本文介绍如何配置E-MapReduce上的HDFS服务、HIVE服务、SPARK服务、HBase服务来使用文件存储 HDFS 版。
前提条件
已完成数据迁移。具体操作,请参见E-MapReduce数据迁移。
配置HDFS服务
在集群管理页面,找到需要挂载文件存储 HDFS 版的目标E-MapReduce集群,单击管理。
更改配置。
选择,单击配置。
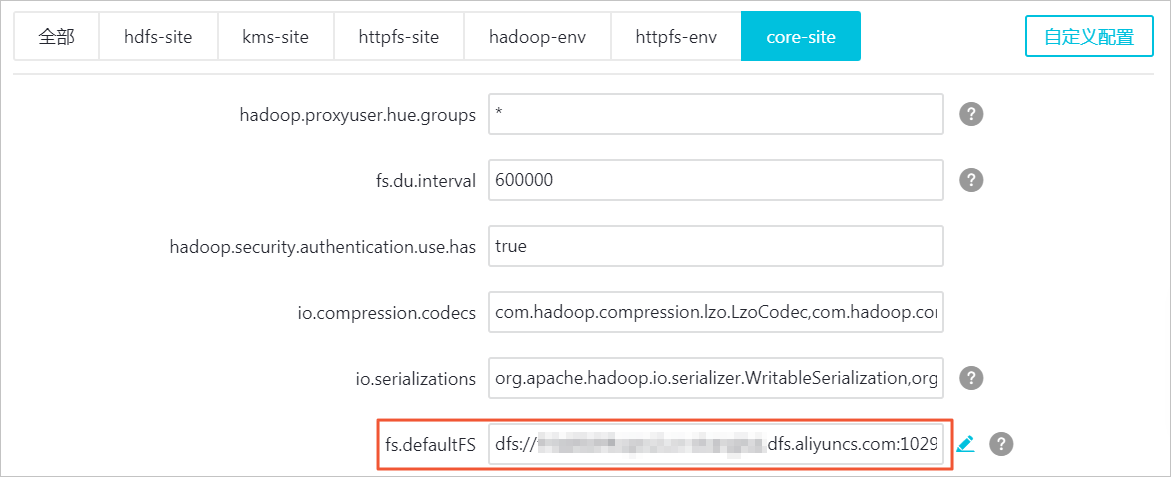
在服务配置中,单击core-site。
找到配置项fs.defaultFS,将其值替换为您的文件存储 HDFS 版挂载点域名(dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290)。
单击保存,在确认保存对话框中,输入执行原因,单击确定。
单击部署客户端配置,在确认保存对话框中,输入执行原因,单击确定。
重启YARN服务。
选择。
在页面右侧的操作栏中,单击重启All Components。
配置Hive服务
配置HDFS服务完成后,才能配置Hive服务。
在配置Hive服务之前,请确认/user/hive/目录中的数据已完成全量迁移。具体操作,请参见迁移开源HDFS的数据到文件存储 HDFS 版。
更改配置。
选择,单击配置。
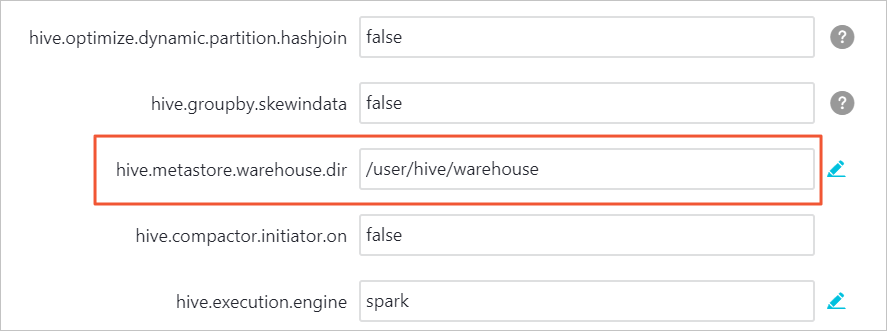
在服务配置中,单击hive-site。
找到配置项hive.metastore.warehouse.dir,删除其对应值中的E-MapReduce HDFS文件系统域名,只保留/user/hive/warehouse。
单击保存,在确认保存对话框中,输入执行原因,单击确定。
单击部署客户端配置,在确认保存对话框中,输入执行原因,单击确定。
修改元数据。
在hivemetastore-site中,获取数据库相关信息。
在配置项javax.jdo.option.ConnectionURL中,获取MySQL服务的主机名和元数据存储的数据库。
在配置项javax.jdo.option.ConnectionUserName中,获取MySQL服务的用户名。
在配置项javax.jdo.option.ConnectionPassword中,获取MySQL服务的用户密码。
Hive的元数据存储在MySQL,进入存储Hive元数据的MySQL数据库hivemeta,修改CTLGS表、DBS表和SDS表相应的值。
执行
use hivemeta命令,进入存储Hive元数据的MySQL数据库hivemeta。修改表CTLGS中的数据。
执行
select * from CTLGS命令,查询表CTLGS中的数据。返回结果示例如下:+---------+------+---------------------------+-----------------------------------------------------------------------------+ | CTLG_ID | NAME | DESC | LOCATION_URI | +---------+------+---------------------------+-----------------------------------------------------------------------------+ | 1 | hive | Default catalog, for Hive | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse | +---------+------+---------------------------+-----------------------------------------------------------------------------+ 1 row in set (0.00 sec)修改LOCATION_URI为文件存储 HDFS 版的挂载点域名,请根据实际情况进行修改。
修改CTLG_ID为1的LOCATION_URI,示例如下:
MariaDB [hivemeta]> UPDATE CTLGS -> SET LOCATION_URI = 'dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/user/hive/warehouse' -> WHERE CTLG_ID = 1;若返回如下信息,则表示修改成功。
Query OK, 0 rows affected (0.00 sec) Rows matched: 1 Changed: 0 Warnings: 0
修改表DBS中的数据。
执行
