前言
相信大家已经会用cqlsh访问Cassandra。但是实际应用中我们需要自己开发代码去访问Cassandra,并不想像cqlsh这样只是简单的连接一个节点,敲一些cql。我们需要连接多个节点,平衡请求到每个Cassandra node上,我们要管理连接池等等。当然这些都不用大家操心,社区版本的SDK已经完成了这些功能,我们接下来将教大家如果使用SDK进行访问。
准备工作
- 获取访问地址。
-
进入Cassandra控制台> 数据库连接。
- 查看私网连接地址。由于安全考虑,默认不开通公网,如需获取公网连接地址,请单击申请外网地址。
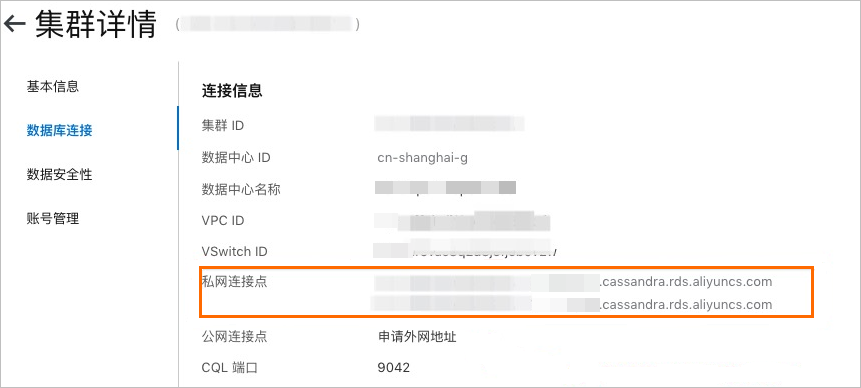 说明 根据集群规模不同,访问地址个数也不相同。如果有多个尽量使用多个地址,避免单个节点挂掉连接不上集群。公网和内网访问方式几乎相同,只是地址不同。
说明 根据集群规模不同,访问地址个数也不相同。如果有多个尽量使用多个地址,避免单个节点挂掉连接不上集群。公网和内网访问方式几乎相同,只是地址不同。
-
- 添加白名单。
实际访问之前,请确保已经将客户机的IP加入白名单,具体操作参见设置白名单。
多语言代码示例
Java访问
- Maven加入依赖。
<dependency> <groupId>com.datastax.cassandra</groupId> <artifactId>cassandra-driver-core</artifactId> <version>3.7.2</version> </dependency>注意 这个依赖会引入一些公共库,为了避免依赖冲突导致不必要的麻烦,请先在一个新工程中测试。 - 编写Java访问代码。
import com.datastax.driver.core.Cluster; import com.datastax.driver.core.PlainTextAuthProvider; import com.datastax.driver.core.ResultSet; import com.datastax.driver.core.Session; public class Demo { public static void main(String[] args) { // 此处填写数据库连接点地址(公网或者内网的),控制台有几个就填几个。 // 实际上SDK最终只会连上第一个可连接的连接点并建立控制连接,填写多个是为了防止单个节点挂掉导致无法连接数据库。 // 此处无需关心连接点的顺序,因为SDK内部会先打乱连接点顺序避免不同客户端的控制连接总是连一个点。 // 千万不要把公网和内网的地址一起填入。 String[] contactPoints = new String[]{ "cds-xxxxxxxx-core-003.cassandra.rds.aliyuncs.com", "cds-xxxxxxxx-core-002.cassandra.rds.aliyuncs.com" }; Cluster cluster = Cluster.builder() .addContactPoints(contactPoints) // 填写账户名密码(如果忘记可以在 账号管理 处重置) .withAuthProvider(new PlainTextAuthProvider("cassandra", "123456")) // 如果进行的是公网访问,需要在账号名后面带上 @public 以切换至完全的公网链路。 // 否则无法在公网连上所有内部节点,会看到异常或者卡顿,影响本地开发调试。 // 后续会支持网络链路自动识别(即无需手动添加@public)具体可以关注官网Changelog。 //.withAuthProvider(new PlainTextAuthProvider("cassandra@public", "123456")) .build(); // 初始化集群,此时会建立控制连接(这步可忽略,建立Session时候会自动调用) cluster.init(); // 连接集群,会对每个Cassandra节点建立长连接池。 // 所以这个操作非常重,不能每个请求创建一个Session。合理的应该是每个进程预先创建若干个。 // 通常来说一个够用了,你也可以根据自己业务测试情况适当调整,比如把读写的Session分开管理等。 Session session = cluster.connect(); // 查询,此处我们查一下权限相关的表,看看我们创建了几个角色。 // 这是系统表,默认只有cassandra这个superuser账户有SELECT权限。 // 如果你使用其他账号测试,可以换一个表或者授权一下。 ResultSet res = session.execute("SELECT * FROM system_auth.roles"); // ResultSet 实现了 Iterable 接口,我们直接将每行信息打印到控制台 res.forEach(System.out::println); // 关闭Session session.close(); // 关闭Cluster cluster.close(); } }
Python访问
- 安装SDK库。
# 指定版本安装(建议安装3.x版本) pip install cassandra-driver==3.19.0 # 安装最新版本 pip install cassandra-driver # https://pypi.org/project/cassandra-driver/#history - 编写Python访问代码。
#!/usr/bin/env python # -*- coding: UTF-8 -*- import logging import sys from cassandra.cluster import Cluster from cassandra.auth import PlainTextAuthProvider logging.basicConfig(stream=sys.stdout, level=logging.INFO) cluster = Cluster( # 此处填写数据库连接点地址(公网或者内网的),控制台有几个就填几个。 # 实际上SDK最终只会连上第一个可连接的连接点并建立控制连接,填写多个是为了防止单个节点挂掉导致无法连接数据库。 # 此处无需关心连接点的顺序,因为SDK内部会先打乱连接点顺序避免不同客户端的控制连接总是连一个点。 # 千万不要把公网和内网的地址一起填入。 contact_points=["cds-xxxxxxxx-core-003.cassandra.rds.aliyuncs.com", "cds-xxxxxxxx-core-002.cassandra.rds.aliyuncs.com"], # 填写账户名密码(如果忘记可以在 账号管理 处重置) auth_provider=PlainTextAuthProvider("cassandra", "123456")) # 果进行的是公网访问,需要在账号名后面带上 @public 以切换至完全的公网链路。 # 否则无法在公网连上所有内部节点,会看到异常或者卡顿,影响本地开发调试。 # 后续会支持网络链路自动识别(即无需手动添加 @public)具体可以关注官网Changelog。 # auth_provider=PlainTextAuthProvider("cassandra@public", "123456")) # 连接集群,会对每个Cassandra节点建立长连接池。 # 所以这个操作非常重,不能每个请求创建一个Session。合理的应该是每个进程预先创建若干个。 # 通常来说一个够用了,你也可以根据自己业务测试情况适当调整,比如把读写的Session分开管理等。 session = cluster.connect() # 查询,此处我们查一下权限相关的表,看看我们创建了几个角色。 # 这是系统表,默认只有cassandra这个superuser账户有SELECT权限。 # 如果你使用其他账号测试,可以换一个表或者授权一下。 rows = session.execute('SELECT * FROM system_auth.roles') # 打印每行信息到控制台 for row in rows: print("# row: {}".format(row)) # 关闭Session session.shutdown() # 关闭Cluster cluster.shutdown() - 其他语言访问。
其他语言访问接口类似Python和Java,可以参考github社区文档: