在项目中,您可以通过创建作业来进行任务开发。本文为您介绍作业编辑相关的创建、设置和运行等操作。
背景信息
前提条件
已创建项目或已被加入到项目中,详情请参见项目管理。
新建作业
- 进入数据开发的项目列表页面。
- 通过阿里云账号登录阿里云E-MapReduce控制台。
- 在顶部菜单栏处,根据实际情况选择地域和资源组。
- 单击上方的数据开发页签。
- 单击待编辑项目所在行的作业编辑。
- 新建作业。
设置作业
各类作业类型的开发与设置,请参见作业部分。以下内容介绍的是作业的基础设置、高级设置、共享库和告警设置。
- 在作业设置面板,设置基础信息。
配置项 说明 作业概要 作业名称 您创建作业的名称。 作业类型 您创建作业的类型。 失败重试次数 作业运行失败后的重试次数,可以选择的重试次数范围为:0~5次。 失败策略 作业运行失败后支持的策略如下: - 暂停当前工作流:作业运行失败后,不再继续执行当前工作流。
- 继续执行下一个作业:作业运行失败后,继续执行下一个作业。
根据业务情况,可以打开或者关闭使用最新作业内容和参数开关。- 关闭:作业失败后重新执行时,使用初始作业内容和参数生成作业实例。
- 打开:作业失败后重新执行时,使用最新的作业内容和参数生成作业实例。
作业描述 单击右侧的编辑,可以修改作业的描述。 运行资源 单击右侧的  图标,添加作业执行所依赖的JAR包或UDF等资源。
图标,添加作业执行所依赖的JAR包或UDF等资源。
您需要将资源先上传至OSS,然后在运行资源中直接添加即可。
配置参数 指定作业代码中所引用的变量的值。您可以在代码中引用变量,格式为${变量名}。 单击右侧的
图标,添加Key和Value,根据需要选择是否为Value进行加密。其中,Key为变量名,Value为变量的值。另外,您还可以根据调度启动时间在此配置时间变量,详情请参见作业日期设置。
在作业中添加注解
进行数据开发时,您可以通过在作业内容里添加特定的注解来添加作业参数。注解的格式如下。
!!! @<注解名称>: <注解内容>说明
!!!必须顶格,并且每行一个注解。
当前支持的注解如下。
| 注解名称 | 说明 | 示例 |
|---|---|---|
| rem | 表示一行注释。 | |
| env | 添加一个环境变量。 | |
| var | 添加一个自定义变量。 | |
| resource | 添加一个资源文件。 | |
| sharedlibs | 添加依赖库,仅对Streaming SQL作业有效。包含多个依赖库时,依赖库间用英文半角逗号(,)隔开。 | |
| scheduler.queue | 设置提交队列。 | |
| scheduler.vmem | 设置申请内存,单位MB。 | |