select * from DBS命令,查询表DBS中的数据。返回结果示例如下:+-------+-----------------------+-----------------------------------------------------------------------------------------+--------------------------+------------+------------+-----------+ | DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME | +-------+-----------------------+-----------------------------------------------------------------------------------------+--------------------------+------------+------------+-----------+ | 1 | Default Hive database | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse | default | public | ROLE | hive | | 2 | NULL | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs.db | analysis_logs | root | USER | hive | | 3 | NULL | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs_report.db | analysis_logs_report | root | USER | hive | | 4 | NULL | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs_report_old.db | analysis_logs_report_old | root | USER | hive | +-------+-----------------------+-----------------------------------------------------------------------------------------+--------------------------+------------+------------+-----------+ 4 rows in set (0.00 sec)修改DB_LOCATION_URI为文件存储 HDFS 版的挂载点域名,请根据实际情况进行修改。
修改DB_ID为1的DB_LOCATION_URI,示例如下:
MariaDB [hivemeta]>UPDATE DBS -> SET DB_LOCATION_URI = 'dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/user/hive/warehouse' -> WHERE DB_ID = 1;若返回如下信息,则表示修改成功。
Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0
修改表SDS中的数据。
执行
select * from SDS命令,查询表SDS中的数据。返回结果示例如下:+-------+-------+---------------------------------------------------------------+---------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+-------------+----------------------------------------------------------------+----------+ | SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID | +-------+-------+---------------------------------------------------------------+---------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+-------------+----------------------------------------------------------------+----------+ | 1 | 1 | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs.db/original_log_bj_partitioned | -1 | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat | 1 | | 2 | 2 | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs.db/original_log_hz_partitioned | -1 | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat | 2 | | 3 | 3 | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs.db/original_log_sh_partitioned | -1 | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat | 3 | | 29 | 22 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs_report.db/hz_writethroughput_top_daily | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 29 | ........ | 548 | 80 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs_report.db/hz_readthroughput_top_yearly | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 548 | | 549 | 81 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs_report_old.db/hz_writethroughput_top_yearly_20190709 | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 549 | | 550 | 82 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://emr-header-1.cluster-125428:9000/user/hive/warehouse/analysis_logs_report.db/hz_writethroughput_top_yearly | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 550 | +-------+-------+---------------------------------------------------------------+---------------+---------------------------+------------------------------------------------------------------------------------------------------------------------ 536 rows in set (0.00 sec)修改LOCATION属性中的值为文件存储 HDFS 版的挂载点域名,请根据实际情况进行修改。
修改SD_ID为1的LOCATION,示例如下:
MariaDB [hivemeta]> UPDATE SDS SET LOCATION = "dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/user/hive/warehouse/analysis_logs.db/original_log_bj_partitioned" WHERE SD_ID = 1;若返回如下信息,则表示修改成功。
Query OK, 0 rows affected (0.01 sec) Rows matched: 1 Changed: 0 Warnings: 0
在页面右侧的操作栏,单击重启All Components,重启服务。
配置Spark服务
配置HDFS服务完成后,才能配置Spark服务。
配置Spark服务前,请确认/spark-history目录中的数据已经完成了全量迁移。具体操作,请参见迁移开源HDFS的数据到文件存储 HDFS 版。
更改配置。
选择,单击配置。
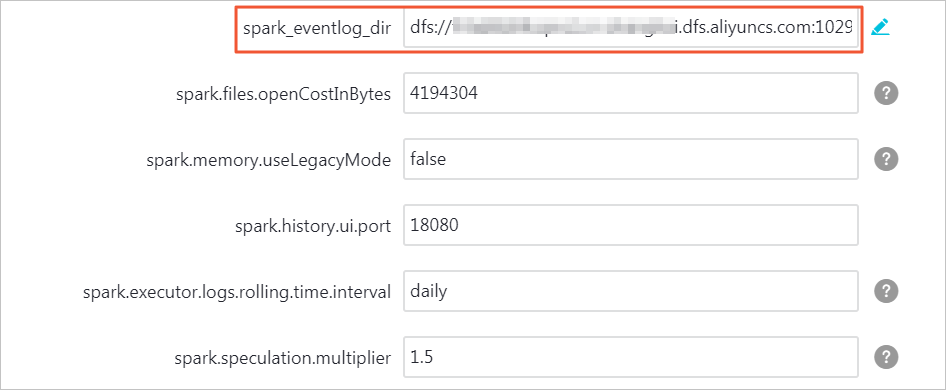
在服务配置中,单击spark-defaults。
找到配置项spark_eventlog_dir,将其对应的值替换为您文件存储 HDFS 版挂载点域名。
单击保存,在确认保存对话框中,输入执行原因,单击确定。
单击部署客户端配置,在确认保存对话框中,输入执行原因,单击确定。
放置SDK包。
将文件存储 HDFS 版的SDK包(aliyun-sdk-dfs-1.0.2-beta.jar),放置到E-MapReduce Spark服务存放jar包的目录下。
