本文介绍如何通过外表查询OSS数据文件,并将OSS中的数据文件导入AnalyticDB MySQL数仓版(3.0)。目前支持的OSS数据文件格式有Parquet、CSV和ORC。
前提条件
已在OSS服务所在的同一VPC中创建AnalyticDB MySQL数仓版(3.0)集群,并完成设置白名单、创建账号等准备工作。详情请参见AnalyticDB MySQL数仓版(3.0)使用流程。
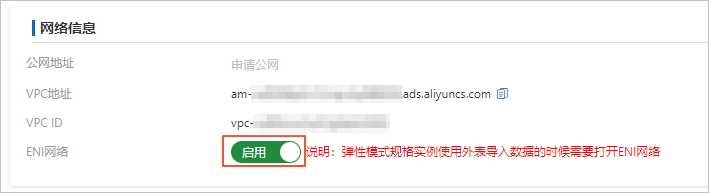
AnalyticDB MySQL数仓版(3.0)弹性模式集群,您需要在集群信息页面的网络信息区域,打开启用ENI网络的开关。
示例数据说明
本示例将oss_import_test_data.csv文件上传至OSS中的<bucket-name>.oss-cn-hangzhou.aliyuncs.com/adb/目录,数据行分隔符为换行符,列分隔符为半角分号(;),文件示例数据如下所示:
uid;other
12;hello_world_1
27;hello_world_2
28;hello_world_3
33;hello_world_4
37;hello_world_5
40;hello_world_6
... 操作步骤
本示例将oss_import_test_data.txt中的数据导入AnalyticDB MySQL版的adb_demo库中。
连接目标AnalyticDB MySQL集群。详细操作步骤,请参见连接集群。
创建目标数据库。详细操作步骤,请参见创建数据库。
本示例中,AnalyticDB MySQL集群的目标库名为
adb_demo。创建外部映射表。使用
CREATE TABLE语句在目标库adb_demo中创建CSV、Parquet或ORC格式的OSS外部映射表。具体语法,请参见不带分区的数据文件创建OSS外表或带分区的数据文件创建OSS外表。查询OSS数据。本步骤以查询外部映射表
oss_import_test_external_table为例,查询对应OSS中的数据。查询外部映射表和查询AnalyticDB MySQL版内表语法相同,您可以直接进行查询,查询语句如下:
SELECT uid, other FROM oss_import_test_external_table WHERE uid < 100 LIMIT 10;说明对于CSV格式、Parquet和ORC格式数据文件,数据量越大,通过外表查询的性能损耗越大。如果您需要进一步提升查询效率,建议您按照后续步骤将OSS数据导入AnalyticDB MySQL版后再做查询。
创建目标表。在目标数据库
adb_demo中创建一张目标表adb_oss_import_test,用于存储从OSS导入的数据。建表语句如下:CREATE TABLE IF NOT EXISTS adb_oss_import_test ( uid string, other string ) DISTRIBUTED BY HASH(uid);执行INSERT语句将OSS数据导入AnalyticDB MySQL版。
重要使用
INSERT INTO或INSERT OVERWRITE SELECT导入数据时,默认是同步执行流程。如果数据量较大,达到几百GB,客户端到AnalyticDB MySQL服务端的连接会中断,导致数据导入失败。因此,如果您的数据量较大时,推荐使用SUBMIT JOB INSERT OVERWRITE SELECT异步执行导入。方式一:执行INSERT INTO导入数据,当主键重复时会自动忽略当前写入数据,不进行更新覆盖,作用等同于
INSERT IGNORE INTO,详情请参见INSERT INTO。示例如下:INSERT INTO adb_oss_import_test SELECT * FROM oss_import_test_external_table;方式二:执行INSERT OVERWRITE导入数据,会覆盖表中原有的数据。示例如下:
INSERT OVERWRITE adb_oss_import_test SELECT * FROM oss_import_test_external_table;方式三:异步执行INSERT OVERWRITE导入数据。 通常使用
SUBMIT JOB提交异步任务,由后台调度,可以在写入任务前增加Hint(/*+ direct_batch_load=true*/)加速写入任务。详情请参见异步写入。示例如下:SUBMIT JOB INSERT OVERWRITE adb_oss_import_test SELECT * FROM oss_import_test_external_table;返回结果如下:
