利用DataWorks将数据迁移到TSDB
本文介绍通过DataWorks的数据集成功能,实现OpenTSDB到TSDB的数据迁移。
背景
DataWorks是阿里云重要的PaaS平台产品,提供数据集成、数据开发、数据服务、数据分析、数据治理等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。本文档介绍的数据迁移主要涉及数据开发部分。不熟悉DataWorks的用户可以参阅DataWorks的产品文档,做进一步地了解。目前,DataWorks 支持TSDB、OpenTSDB、Prometheus、InfluxDB和MySQL等多种数据源到TSDB的数据迁移。
Quick Start
步骤一:入口
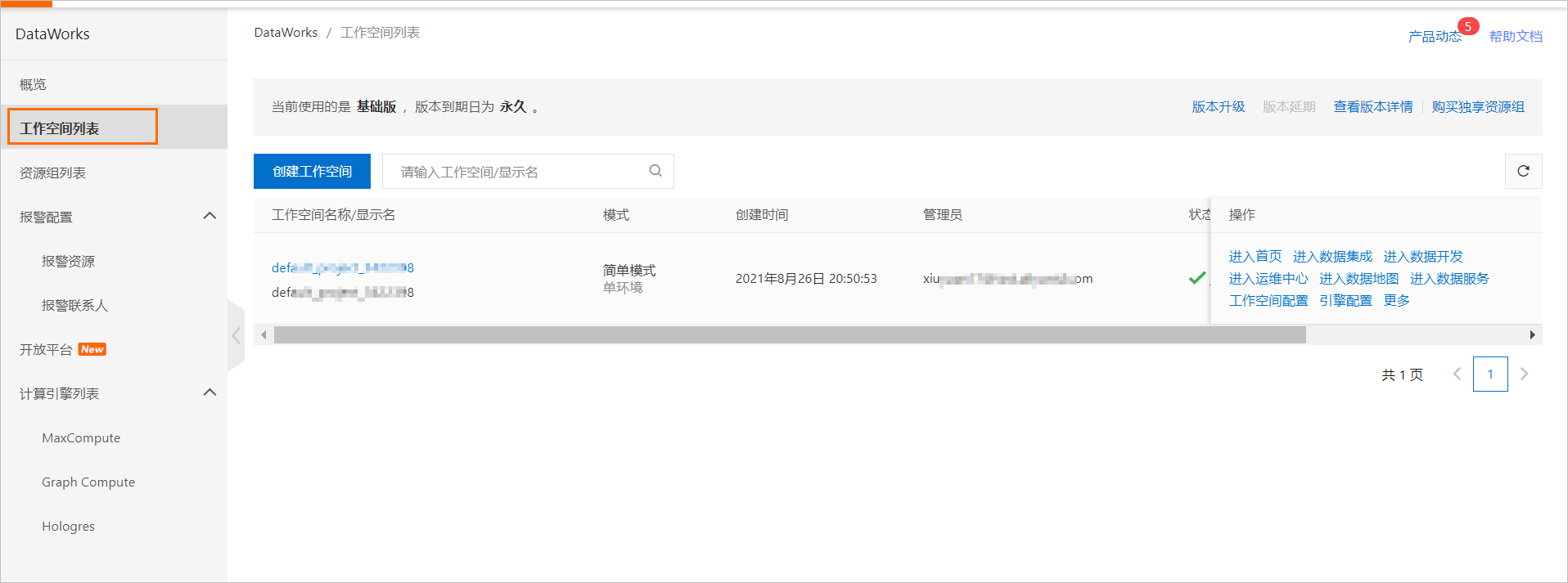
首先,登录DataWorks控制台。如果您尚未在控制台创建工作空间,需要先创建一个工作空间。创建完成之后,便可以在管理控制台看到工作空间列表。实际效果如图 1 所示:
步骤二:在”数据开发”中创建”同步节点”
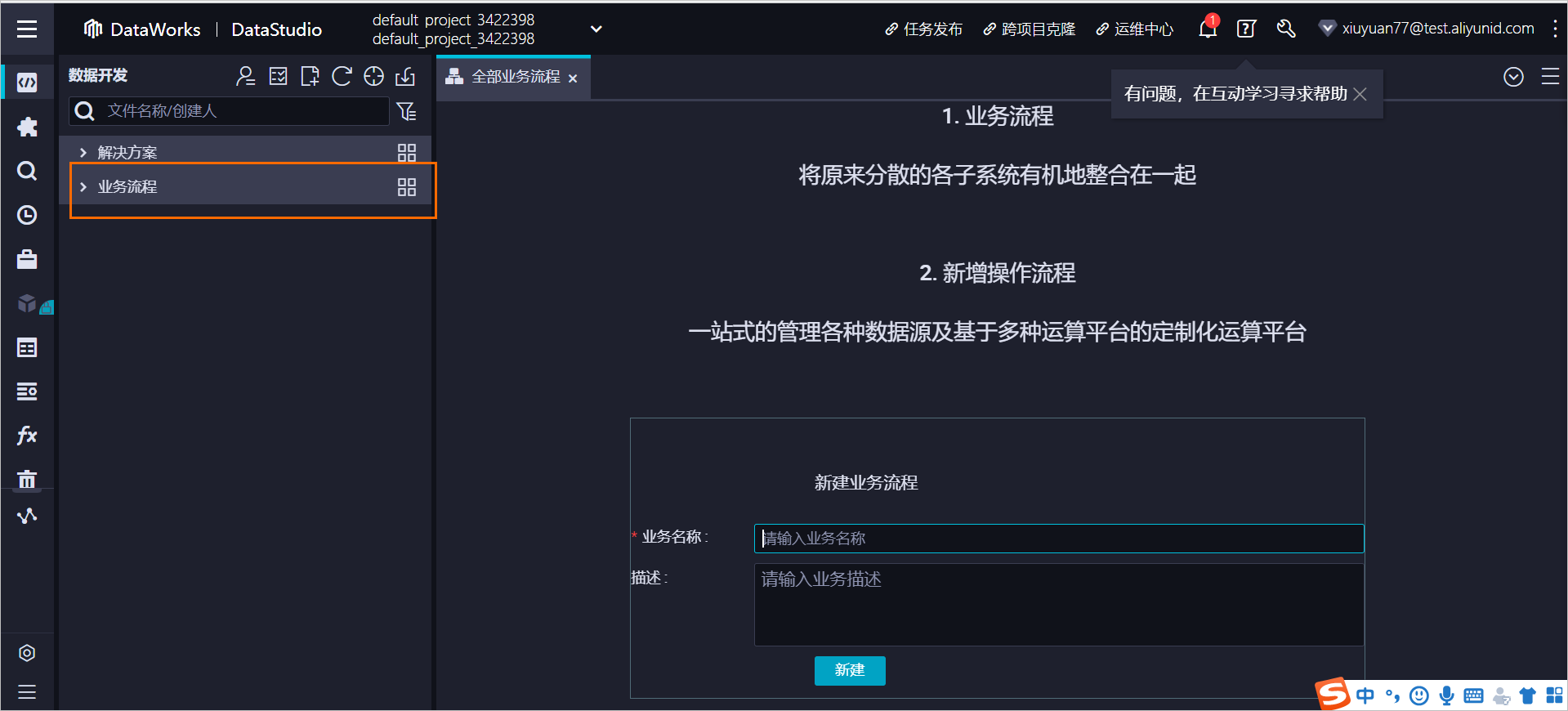
单击业务流程后面图标,在编辑区域输入业务名称,例如:migration_from_opentsdb_to_tsdb。实际效果如图 2 所示:
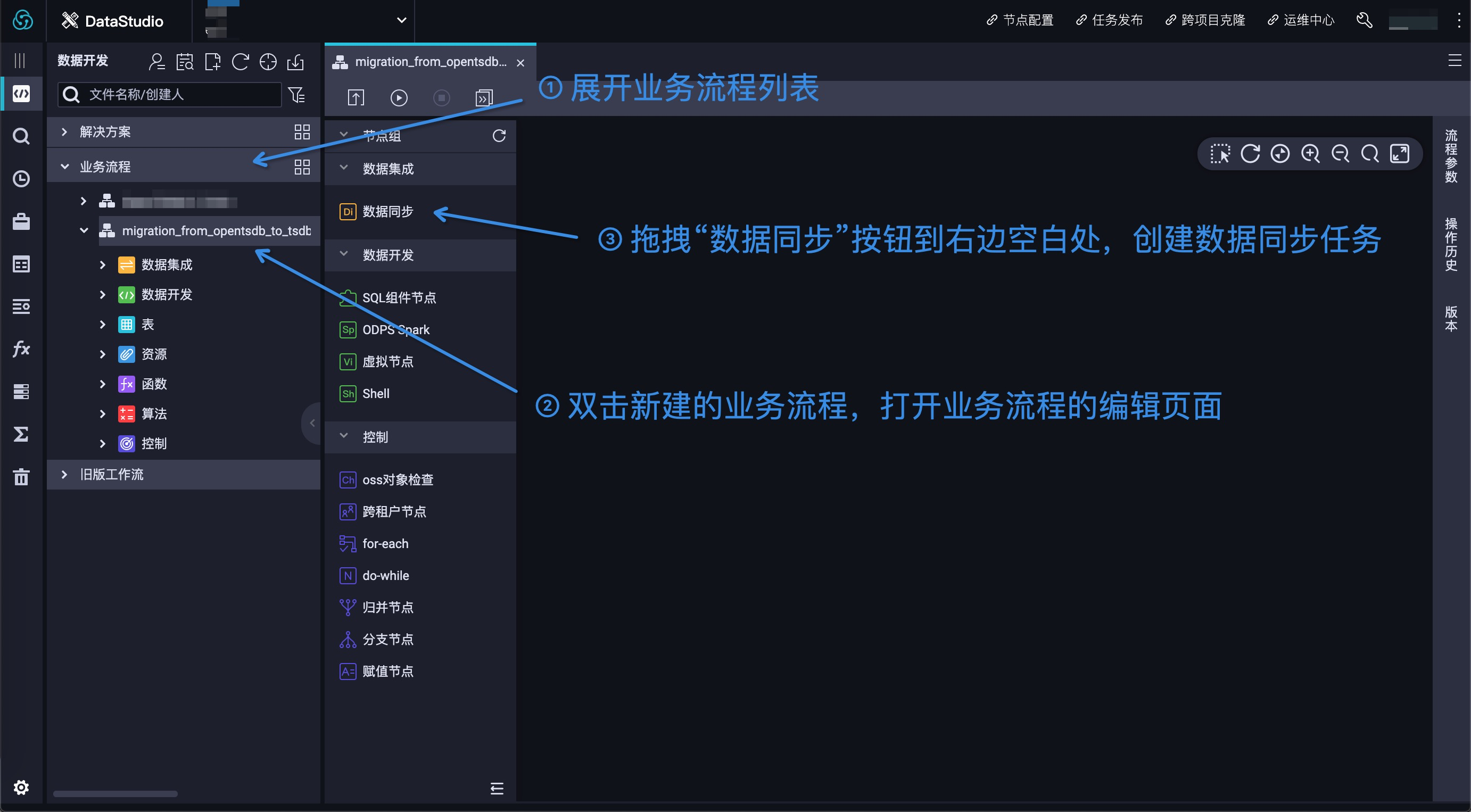
按照图 4 中的三个步骤,完成数据同步任务的创建:
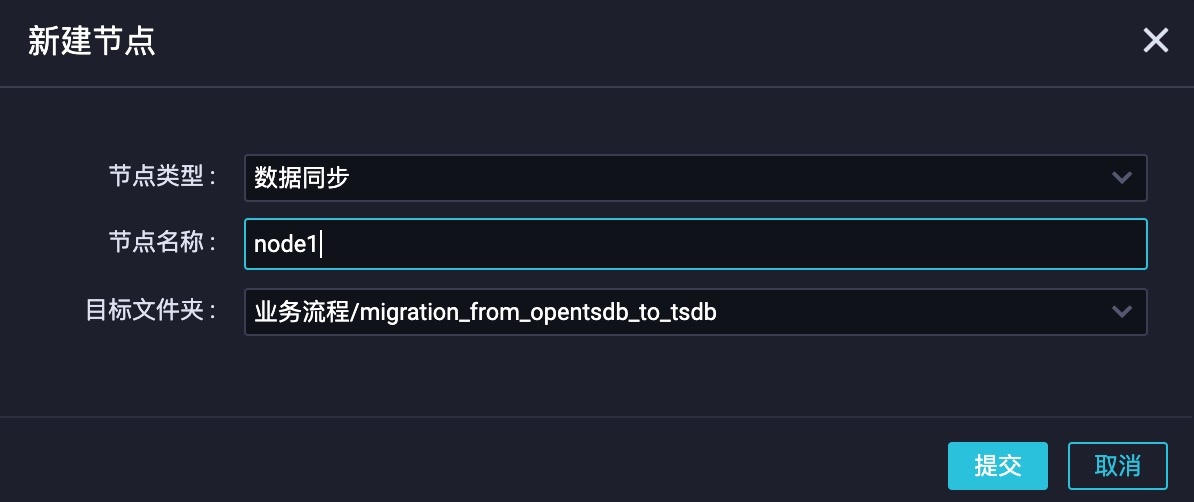
在弹窗中填入数据同步任务名(例如:node1)。实际效果如图 5 所示:
数据同步任务创建成功之后,可以在右边空白处看到 node1 节点。通过双击 node1 按钮,可以进入到数据同步任务的配置页面。实际效果如图 6 所示:
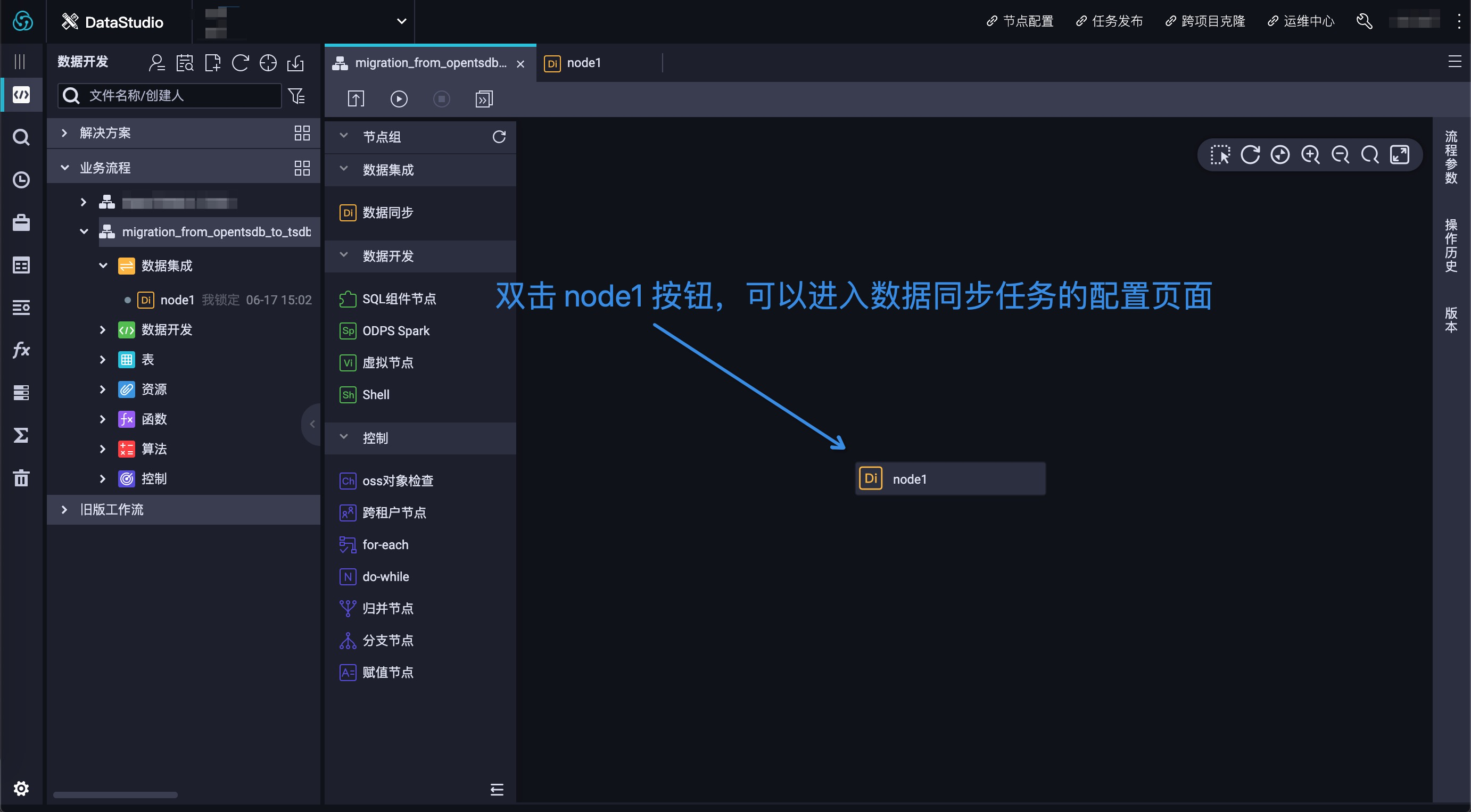
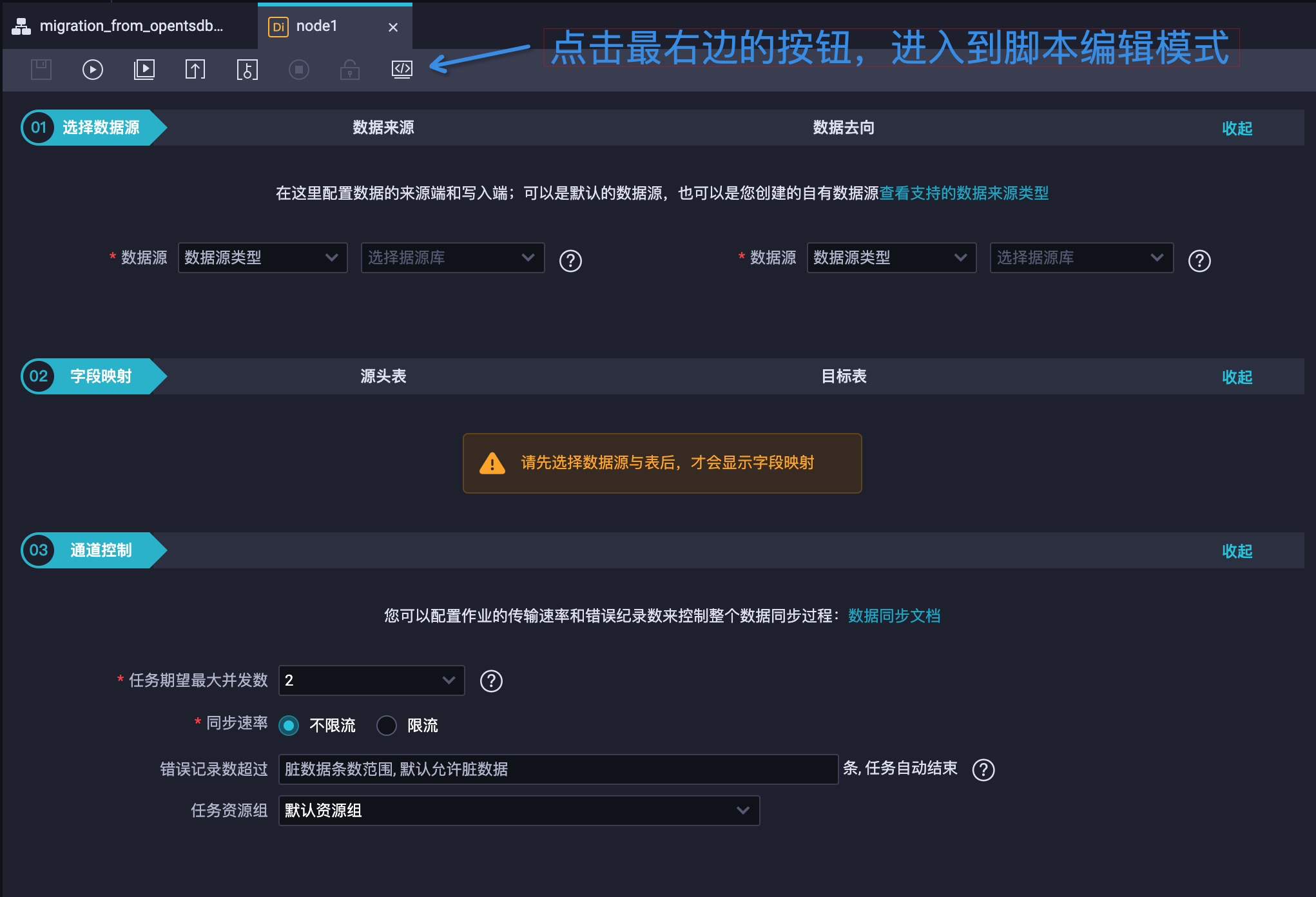
数据同步任务 node1 的默认编辑模式是”向导模式”,我们可以通过点击最右边的按钮,直接进入到脚本编辑模式。实际效果如图 7 所示:
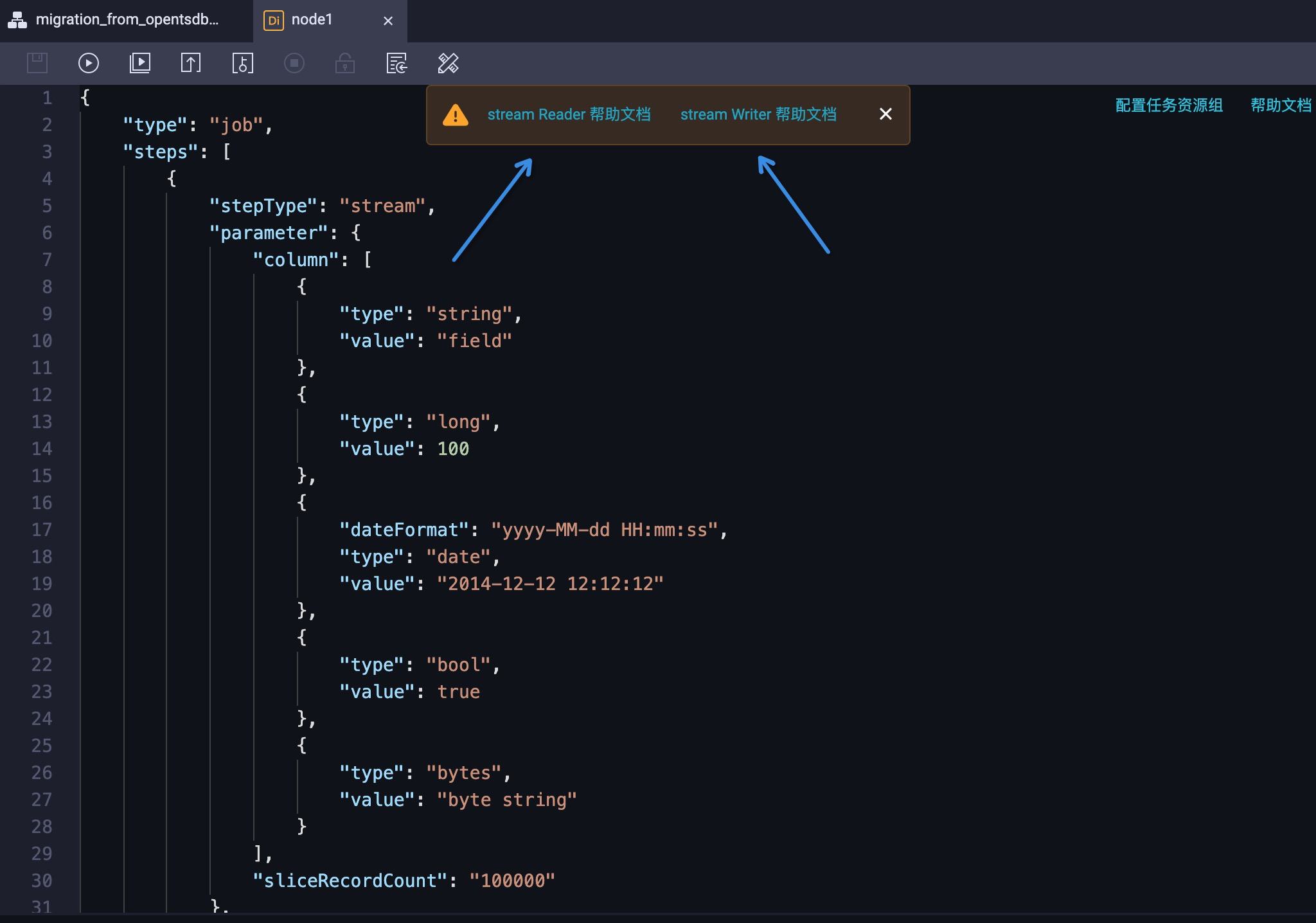
默认的同步任务是 Stream Reader 到 Stream Writer。大致流程是 Stream Reader 作为数据源,创建随机的字符串,而 Stream Writer 作为目标源,接受这些生成的字符串,并打印。更多相关的信息详见页面上方的帮助文档。具体效果如图 8 所示:
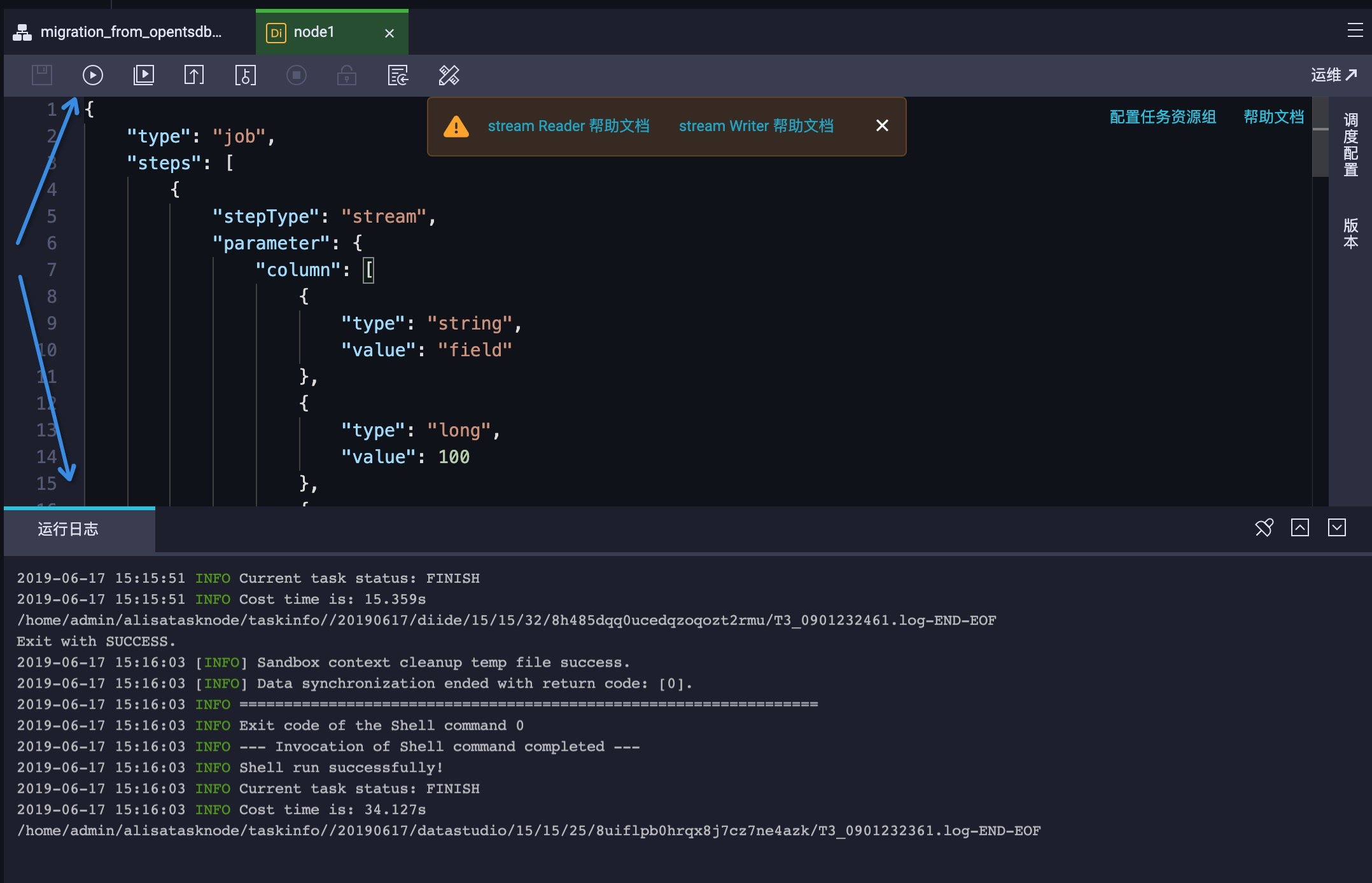
因为 Stream Reader 和 Stream Writer 同步任务不需要依赖任何外部资源,所以可以直接点击左上角的执行按钮,直观地查看任务的执行过程。实际效果如图 9 所示:
步骤三:修改配置
现在,我们将默认的同步任务,修改为 OpenTSDB 到 TSDB 的同步任务。
首先,我们通过点击  按钮,开始导入配置模板。实际效果如图 10 所示:
按钮,开始导入配置模板。实际效果如图 10 所示:
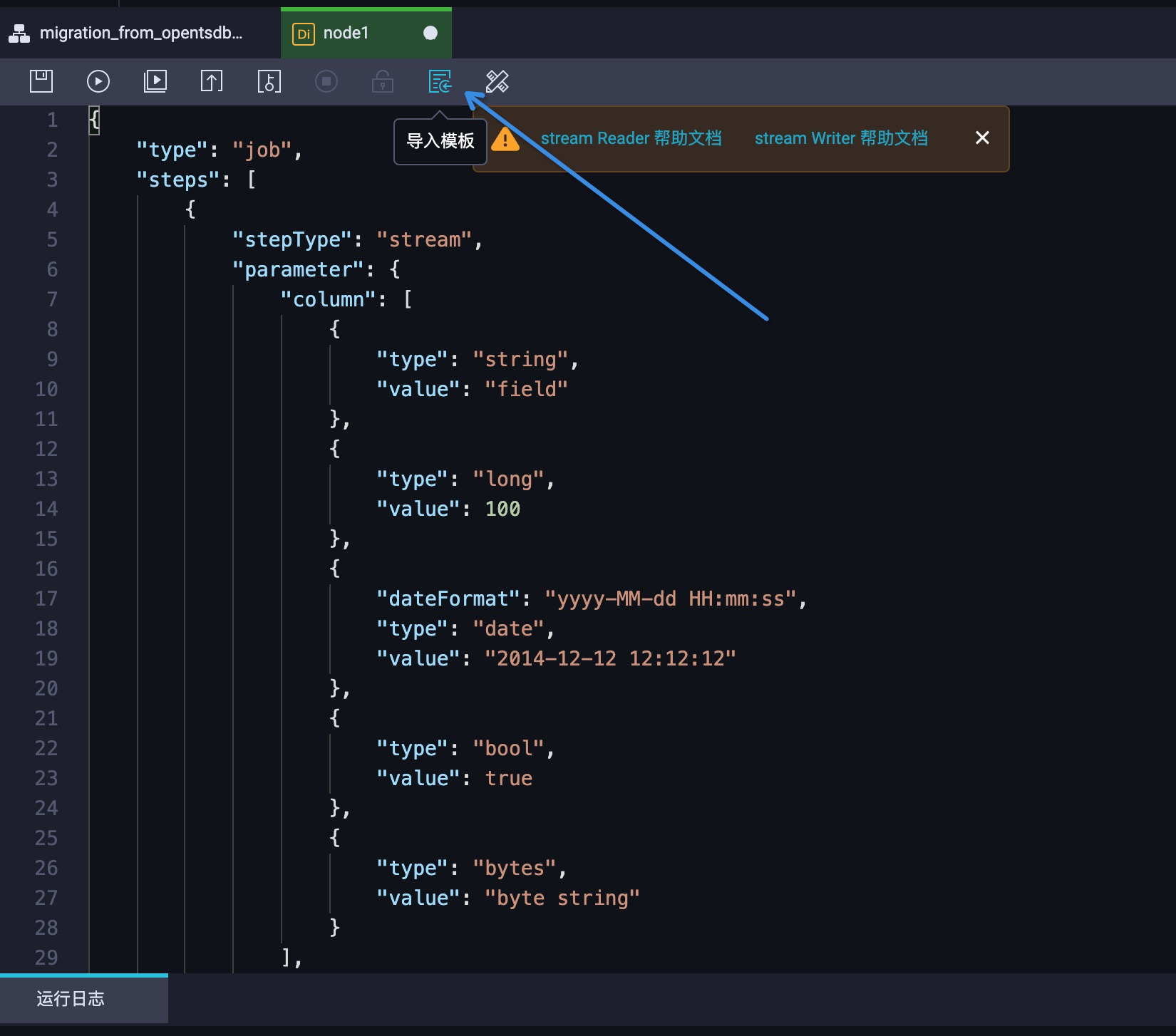
在弹窗中配置来源类型为 OpenTSDB,目标类型为 TSDB。实际效果如图 11 所示:
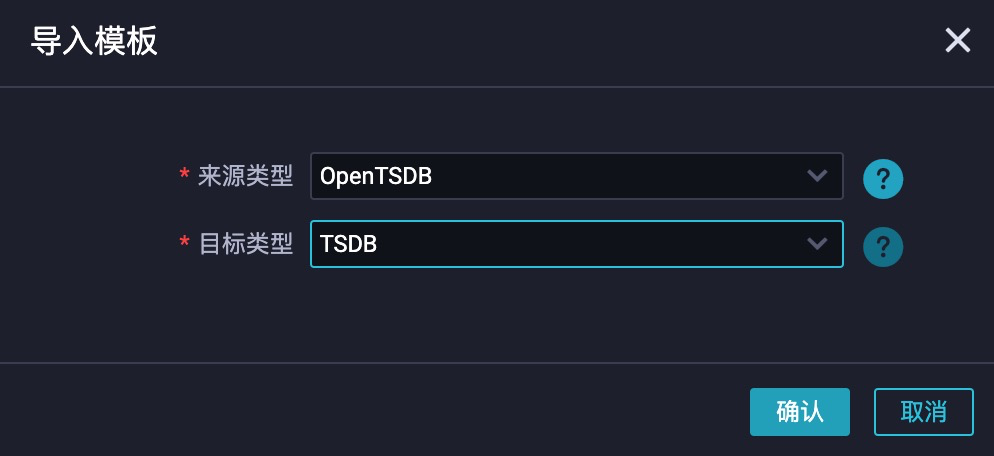
点击确认之后,可以看到 stepType 已经调整为 opentsdb 和 tsdb,而整个配置都已经自动调整为对应的配置项。并且帮助文档已经调整为DRDS Reader和TSDB Writer。实际效果如图 12 所示:
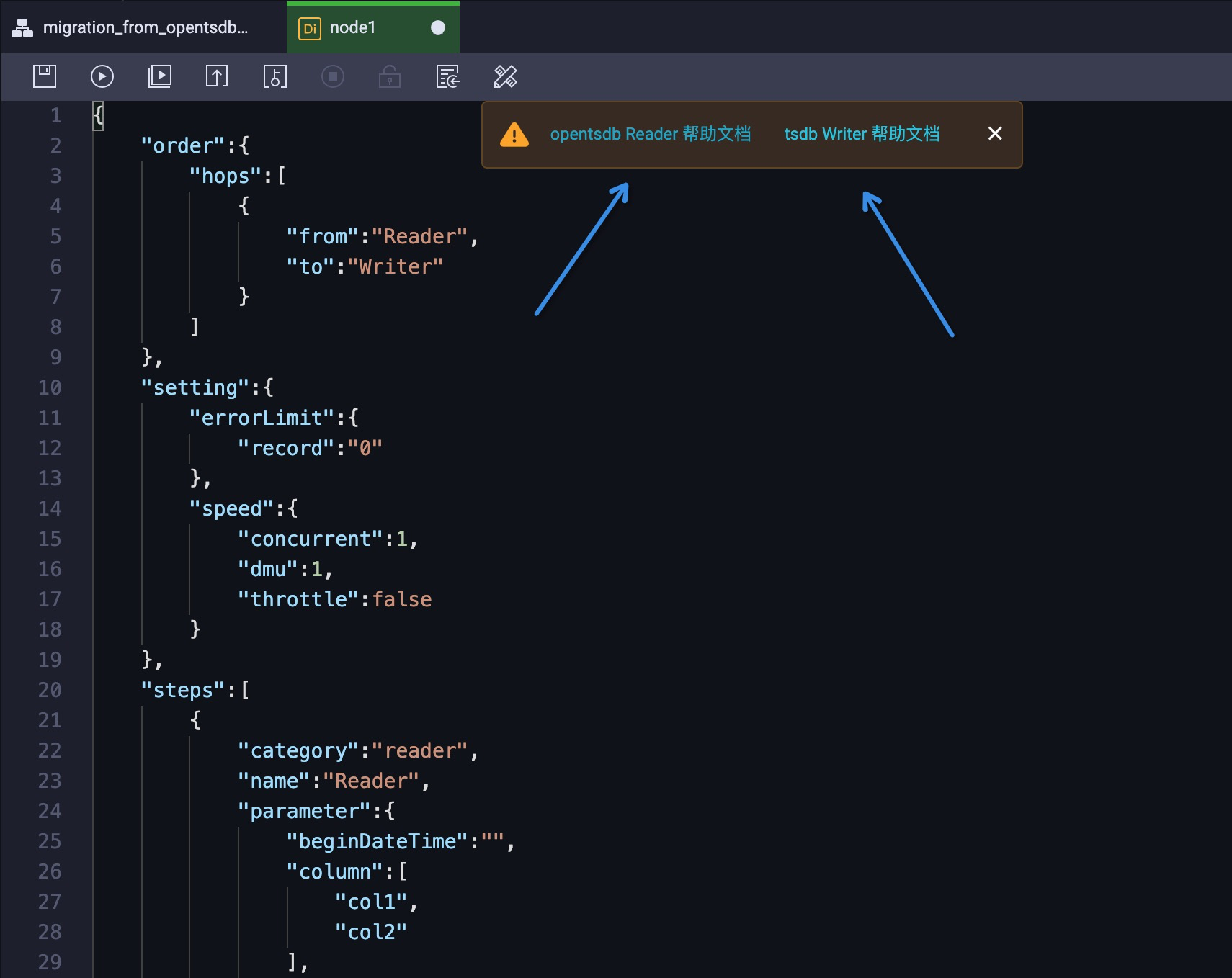
此时,按照配置文档进行配置的调整。其中必填的参数只有 5 个,包括 OpenTSDB 的地址(endpoint)、需要同步的 metric(column)和同步的时间范围(beginDateTime & endDateTime),以及 TSDB 的地址(endpoint)。例如:
{
"type":"job",
"steps":[
{
"stepType":"opentsdb",
"parameter":{
"endpoint":"http://host:4242",
"column":[
"m"
],
"beginDateTime":"20190101000000",
"endDateTime":"20190101030000"
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"tsdb",
"parameter":{
"endpoint":"http://host:8242"
},
"name":"Writer",
"category":"writer"
}
],
"version":"2.0",
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
},
"setting":{
"errorLimit":{
"record":"0"
},
"speed":{
"throttle":false,
"concurrent":1,
"dmu":1
}
}
}步骤四:修改白名单
使用 DataWorks 默认的资源组需要将 Region 对应的网段,增加到白名单中。以 OpenTSDB 到 TSDB 的数据迁移为例,需要给 OpenTSDB 和 TSDB 分别配置白名单。
参考《DataWorks V2.0 > 使用指南 > 数据集成 > 常见配置 > 添加白名单》文档,依据 DataWorks 工作区所在的 Region,找到需要配置的白名单网段。这里我们以华东 2 为例:

图 13:不同的 Region 对应不同的 DataWorks 白名单 针对 ECS 上自建的 OpenTSDB 实例,请参考《ECS安全组配置案例》和《VPC 常见问题》文档,将对应的网段配置到所有 OpenTSDB 实例所在的 ECS 的白名单列表中(包含底层存储 HBase 节点和引擎 TSD 节点)。
最后,参考《时序数据库 TSDB 版 > 快速入门 > 设置网络白名单》文档,将对应的网段配置到云上TSDB 实例的白名单列表中即可。
步骤五:数据同步
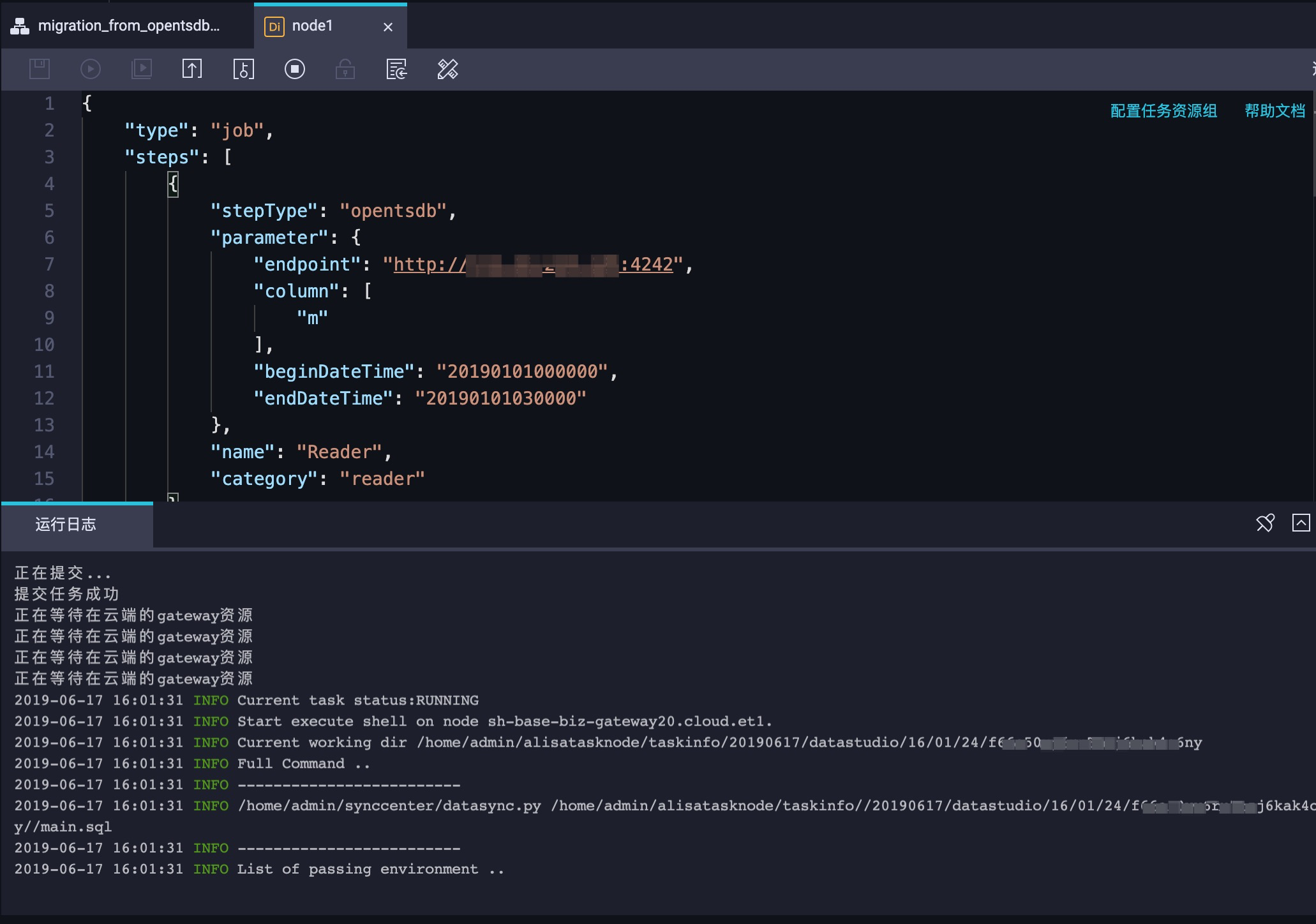
点击运行按钮,即可启动数据同步任务。实际效果如图 14 所示:
步骤六:独享资源组
默认使用 DataWorks 的公共资源组,可能会存在资源抢占的情况,所以并不会保证数据迁移任务的高性能。如果您对数据迁移性能要求很高,建议配置独享资源组。
- 本页导读 (1)