cp ~/aliyun-sdk-dfs-1.0.2-beta.jar /opt/apps/ecm/service/spark/2.4.3-1.0.0/package/spark-2.4.3-1.0.0-bin-hadoop2.8/jars/一般情况下,放置到/opt/apps/ecm/service/spark/x.x.x-x.x.x/package/spark-x.x.x-x.x.x-bin-hadoopx.x/jars目录。
说明集群中的每台机器都需要添加该SDK包。
在页面右侧的操作栏,单击重启All Components,重启服务。
配置HBase服务
配置HDFS服务完成后,才能配置HBase服务。
配置HBase服务前,请确认/hbase目录中的数据已经完成了全量迁移。具体操作,请参见迁移开源HDFS的数据到文件存储 HDFS 版。
更改配置。
选择,单击配置。
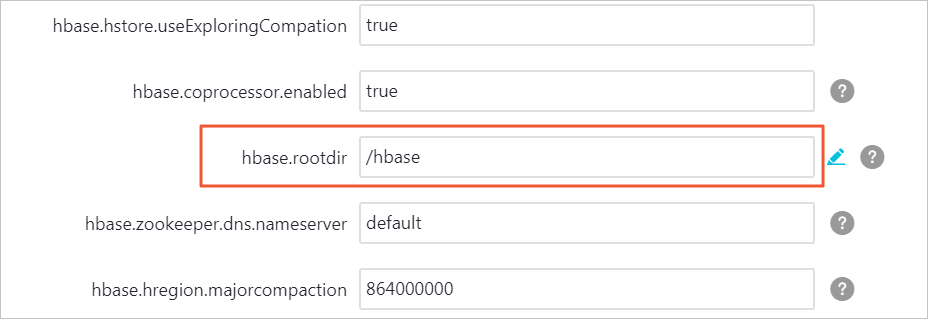
在服务配置中,单击Hbase-site。
找到配置项hbase.rootdir,删除其对应值中的E-MapReduce HDFS文件系统域名,只保留/hbase。
单击保存,在确认保存对话框中,输入执行原因,单击确定。
单击部署客户端配置,在确认保存对话框中,输入执行原因,单击确定。
在页面右侧的操作栏,单击重启All Components,重启服务。
关闭HDFS服务
关闭HDFS服务前,请确认原来E-MapReduce HDFS上存储的数据都已经迁移到文件存储 HDFS 版。具体操作,请参见迁移开源HDFS的数据到文件存储 HDFS 版。
选择。
在页面右侧的操作栏,单击重启All Components,重启服务。
在执行集群操作对话框中,输入执行原因,单击确定。
验证服务正确性
hadoop的验证
使用E-MapReduce hadoop中自带的测试包hadoop-mapreduce-examples-2.x.x.jar进行测试。该测试包默认放置在/opt/apps/ecm/service/hadoop/2.x.x-1.x.x/package/hadoop-2.x.x-1.x.x/share/hadoop/mapreduce/目录下。
执行以下命令,在/tmp/randomtextwriter目录下生成128 MB大小的文件。
hadoop jar /opt/apps/ecm/service/hadoop/2.8.5-1.3.1/package/hadoop-2.8.5-1.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=134217728 -D mapreduce.job.maps=2 -D mapreduce.job.reduces=2 /tmp/randomtextwriter其中
hadoop-mapreduce-examples-2.8.5.jar为E-MapReduce的测试包,请根据实际情况修改。执行以下命令验证文件是否生成成功,从而验证文件系统实例的连通性。
hadoop fs -ls dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/tmp/randomtextwriter其中
f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com为您的文件存储 HDFS 版挂载点域名,请根据实际情况修改。如果看到_SUCCESS和part-m-00000两个文件,表示连通成功。如下所示:
-rwxrwxrwx 3 root root 0 2019-07-26 11:05 dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/tmp/randomtextwriter2/_SUCCESS -rwxrwxrwx 3 root root 137774743 2019-07-26 11:05 dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/tmp/randomtextwriter2/part-m-000000如果连通失败(例如,报错No such file or directory),请排查连通性问题。具体操作,请参见创建文件系统实例后,为什么无法访问文件存储 HDFS 版?
Spark的验证
使用E-MapReduce Spark中自带的测试包spark-examples_2.x-2.x.x.jar进行测试。该测试包默认放置在/opt/apps/ecm/service/spark/2.x.x-1.0.0/package/spark-2.x.x-1.0.0-bin-hadoop2.8/examples/jars下。
执行以下命令,在/tmp/randomtextwriter目录下生成128M大小的文件。
hadoop jar /opt/apps/ecm/service/hadoop/2.8.5-1.3.1/package/hadoop-2.8.5-1.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=134217728 -D mapreduce.job.maps=2 -D mapreduce.job.reduces=2 /tmp/randomtextwriter其中
