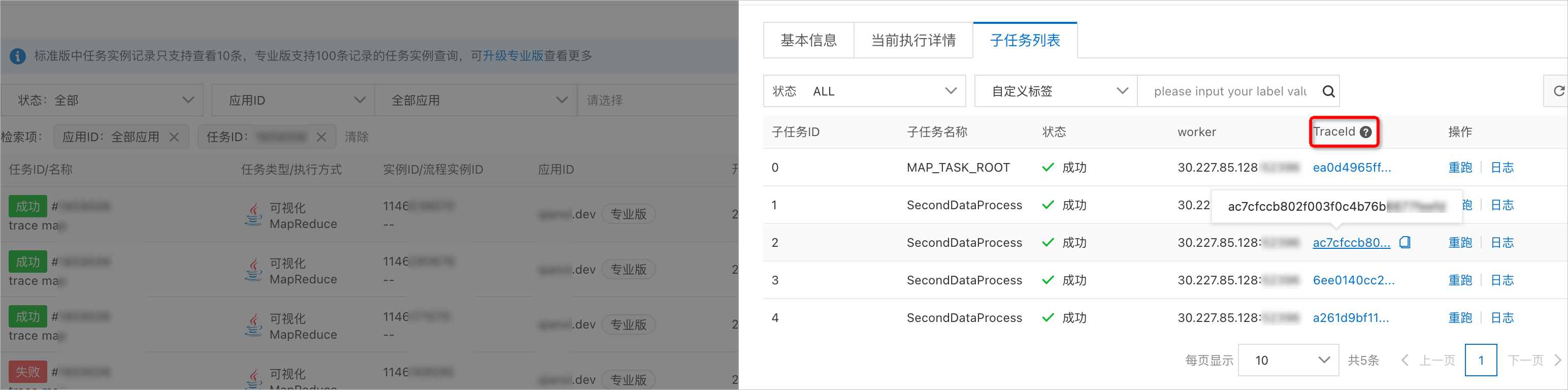
在子任务列表页签,当接入链路追踪后,单击对应的TraceId,可以查询每个子任务的执行调用链路。具体操作,请参见如何接入链路追踪。
相关文档
- 本页导读 (1)