PyODPS为MaxCompute的Python版SDK,支持在DataWorks中开发运行PyODPS任务。本文为您介绍在DataWorks上使用PyODPS的使用限制、主要流程和部分简单应用示例。
使用限制
使用方式限制
如果您发现有Got killed报错,即表明内存使用超限,进程被中止。请避免在PyODPS节点中直接下载数据并在DataWorks中处理数据,建议将数据处理任务提交到MaxCompute进行分布式执行处理,两种方式的对比详情请参见注意事项:请勿下载全量数据到本地并运行PyODPS。
包支持限制
DataWorks的PyODPS节点缺少matplotlib等包,如下功能可能受限:
DataFrame的plot函数。
DataFrame自定义函数需要提交到MaxCompute执行。由于Python沙箱限制,第三方库只支持所有的纯粹Python库以及NumPy,因此不能直接使用Pandas。
DataWorks中执行的非自定义函数代码可以使用平台预装的NumPy和Pandas。不支持其他带有二进制代码的第三方包。
DataWorks的PyODPS节点不支持Python的atexit包,请使用try-finally结构实现相关功能。
读取数据记录数限制
DataWorks的PyODPS节点中,options.tunnel.use_instance_tunnel默认设置为False,即默认情况下,最多读取一万条数据记录。如果需要读取更多数据记录,需全局开启instance tunnel,即需要手动将options.tunnel.use_instance_tunnel设置为True。
主要流程
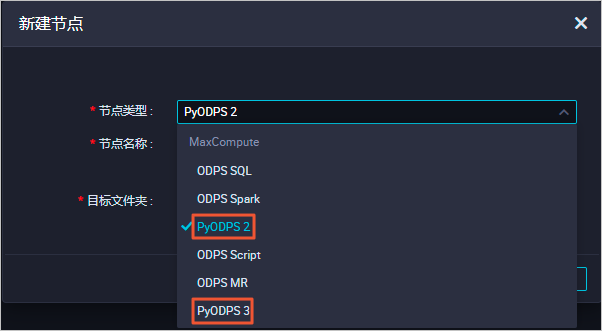
创建PyODPS节点。
您可以进入DataWorks的数据开发页面创建PyODPS节点。PyODPS节点分为PyODPS 2和PyODPS 3两种:
PyODPS 2底层Python语言版本为Python 2。
PyODPS 3底层Python语言版本为Python 3。
您可根据实际使用的Python语言版本创建PyODPS节点,创建PyODPS节点的详细操作步骤请参见开发PyODPS 2任务和开发PyODPS 3任务。
开发PyODPS任务代码。
创建完成后,您可参考下文内容进行简单示例的操作学习,了解PyODPS的主要能力维度。
更多PyODPS的使用指导请参见基本操作概述、DataFrame概述。您也可以参考示例文档:使用PyODPS节点进行结巴中文分词,进行一个端到端的简单操作。
进行调度配置,完成后保存、提交、发布节点,后续即可周期性运行任务。
ODPS入口
DataWorks的PyODPS节点中,将会包含一个全局变量odps或者o,即为ODPS入口。您不需要手动定义ODPS入口。 命令示例如下。
#查看表pyodps_iris是否存在
print(o.exist_table('pyodps_iris'))返回True,表示表存在。
执行SQL
通用能力
在PyODPS节点中运行SQL命令:例如使用execute_sql()/run_sql()来执行SQL命令,当前主要支持运行DDL、DML类型的SQL命令。
说明可以执行的SQL语句并非都可以通过入口对象的
execute_sql()和run_sql()方法执行。在调用非DDL或非DML语句时,请使用其他方法。例如,调用GRANT或REVOKE语句时,请使用run_security_query方法;调用API命令时,请使用run_xflow或execute_xflow方法。在PyODPS节点中读取SQL运行结果:例如使用open_reader()来读取SQL命令运行结果。
更多PyODPS节点的SQL相关操作详情请参见SQL。
注意事项:数据记录数量限制
DataWorks上默认没有开启instance tunnel,即instance.open_reader默认使用Result接口(存在limit限制,最多读取一万条数据记录)。如果您需要迭代获取全部数据,则需要开启instance tunnel并关闭limit限制。
全局关闭
limit限制您可以通过下列语句在全局范围内打开Instance Tunnel并关闭
limit限制。options.tunnel.use_instance_tunnel = True options.tunnel.limit_instance_tunnel = False # 关闭limit限制,读取全部数据。 with instance.open_reader() as reader: # 通过Instance Tunnel可读取全部数据。 # 您可以通过reader.count获取记录数。仅本次运行关闭
limit限制您也可以通过在open_reader上添加