hadoop-mapreduce-examples-2.8.5.jar为E-MapReduce的测试包,请根据实际情况修改。使用spark测试包从文件存储 HDFS 版上读取测试文件并按照word count的格式展示。
spark-submit --master yarn --executor-memory 2G --executor-cores 2 --class org.apache.spark.examples.JavaWordCount /opt/apps/ecm/service/spark/2.4.3-1.0.0/package/spark-2.4.3-1.0.0-bin-hadoop2.8/examples/jars/spark-examples_2.11-2.4.3.jar /tmp/randomtextwriter如果回显信息类似如下图所示,表示配置成功。
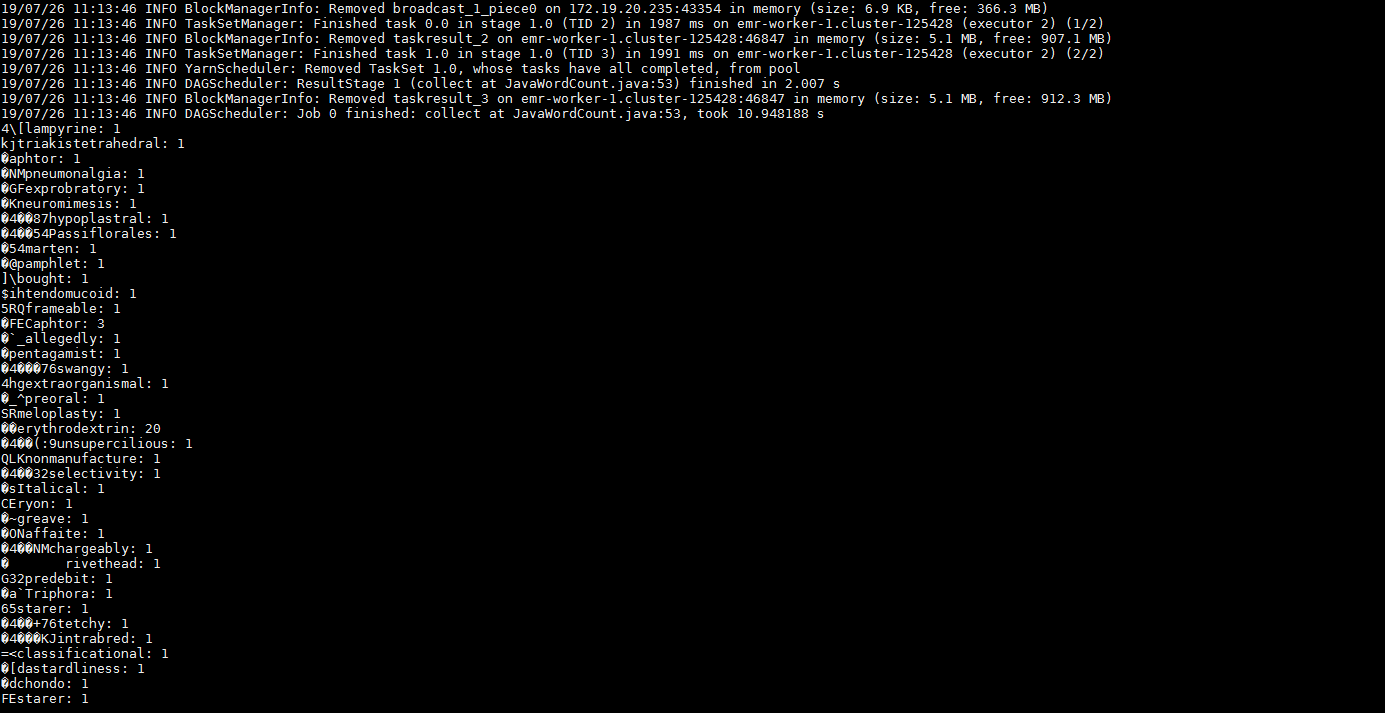
Hive的验证
执行以下命令进入Hive命令界面。
hive执行以下命令创建测试表。
create table default.testTable(id int , name string ) row format delimited fields terminated by '\t' lines terminated by '\n';执行以下命令查看测试表。
如果回显信息中的Location属性对应的值为文件存储 HDFS 版的路径,则表示配置Hive成功。如果不是,请重新配置。具体操作,请参见配置Hive服务。
执行命令
desc formatted default.testTable ;返回信息
OK 2019-07-26 11:23:25,133 INFO [9d1aeaf3-19d8-461b-952f-6fcfed900e69 main] mapred.FileInputFormat: Total input files to process : 1 # col_name data_type comment id int name string # Detailed Table Information Database: default OwnerType: USER Owner: root CreateTime: Fri Jul 26 11:23:12 CST 2019 LastAccessTime: UNKNOWN Retention: 0 Location: dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/user/hive/warehouse/testtable Table Type: MANAGED_TABLE Table Parameters: COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"id\":\"true\",\"name\":\"true\"}} bucketing_version 2 numFiles 0 numRows 0 rawDataSize 0 totalSize 0 transient_lastDdlTime 1564111392 # Storage Information SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.TextInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Compressed: No Num Buckets: -1 Bucket Columns: [] Sort Columns: [] Storage Desc Params: field.delim \t line.delim \n serialization.format \t Time taken: 0.134 seconds, Fetched: 34 row(s)
HBase的验证
执行
hbase shell命令,进入hbase shell命令界面。在HBase中创建测试表。
创建测试表。
create 'hbase_test','info'写入测试数据。
put 'hbase_test','1', 'info:name' ,'Sariel'put 'hbase_test','1', 'info:age' ,'22'put 'hbase_test','1', 'info:industry' ,'IT'
执行以下命令查看文件存储 HDFS 版的/hbase/data/default/路径,如果/hbase/data/default/路径下有hbase_test目录,则证明配置链接成功。
hadoop fs -ls /hbase/data/default
后续步骤
- 本页导读 (1)