本文介绍如何在挂载文件存储 HDFS 版的Hadoop集群上安装及使用Apache Flink。
前提条件
已开通文件存储 HDFS 版服务并创建文件系统实例和挂载点。具体操作,请参见文件存储HDFS版快速入门。
已为Hadoop集群所有节点安装JDK,且JDK版本不低于1.8。
已下载Apache Hadoop压缩包。建议您选用的Hadoop版本不低于2.7.2,本文使用的Hadoop版本为Apache Hadoop 2.7.2。
已下载Apache Flink压缩包。本文使用的版本为官方提供的预编译版本Apache Flink 1.12.5。
步骤一:配置Hadoop
执行以下命令解压Hadoop压缩包到指定目录。
tar -zxf hadoop-2.7.2.tar.gz -C /usr/local/修改hadoop-env.sh配置文件。
执行以下命令打开hadoop-env.sh配置文件。
vim /usr/local/hadoop-2.7.2/etc/hadoop/hadoop-env.sh配置JAVA_HOME目录,如下所示。
export JAVA_HOME=/usr/java/default
修改core-site.xml配置文件。
执行以下命令打开core-site.xml配置文件。
vim /usr/local/hadoop-2.7.2/etc/hadoop/core-site.xml在core-site.xml配置文件中,配置如下信息。更多信息,请参见挂载文件存储 HDFS 版文件系统。
<configuration> <property> <name>fs.defaultFS</name> <value>dfs://x-xxxxxxxx.cn-xxxxx.dfs.aliyuncs.com:10290</value> <!-- 该地址填写您的挂载点地址 --> </property> <property> <name>fs.dfs.impl</name> <value>com.alibaba.dfs.DistributedFileSystem</value> </property> <property> <name>fs.AbstractFileSystem.dfs.impl</name> <value>com.alibaba.dfs.DFS</value> </property> </configuration>
修改yarn-site.xml配置文件。
执行如下命令打开yarn-site.xml配置文件。
vim /usr/local/hadoop-2.7.2/etc/hadoop/yarn-site.xml在yarn-site.xml配置文件中,配置如下信息。
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>xxxx</value> <!-- 该地址填写集群中ResourceManager的Hostname --> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>16384</value> <!-- 根据您当前的集群能力进行配置此项 --> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> <!-- 根据您当前的集群能力进行配置此项 --> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> <!-- 根据您当前的集群能力进行配置此项 --> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>3584</value> <!-- 根据您当前的集群能力进行配置此项 --> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>14336</value> <!-- 根据您当前的集群能力进行配置此项 --> </property> </configuration>
修改slaves配置文件。
执行如下命令打开slaves配置文件。
vim /usr/local/hadoop-2.7.2/etc/hadoop/slaves在slaves配置文件中,配置集群计算节点的Hostname。
cluster-header-1cluster-worker-1
配置环境变量。
执行如下命令打开/etc/profile配置文件。
vim /etc/profile在/etc/profile配置文件中,配置HADOOP_HOME。
export HADOOP_HOME=/usr/local/hadoop-2.7.2 export HADOOP_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath) export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH执行如下命令使配置生效。
source /etc/profile
配置文件存储 HDFS 版的Java SDK。
您可以下载最新的文件存储HDFS版的Java SDK,将其部署在Hadoop生态系统组件的CLASSPATH上,具体操作,请参见挂载文件存储 HDFS 版文件系统。
cp aliyun-sdk-dfs-x.y.z.jar /usr/local/hadoop-2.7.2/share/hadoop/hdfs执行如下命令将${HADOOP_HOME}文件夹同步到集群的其他节点的相同目录下,并按照步骤6对集群其他节点配置Hadoop的环境变量。
scp -r hadoop-2.7.2/ hadoop@cluster-worker-1:/usr/local/
步骤二:验证Hadoop配置
完成Hadoop配置后,不需要格式化NameNode,也不需要使用start-dfs.sh来启动HDFS相关服务。如需使用YARN服务,只需在ResourceManager节点启动YARN服务。具体验证Hadoop配置成功的方法,请参见验证安装。
步骤三:配置Flink
步骤四:验证Flink配置
使用Flink自带的WordCount.jar对文件存储 HDFS 版上的数据进行读取,并将计算结果写入到文件存储 HDFS 版。
在文件存储 HDFS 版上生成测试数据。
${HADOOP_HOME}/bin/hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar \ randomtextwriter \ -D mapreduce.randomtextwriter.totalbytes=10240 \ -D mapreduce.randomtextwriter.bytespermap=1024 \ dfs://f-xxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/input其中,
f-xxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com为您的文件存储 HDFS 版的挂载点,请根据实际情况替换。执行以下命令,检查环境变量中是否包含HADOOP_CLASSPATH。
echo $HADOOP_CLASSPATH如果环境变量中不包含HADOOP_CLASSPATH,执行以下命令,配置HADOOP_CLASSPATH。
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$($HADOOP_HOME/bin/hadoop classpath)执行以下命,启动Flink Session on YARN。
./flink-1.12.5/bin/yarn-session.sh --detached执行WordCount.jar。
./flink-1.12.5/bin/flink run \ ./flink-1.12.5/examples/batch/WordCount.jar \ --input dfs://f-xxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/flink-test/input \ --output dfs://f-xxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/flink-test/output其中,
f-xxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com为您的文件存储 HDFS 版的挂载点地址,请根据实际情况替换。查看输出在文件存储 HDFS 版实例上的部分结果。
${HADOOP_HOME}/bin/hadoop fs -cat dfs://f-xxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/flink-test/output | tail -20如果返回以下类似信息,则表示Flink配置成功。
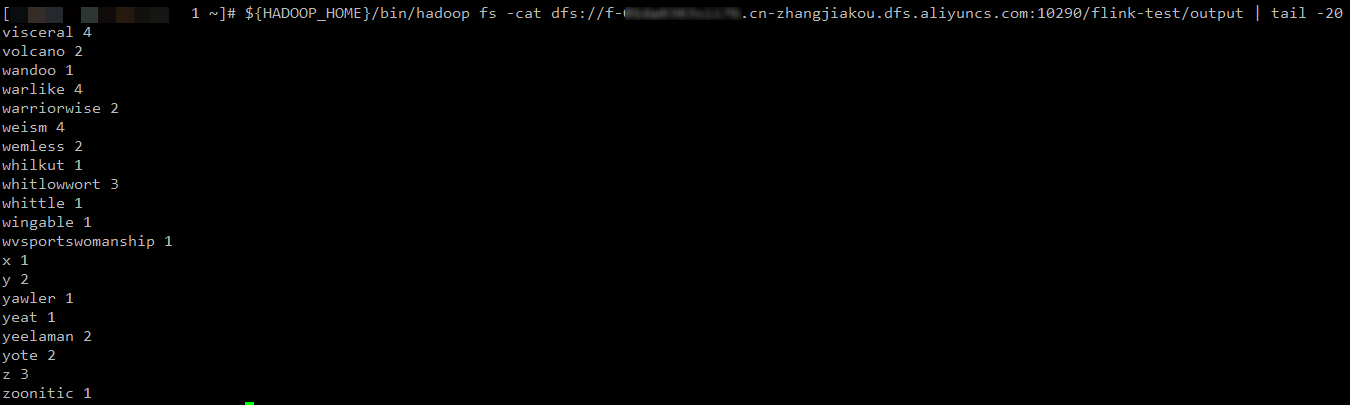
- 本页导读 (1)