tunnel=True,实现仅对本次open_reader开启instance tunnel。同时,您还可以添加limit=False,实现仅对本次关闭limit限制。重要若您未开启Instance Tunnel,可能导致获取数据格式错误,解决方法请参见Python SDK常见问题。
with instance.open_reader(tunnel=True, limit=False) as reader: # 本次open_reader使用Instance Tunnel接口,且能读取全部数据。
DataFrame
执行
打印详细信息
在DataWorks上默认打开
options.verbose选项,即默认情况下,DataWorks的PyODPS节点运行过程会打印Logview等详细过程。您可以手动设置此选项,指定运行过程是否会打印Logview等详细过程。
更多DataFrame的操作示例请参见DataFrame概述。
获取调度参数
使用DataWorks的PyODPS节点开发任务代码时,您也可以使用调度参数,例如,需要通过调度参数获取任务运行的业务日期等场景。PyODPS节点与DataWorks中的SQL节点在调度参数的定义参数操作方面一致,但是在代码中的引用方式不同。
SQL节点会在代码中直接使用 ${param_name}这样的字符串。
为了避免影响代码,PyODPS节点在执行代码前,在全局变量中增加了一个名为
args的dict,代码中使用args[param_name]的方式获取调度参数取值,而非在代码中替换 ${param_name}。
例如,在中设置了调度参数ds=${yyyymmdd},则可以通过以下方式在代码中获取该参数。
获取参数
ds的取值。print('ds=' + args['ds']) #返回ds的时间,如ds=20161116获取名为
ds=${yyyymmdd}的分区的表数据。o.get_table('table_name').get_partition('ds=' + args['ds']) #获取ds分区下表table_name的数据
更多调度参数详情可参见配置并使用调度参数。
设置运行参数hints
运行任务时如果需要设置运行时参数,可以通过设置hints参数来实现,参数类型是dict。
o.execute_sql('select * from pyodps_iris', hints={'odps.sql.mapper.split.size': 16})您也可以对全局设置sql.setting,设置后后续每次运行时都会添加相关的运行时参数。
from odps import options
options.sql.settings = {'odps.sql.mapper.split.size': 16}
o.execute_sql('select * from pyodps_iris') #会根据全局配置添加hints使用三方包
DataWorks节点预装了以下三方包,版本列表如下:
包名 | Python 2节点版本 | Python 3节点版本 |
requests | 2.11.1 | 2.26.0 |
numpy | 1.16.6 | 1.18.1 |
pandas | 0.24.2 | 1.0.5 |
scipy | 0.19.0 | 1.3.0 |
scikit_learn | 0.18.1 | 0.22.1 |
pyarrow | 0.16.0 | 2.0.0 |
lz4 | 2.1.4 | 3.1.10 |
zstandard | 0.14.1 | 0.17.0 |
如果您需要使用上面列表中不存在的包,DataWorks节点提供了load_resource_package方法,支持从MaxCompute资源下载三方包。使用pyodps-pack打包后,可以直接使用load_resource_package方法加载三方包,之后就可以导入包中的内容。关于pyodps-pack的使用方法请参见PyODPS制作第三方包和PyODPS使用第三方包。
如果为Python 2节点打包,请在打包时为pyodps-pack增加--dwpy27参数。
示例:
使用以下命令打包ipaddress。
pyodps-pack -o ipaddress-bundle.tar.gz ipaddress上传并提交
ipaddress-bundle.tar.gz为资源后,可以在PyODPS 3节点中按照下面的方法使用ipaddress包。load_resource_package("ipaddress-bundle.tar.gz") import ipaddress
DataWorks限制下载的包总大小为100 MB。如果您需要跳过预装包的打包,可以在打包时使用pyodps-pack提供的--exclude参数。例如:下面打包方法排除了DataWorks环境中存在的numpy包和pandas包。