+---------------------------------------+ | job_id | +---------------------------------------+ | 2020112122202917203100908203303****** |关于异步提交任务详情,请参见异步提交导入任务。
不带分区的数据文件创建OSS外表
创建OSS CSV格式外表
语法如下:
CREATE TABLE IF NOT EXISTS oss_import_test_external_table ( uid string, other string ) ENGINE='OSS' TABLE_PROPERTIES='{ "endpoint":"oss-cn-hangzhou-internal.aliyuncs.com", "url":"oss://<bucket-name>/adb_data/", "accessid":"LTAIF****5FsE", "accesskey":"Ccw****iWjv", "delimiter":";", "skip_header_line_count":1, }';参数
是否必填
说明
ENGINE='OSS'必填
表示该表是外部表,使用的存储引擎是OSS。
TABLE_PROPERTIES用于告知AnalyticDB MySQL版如何访问OSS中的数据。
endpointOSS的EndPoint(地域节点)。
说明目前仅支持AnalyticDB MySQL版通过ECS的VPC网络访问OSS。
登录OSS控制台,单击目标Bucket,在Bucket概览页面查看EndPoint(地域节点)。
urlOSS中源数据文件或文件夹的绝对路径。建议文件夹绝对路径以正斜线(/)结尾。
示例:
文件:
oss://<bucket-name>/adb/oss_import_test_data.csv。文件夹:
oss://<bucket-name>/adb_data/。说明若指定为源数据文件夹的路径,成功创建外表后,外表中的数据为该文件夹下的所有数据。
accessid您在访问OSS中的文件或文件夹时所持有的AccessKey ID。
如何获取您的AccessKey ID和AccessKey Secret,请参见账号与权限。
accesskey您在访问OSS中的文件或文件夹时所持有的AccessKey Secret。
delimiter定义CSV数据文件的列分隔符。例如您可以将列分隔符设置为英文逗号(,)。
null_value选填
定义CSV数据文件的
NULL值。默认将空值定义为NULL,即"null_value": ""。说明AnalyticDB MySQL版集群需为V3.1.4.2或以上版本才支持配置该参数。关于版本信息,请参见新功能发布记录。
ossnull选择CSV数据文件中
NULL值的对应规则。取值范围如下:1(默认值):表示
EMPTY_SEPARATORS,即仅将空值定义为NULL。示例:
a,"",,c --> "a","",NULL,"c"2:表示
EMPTY_QUOTES,即仅将""定义为NULL。示例:
a,"",,c --> "a",NULL,"","c"3:表示
BOTH,即同时将空值和""定义为NULL。示例:
a,"",,c --> "a",NULL,NULL,"c"4:表示
NEITHER,即空值和""均不定义为NULL。示例:
a,"",,c --> "a","","","c"
说明上述各示例的前提为
"null_value": ""。skip_header_line_count定义导入数据时需要在开头跳过的行数。CSV文件第一行为表头,若设置该参数为1,导入数据时可自动跳过第一行的表头。
默认取值为0,即不跳过。
oss_ignore_quote_and_escape是否忽略字段值中的引号和转义。默认取值为
false,即不忽略字段值中的引号和转义。说明AnalyticDB MySQL版集群需为V3.1.4.2或以上版本才支持设置该参数。关于版本信息,请参见新功能发布记录。
AnalyticDB MySQL支持通过OSS的CSV格式的外表读写Hive TEXT文件。建表语句如下:
CREATE TABLE adb_csv_hive_format_oss ( a tinyint, b smallint, c int, d bigint, e boolean, f float, g double, h varchar, i varchar, -- binary j timestamp, k DECIMAL(10, 4), l varchar, -- char(10) m varchar, -- varchar(100) n date ) ENGINE = 'OSS' TABLE_PROPERTIES='{ "format": "csv", "endpoint":"oss-cn-hangzhou-internal.aliyuncs.com", "accessid":"LTAIF****5FsE", "accesskey":"Ccw****iWjv", "url":"oss://<bucket-name>/adb_data/", "delimiter": "\\1", "null_value": "\\\\N", "oss_ignore_quote_and_escape": "true", "ossnull": 2, }';说明在创建OSS的CSV格式的外表来读取Hive TEXT文件时,需注意如下几点:
Hive TEXT文件的默认列分隔符为
\1。若您需要通过OSS的CSV格式的外表读写Hive TEXT文件,您可以在配置delimiter参数时将其转义为\\1。Hive TEXT文件的默认
NULL值为\N。若您需要通过OSS的CSV格式的外表读写Hive TEXT文件,您可以在配置null_value参数时将其转义为\\\\N。Hive的其他基本数据类型(如
BOOLEAN)与AnalyticDB MySQL版的数据类型一一对应,但BINARY、CHAR(n)和VARCHAR(n)类型均对应AnalyticDB MySQL版中的VARCHAR类型。
创建OSS Parquet格式或OSS ORC格式外表
以Parquet格式为例,创建OSS外表的语句如下:
CREATE TABLE IF NOT EXISTS oss_import_test_external_table ( uid string, other string ) ENGINE='OSS' TABLE_PROPERTIES='{ "endpoint":"oss-cn-hangzhou-internal.aliyuncs.com", "url":"oss://<bucket-name>/adb_data/", "accessid":"LTAIF****5FsE", "accesskey":"Ccw****iWjv", "format":"parquet" }';参数
说明
ENGINE= 'OSS'表示该表是外部表,使用的存储引擎是OSS。
TABLE_PROPERTIES用于告知AnalyticDB MySQL版如何访问OSS中的数据。
endpointOSS的EndPoint(地域节点)(域名节点)。
说明目前仅支持AnalyticDB MySQL版通过OSS中ECS的VPC网络(内网)访问OSS。
登录OSS控制台,单击目标Bucket,在Bucket概览页面查看EndPoint(地域节点)。
urlOSS中源数据文件或文件夹的绝对路径。建议文件夹绝对路径以正斜线(/)结尾。
示例:
文件:
oss://<bucket-name>/adb/oss_import_test_data.parquet。文件夹:
oss://<bucket-name>/adb_data/。
说明建表时请将示例中的
url替换为实际的OSS路径。若指定为源数据文件夹的路径,成功创建外表后,外表中的数据为该文件夹下的所有数据。
accessid您在访问OSS中的文件或文件夹时所持有的AccessKey ID。
如何获取您的AccessKey ID和AccessKey Secret,请参见账号与权限。
accesskey您在访问OSS中的文件或文件夹时所持有的AccessKey Secret。
format数据文件的格式。
创建Parquet格式文件的外表时需设置为
parquet。创建ORC格式文件的外表时需设置为
orc。
说明不指定format时,默认格式为CSV。
说明外表创建语句中的列名需与Parquet或ORC文件中该列的名称完全相同(可忽略大小写),且列的顺序需要一致。
创建外表时,可以仅选择Parquet或ORC文件中的部分列作为外表中的列,未被选择的列不会被导入。
如果创建外表创建语句中出现了Parquet或ORC文件中不存在的列,针对该列的查询结果均会返回NULL。
Parquet文件与AnalyticDB MySQL版3.0的数据类型映射关系如下表。
Parquet基本类型
Parquet的logicalType类型
AnalyticDB MySQL版3.0的数据类型
BOOLEAN
无
BOOLEAN