pyodps-pack -o bundle.tar.gz --exclude numpy --exclude pandas <your_package>使用其他账号
某些场景下您可能希望使用其他账号(而非平台提供的账号)访问MaxCompute。此时,可以使用ODPS入口对象的as_account方法创建一个使用新账号的入口对象,该对象与系统默认提供的o实例彼此独立。
as_account方法从PyODPS 0.11.3版本开始支持。如果您的DataWorks未部署该版本,则无法使用as_account方法。
主要流程
为其他用户授权项目相关权限,详情请参见附录:为其他用户授权。
在PyODPS节点中使用
as_account方法切换账号,创建新的入口对象。import os # 确保 ALIBABA_CLOUD_ACCESS_KEY_ID 环境变量设置为 Access Key ID, # ALIBABA_CLOUD_ACCESS_KEY_SECRET 环境变量设置为 Access Key Secret, # 不建议直接使用 Access Key ID / Access Key Secret 字符串 new_odps = o.as_account( os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'), os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET') )检查账号切换结果。
查询当前用户信息:在要执行的代码中增加以下语句,如果运行结果中打印出的用户信息为您所传入的其他用户的UID,则表示您是使用其他账号访问的MaxCompute。
print(new_odps.get_project().current_user)说明new_odps:表示上述的新账号的入口对象。
使用示例
创建表并导入数据。
下载鸢尾花数据集iris.data,重命名为iris.csv。
创建表pyodps_iris并上传数据集iris.csv。操作方法请参见建表并上传数据。
建表语句如下。
CREATE TABLE if not exists pyodps_iris ( sepallength DOUBLE comment '片长度(cm)', sepalwidth DOUBLE comment '片宽度(cm)', petallength DOUBLE comment '瓣长度(cm)', petalwidth DOUBLE comment '瓣宽度(cm)', name STRING comment '种类' );
创建ODPS SQL节点完成授权。详情请参见附录:为其他用户授权。
创建PyODPS节点完成切换用户操作,代码示例如下。详情请参见开发PyODPS 3任务。
from odps import ODPS import os import sys # 确保 ALIBABA_CLOUD_ACCESS_KEY_ID 环境变量设置为用户 Access Key ID, # ALIBABA_CLOUD_ACCESS_KEY_SECRET 环境变量设置为用户 Access Key Secret, # 不建议直接使用 Access Key ID / Access Key Secret 字符串 os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'] = '<accesskey id>' os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'] = '<accesskey secret>' od = o.as_account(os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'), os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET') ) iris = DataFrame(od.get_table('pyodps_iris')) #使用条件方式输出。 with od.execute_sql('select * from pyodps_iris WHERE sepallength > 5 ').open_reader() as reader4: print(reader4.raw) for record in reader4: print(record["sepallength"],record["sepalwidth"],record["petallength"],record["petalwidth"],record["name"]) #输出当前用户的UID print(od.get_project().current_user)运行并查看结果。
Executing user script with PyODPS 0.11.4.post0 "sepallength","sepalwidth","petallength","petalwidth","name" 5.4,3.9,1.7,0.4,"Iris-setosa" 5.4,3.7,1.5,0.2,"Iris-setosa" 5.8,4.0,1.2,0.2,"Iris-setosa" 5.7,4.4,1.5,0.4,"Iris-setosa" 5.4,3.9,1.3,0.4,"Iris-setosa" 5.1,3.5,1.4,0.3,"Iris-setosa" 5.7,3.8,1.7,0.3,"Iris-setosa" 5.1,3.8,1.5,0.3,"Iris-setosa" 5.4,3.4,1.7,0.2,"Iris-setosa" 5.1,3.7,1.5,0.4,"Iris-setosa" 5.1,3.3,1.7,0.5,"Iris-setosa" 5.2,3.5,1.5,0.2,"Iris-setosa" 5.2,3.4,1.4,0.2,"Iris-setosa" 5.4,3.4,1.5,0.4,"Iris-setosa" 5.2,4.1,1.5,0.1,"Iris-setosa" 5.5,4.2,1.4,0.2,"Iris-setosa" 5.5,3.5,1.3,0.2,"Iris-setosa" 5.1,3.4,1.5,0.2,"Iris-setosa" 5.1,3.8,1.9,0.4,"Iris-setosa" 5.1,3.8,1.6,0.2,"Iris-setosa" 5.3,3.7,1.5,0.2,"Iris-setosa" 7.0,3.2,4.7,1.4,"Iris-versicolor" 6.4,3.2,4.5,1.5,"Iris-versicolor" 6.9,3.1,4.9,1.5,"Iris-versicolor" 5.5,2.3,4.0,1.3,"Iris-versicolor" 6.5,2.8,4.6,1.5,"Iris-versicolor" 5.7,2.8,4.5,1.3,"Iris-versicolor" 6.3,3.3,4.7,1.6,"Iris-versicolor" 6.6,2.9,4.6,1.3,"Iris-versicolor" 5.2,2.7,3.9,1.4,"Iris-versicolor" 5.9,3.0,4.2,1.5,"Iris-versicolor" 6.0,2.2,4.0,1.0,"Iris-versicolor" 6.1,2.9,4.7,1.4,"Iris-versicolor" 5.6,2.9,3.6,1.3,"Iris-versicolor" 6.7,3.1,4.4,1.4,"Iris-versicolor" 5.6,3.0,4.5,1.5,"Iris-versicolor" 5.8,2.7,4.1,1.0,"Iris-versicolor" 6.2,2.2,4.5,1.5,"Iris-versicolor" 5.6,2.5,3.9,1.1,"Iris-versicolor" 5.9,3.2,4.8,1.8,"Iris-versicolor" 6.1,2.8,4.0,1.3,"Iris-versicolor" 6.3,2.5,4.9,1.5,"Iris-versicolor" 6.1,2.8,4.7,1.2,"Iris-versicolor" 6.4,2.9,4.3,1.3,"Iris-versicolor" 6.6,3.0,4.4,1.4,"Iris-versicolor" 6.8,2.8,4.8,1.4,"Iris-versicolor" 6.7,3.0,5.0,1.7,"Iris-versicolor" 6.0,2.9,4.5,1.5,"Iris-versicolor" 5.7,2.6,3.5,1.0,"Iris-versicolor" 5.5,2.4,3.8,1.1,"Iris-versicolor" 5.5,2.4,3.7,1.0,"Iris-versicolor" 5.8,2.7,3.9,1.2,"Iris-versicolor" 6.0,2.7,5.1,1.6,"Iris-versicolor" 5.4,3.0,4.5,1.5,"Iris-versicolor" 6.0,3.4,4.5,1.6,"Iris-versicolor" 6.7,3.1,4.7,1.5,"Iris-versicolor" 6.3,2.3,4.4,1.3,"Iris-versicolor" 5.6,3.0,4.1,1.3,"Iris-versicolor" 5.5,2.5,4.0,1.3,"Iris-versicolor" 5.5,2.6,4.4,1.2,"Iris-versicolor" 6.1,3.0,4.6,1.4,"Iris-versicolor" 5.8,2.6,4.0,1.2,"Iris-versicolor" 5.6,2.7,4.2,1.3,"Iris-versicolor" 5.7,3.0,4.2,1.2,"Iris-versicolor" 5.7,2.9,4.2,1.3,"Iris-versicolor" 6.2,2.9,4.3,1.3,"Iris-versicolor" 5.1,2.5,3.0,1.1,"Iris-versicolor" 5.7,2.8,4.1,1.3,"Iris-versicolor" 6.3,3.3,6.0,2.5,"Iris-virginica" 5.8,2.7,5.1,1.9,"Iris-virginica" 7.1,3.0,5.9,2.1,"Iris-virginica" 6.3,2.9,5.6,1.8,"Iris-virginica" 6.5,3.0,5.8,2.2,"Iris-virginica" 7.6,3.0,6.6,2.1,"Iris-virginica" 7.3,2.9,6.3,1.8,"Iris-virginica" 6.7,2.5,5.8,1.8,"Iris-virginica" 7.2,3.6,6.1,2.5,"Iris-virginica" 6.5,3.2,5.1,2.0,"Iris-virginica" 6.4,2.7,5.3,1.9,"Iris-virginica" 6.8,3.0,5.5,2.1,"Iris-virginica" 5.7,2.5,5.0,2.0,"Iris-virginica" 5.8,2.8,5.1,2.4,"Iris-virginica" 6.4,3.2,5.3,2.3,"Iris-virginica" 6.5,3.0,5.5,1.8,"Iris-virginica" 7.7,3.8,6.7,2.2,"Iris-virginica" 7.7,2.6,6.9,2.3,"Iris-virginica" 6.0,2.2,5.0,1.5,"Iris-virginica" 6.9,3.2,5.7,2.3,"Iris-virginica" 5.6,2.8,4.9,2.0,"Iris-virginica" 7.7,2.8,6.7,2.0,"Iris-virginica" 6.3,2.7,4.9,1.8,"Iris-virginica" 6.7,3.3,5.7,2.1,"Iris-virginica" 7.2,3.2,6.0,1.8,"Iris-virginica" 6.2,2.8,4.8,1.8,"Iris-virginica" 6.1,3.0,4.9,1.8,"Iris-virginica" 6.4,2.8,5.6,2.1,"Iris-virginica" 7.2,3.0,5.8,1.6,"Iris-virginica" 7.4,2.8,6.1,1.9,"Iris-virginica" 7.9,3.8,6.4,2.0,"Iris-virginica" 6.4,2.8,5.6,2.2,"Iris-virginica" 6.3,2.8,5.1,1.5,"Iris-virginica" 6.1,2.6,5.6,1.4,"Iris-virginica" 7.7,3.0,6.1,2.3,"Iris-virginica" 6.3,3.4,5.6,2.4,"Iris-virginica" 6.4,3.1,5.5,1.8,"Iris-virginica" 6.0,3.0,4.8,1.8,"Iris-virginica" 6.9,3.1,5.4,2.1,"Iris-virginica" 6.7,3.1,5.6,2.4,"Iris-virginica" 6.9,3.1,5.1,2.3,"Iris-virginica" 5.8,2.7,5.1,1.9,"Iris-virginica" 6.8,3.2,5.9,2.3,"Iris-virginica" 6.7,3.3,5.7,2.5,"Iris-virginica" 6.7,3.0,5.2,2.3,"Iris-virginica" 6.3,2.5,5.0,1.9,"Iris-virginica" 6.5,3.0,5.2,2.0,"Iris-virginica" 6.2,3.4,5.4,2.3,"Iris-virginica" 5.9,3.0,5.1,1.8,"Iris-virginica" 5.4 3.9 1.7 0.4 Iris-setosa 5.4 3.7 1.5 0.2 Iris-setosa 5.8 4.0 1.2 0.2 Iris-setosa 5.7 4.4 1.5 0.4 Iris-setosa 5.4 3.9 1.3 0.4 Iris-setosa 5.1 3.5 1.4 0.3 Iris-setosa 5.7 3.8 1.7 0.3 Iris-setosa 5.1 3.8 1.5 0.3 Iris-setosa 5.4 3.4 1.7 0.2 Iris-setosa 5.1 3.7 1.5 0.4 Iris-setosa 5.1 3.3 1.7 0.5 Iris-setosa 5.2 3.5 1.5 0.2 Iris-setosa 5.2 3.4 1.4 0.2 Iris-setosa 5.4 3.4 1.5 0.4 Iris-setosa 5.2 4.1 1.5 0.1 Iris-setosa 5.5 4.2 1.4 0.2 Iris-setosa 5.5 3.5 1.3 0.2 Iris-setosa 5.1 3.4 1.5 0.2 Iris-setosa 5.1 3.8 1.9 0.4 Iris-setosa 5.1 3.8 1.6 0.2 Iris-setosa 5.3 3.7 1.5 0.2 Iris-setosa 7.0 3.2 4.7 1.4 Iris-versicolor 6.4 3.2 4.5 1.5 Iris-versicolor 6.9 3.1 4.9 1.5 Iris-versicolor 5.5 2.3 4.0 1.3 Iris-versicolor 6.5 2.8 4.6 1.5 Iris-versicolor 5.7 2.8 4.5 1.3 Iris-versicolor 6.3 3.3 4.7 1.6 Iris-versicolor 6.6 2.9 4.6 1.3 Iris-versicolor 5.2 2.7 3.9 1.4 Iris-versicolor 5.9 3.0 4.2 1.5 Iris-versicolor 6.0 2.2 4.0 1.0 Iris-versicolor 6.1 2.9 4.7 1.4 Iris-versicolor 5.6 2.9 3.6 1.3 Iris-versicolor 6.7 3.1 4.4 1.4 Iris-versicolor 5.6 3.0 4.5 1.5 Iris-versicolor 5.8 2.7 4.1 1.0 Iris-versicolor 6.2 2.2 4.5 1.5 Iris-versicolor 5.6 2.5 3.9 1.1 Iris-versicolor 5.9 3.2 4.8 1.8 Iris-versicolor 6.1 2.8 4.0 1.3 Iris-versicolor 6.3 2.5 4.9 1.5 Iris-versicolor 6.1 2.8 4.7 1.2 Iris-versicolor 6.4 2.9 4.3 1.3 Iris-versicolor 6.6 3.0 4.4 1.4 Iris-versicolor 6.8 2.8 4.8 1.4 Iris-versicolor 6.7 3.0 5.0 1.7 Iris-versicolor 6.0 2.9 4.5 1.5 Iris-versicolor 5.7 2.6 3.5 1.0 Iris-versicolor 5.5 2.4 3.8 1.1 Iris-versicolor 5.5 2.4 3.7 1.0 Iris-versicolor 5.8 2.7 3.9 1.2 Iris-versicolor 6.0 2.7 5.1 1.6 Iris-versicolor 5.4 3.0 4.5 1.5 Iris-versicolor 6.0 3.4 4.5 1.6 Iris-versicolor 6.7 3.1 4.7 1.5 Iris-versicolor 6.3 2.3 4.4 1.3 Iris-versicolor 5.6 3.0 4.1 1.3 Iris-versicolor 5.5 2.5 4.0 1.3 Iris-versicolor 5.5 2.6 4.4 1.2 Iris-versicolor 6.1 3.0 4.6 1.4 Iris-versicolor 5.8 2.6 4.0 1.2 Iris-versicolor 5.6 2.7 4.2 1.3 Iris-versicolor 5.7 3.0 4.2 1.2 Iris-versicolor 5.7 2.9 4.2 1.3 Iris-versicolor 6.2 2.9 4.3 1.3 Iris-versicolor 5.1 2.5 3.0 1.1 Iris-versicolor 5.7 2.8 4.1 1.3 Iris-versicolor 6.3 3.3 6.0 2.5 Iris-virginica 5.8 2.7 5.1 1.9 Iris-virginica 7.1 3.0 5.9 2.1 Iris-virginica 6.3 2.9 5.6 1.8 Iris-virginica 6.5 3.0 5.8 2.2 Iris-virginica 7.6 3.0 6.6 2.1 Iris-virginica 7.3 2.9 6.3 1.8 Iris-virginica 6.7 2.5 5.8 1.8 Iris-virginica 7.2 3.6 6.1 2.5 Iris-virginica 6.5 3.2 5.1 2.0 Iris-virginica 6.4 2.7 5.3 1.9 Iris-virginica 6.8 3.0 5.5 2.1 Iris-virginica 5.7 2.5 5.0 2.0 Iris-virginica 5.8 2.8 5.1 2.4 Iris-virginica 6.4 3.2 5.3 2.3 Iris-virginica 6.5 3.0 5.5 1.8 Iris-virginica 7.7 3.8 6.7 2.2 Iris-virginica 7.7 2.6 6.9 2.3 Iris-virginica 6.0 2.2 5.0 1.5 Iris-virginica 6.9 3.2 5.7 2.3 Iris-virginica 5.6 2.8 4.9 2.0 Iris-virginica 7.7 2.8 6.7 2.0 Iris-virginica 6.3 2.7 4.9 1.8 Iris-virginica 6.7 3.3 5.7 2.1 Iris-virginica 7.2 3.2 6.0 1.8 Iris-virginica 6.2 2.8 4.8 1.8 Iris-virginica 6.1 3.0 4.9 1.8 Iris-virginica 6.4 2.8 5.6 2.1 Iris-virginica 7.2 3.0 5.8 1.6 Iris-virginica 7.4 2.8 6.1 1.9 Iris-virginica 7.9 3.8 6.4 2.0 Iris-virginica 6.4 2.8 5.6 2.2 Iris-virginica 6.3 2.8 5.1 1.5 Iris-virginica 6.1 2.6 5.6 1.4 Iris-virginica 7.7 3.0 6.1 2.3 Iris-virginica 6.3 3.4 5.6 2.4 Iris-virginica 6.4 3.1 5.5 1.8 Iris-virginica 6.0 3.0 4.8 1.8 Iris-virginica 6.9 3.1 5.4 2.1 Iris-virginica 6.7 3.1 5.6 2.4 Iris-virginica 6.9 3.1 5.1 2.3 Iris-virginica 5.8 2.7 5.1 1.9 Iris-virginica 6.8 3.2 5.9 2.3 Iris-virginica 6.7 3.3 5.7 2.5 Iris-virginica 6.7 3.0 5.2 2.3 Iris-virginica 6.3 2.5 5.0 1.9 Iris-virginica 6.5 3.0 5.2 2.0 Iris-virginica 6.2 3.4 5.4 2.3 Iris-virginica 5.9 3.0 5.1 1.8 Iris-virginica <User 139xxxxxxxxxxxxx>
问题诊断
如果您的代码在执行过程中无响应且没有任何输出,您可以在代码头部增加以下注释,DataWorks每隔30秒将输出所有线程的堆栈:
# -*- dump_traceback: true -*-该方法适用于0.11.4.1版本以上的PyODPS 3节点。
查看PyODPS的版本
您可以直接使用Python代码查询当前的PyODPS版本,也可以在任意一个PyODPS任务的运行日志中查看。
在PyODPS节点中使用代码查询PyODPS版本。
# 输入如下代码 import odps; print(odps.__version__) # 返回结果示例 0.11.2.3在PyODPS任务运行日志中查看PyODPS版本,示例如下。
附录:为其他用户授权
在使用DataWorks时,如果您想要其他指定用户(非子用户)访问本账号下的项目、表等,需要在DataWorks中新建ODPS SQL节点并运行以下授权命令,操作详情请参见创建ODPS SQL节点,其他权限详情请参见用户与权限。
--添加其他阿里云账号用户(项目级别)
add user ALIYUN$<account_name>;
--授予项目的CreateInstance权限
grant CreateInstance on project <project_name> to USER ALIYUN$<account_name>;
--授予表的desc、select权限
grant Describe, Select on table <table_name> to USER ALIYUN$<account_name>;
--查看授权结果
show grants for ALIYUN$<account_name>;授权结果示例:
附录:示例数据
您可参考PyODPS条件查询文档中的步骤1:创建表并导入数据在DataWorks中建好表pyodps_iris并写入数据,文档中的操作示例即以此表作为示例数据,为您演示基本操作。
- 本页导读 (1)