INT32
INT_8
TINYINT
INT32
INT_16
SMALLINT
INT32
无
INT或INTEGER
INT64
无
BIGINT
FLOAT
无
FLOAT
DOUBLE
无
DOUBLE
FIXED_LEN_BYTE_ARRAY
BINARY
INT64
INT32
DECIMAL
DECIMAL
BINARY
UTF-8
VARCHAR
STRING
JSON(如果已知Parquet该列内容为JSON格式)
INT32
DATE
DATE
INT64
TIMESTAMP_MILLIS
TIMESTAMP或DATETIME
INT96
无
TIMESTAMP或DATETIME
重要Parquet格式外表暂不支持
STRUCT类型,会导致建表失败。ORC文件与AnalyticDB MySQL版3.0的数据类型映射关系如下表。
ORC文件中的数据类型
AnalyticDB MySQL版3.0中的数据类型
BOOLEAN
BOOLEAN
BYTE
TINYINT
SHORT
SMALLINT
INT
INT或INTEGER
LONG
BIGINT
DECIMAL
DECIMAL
FLOAT
FLOAT
DOUBLE
DOUBLE
BINARY
STRING
VARCHAR
VARCHAR
STRING
JSON(如果已知ORC该列内容为JSON格式)
TIMESTAMP
TIMESTAMP或DATETIME
DATE
DATE
重要ORC格式外表暂不支持
LIST、STRUCT和UNION等复合类型,会导致建表失败。ORC格式外表的列使用MAP类型可以建表,但ORC的查询会失败。
带分区的数据文件创建OSS外表
如果OSS数据源是包含分区的,会在OSS上形成一个分层目录,类似如下内容:
parquet_partition_classic/
├── p1=2020-01-01
│ ├── p2=4
│ │ ├── p3=SHANGHAI
│ │ │ ├── 000000_0
│ │ │ └── 000000_1
│ │ └── p3=SHENZHEN
│ │ └── 000000_0
│ └── p2=6
│ └── p3=SHENZHEN
│ └── 000000_0
├── p1=2020-01-02
│ └── p2=8
│ ├── p3=SHANGHAI
│ │ └── 000000_0
│ └── p3=SHENZHEN
│ └── 000000_0
└── p1=2020-01-03
└── p2=6
├── p2=HANGZHOU
└── p3=SHENZHEN
└── 000000_0上述数据中p1为第1级分区,p2为第2级分区,p3为第3级分区。对应这种数据源,一般都希望以分区的模式进行查询,那么就需要在创建OSS外表时指明分区列。以Parquet格式为例,创建带有分区的OSS外表的语句如下:
CREATE TABLE IF NOT EXISTS oss_parquet_partition_table
(
uid varchar,
other varchar,
p1 date,
p2 int,
p3 varchar
)
ENGINE='OSS'
TABLE_PROPERTIES='{
"endpoint":"oss-cn-hangzhou-internal.aliyuncs.com",
"url":"oss://<bucket-name>/adb/oss_parquet_data_dir",
"accessid":"LTAIF****5FsE",
"accesskey":"Ccw****iWjv",
"format":"parquet",
"partition_column":"p1, p2, p3"
}';TABLE_PROPERTIES中的partition_column属性必须声明分区列(本例中的p1、p2、p3)且partition_column属性里必须严格按照第1级、第2级、第3级的顺序声明(本例中p1为第1级分区,p2为第2级分区,p3为第3级分区)。列定义中必须定义分区列(本例中的p1、p2、p3)及类型,且分区列需要置于列定义的末尾。
列定义中分区列的先后顺序需要与partition_column中分区列的顺序保持一致。
可以作为分区列的数据类型有:
BOOLEAN、TINYINT、SMALLINT、INT、INTEGER、BIGINT、FLOAT、DOUBLE、DECIMAL、VARCHAR、STRING、DATE、TIMESTAMP。查询时分区列和其它数据列的表现和用法没有区别。
不指定format时,默认格式为CSV。
- 本页导读 (1)