| scheduler.vcores | 设置申请的核数。 | |
| scheduler.priority | 设置申请的优先级,取值范围为1~100。 | |
| scheduler.user | 设置提交用户名。 | |
注意
使用注解时,需要注意以下事项:
- 无效注解将被自动跳过。例如,设置未知注解、注解内容不符合预期等。
- 注解中的作业参数优先级高于作业配置中的参数,如果作业注解和作业配置中有相同的参数,则以作业注解为准。
作业注解示例如下: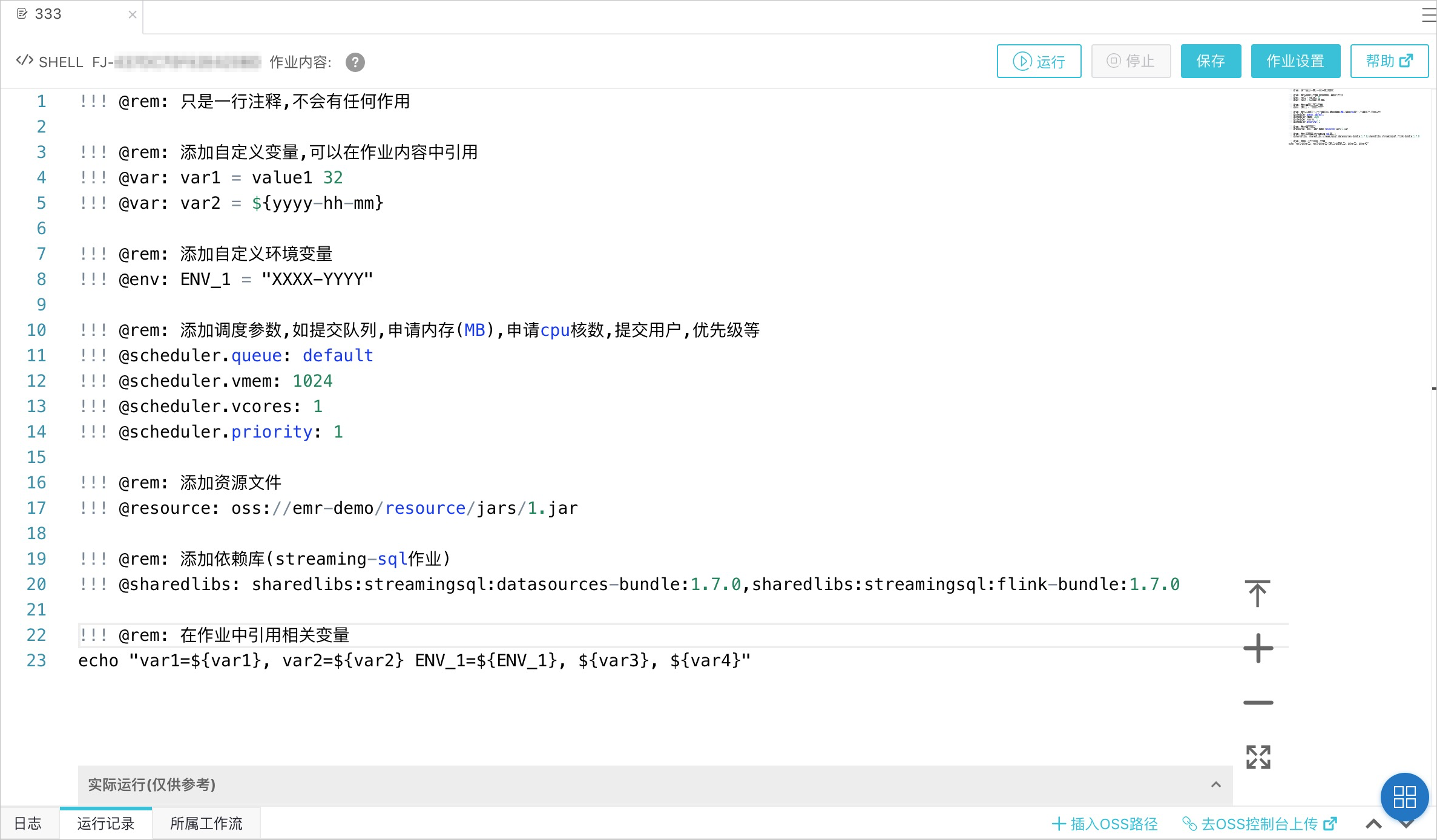
运行作业
- 执行作业。
- 在新建的作业页面,单击右上方的运行来执行作业。
- 在运行作业对话框中,选择资源组和执行集群。
- 单击确定。
- 查看作业运行日志。
- 作业运行后,您可以在日志页签中查看作业运行的日志。
- 作业运行后,您可以在日志页签中查看作业运行的日志。
作业可执行操作
在作业编辑区域,您可以在作业名称上单击右键,执行如下操作。
| 操作 | 说明 |
|---|---|
| 克隆作业 | 在相同文件夹下,克隆当前作业的配置,生成一个新的作业。 |
| 重命名作业 | 重新命名作业名称。 |
| 删除作业 | 只有在作业没有关联工作流,或关联的工作流没有在运行或调度时,才可以被删除。 |
作业提交模式说明
Spark-Submit进程(在数据开发模块中为启动器Launcher)是Spark的作业提交命令,用于提交Spark作业,一般占用600 MB以上内存。作业设置面板中的内存设置,用于设置Launcher的内存配额。
新版作业提交模式包括以下两种。
| 作业提交模式 | 描述 |
|---|---|
| 在Header/Gateway节点提交 | Spark-Submit进程运行在Header节点上,不受YARN监控。Spark-Submit内存消耗大,作业过多会造成Header节点资源紧张,导致整个集群不稳定。 |
| 在Worker节点提交 | Spark-Submit进程运行在Worker节点上,占用YARN的一个Container,受YARN监控。此模式可以缓解Header节点的资源使用。 |
在E-MapReduce集群中,作业实例消耗内存计算方式如下。
作业实例消耗内存 = Launcher消耗内存 + 用户作业(Job)消耗内存在Spark作业中,用户作业(Job)消耗内存又可以进一步细分,计算方式如下。
Job消耗内存 = Spark-Submit(指逻辑模块,非进程)消耗内存 + Driver端消耗内存 + Executor端消耗内存作业配置不同,Driver端消耗的物理内存的位置也不同,详细内容如下表。
| Spark使用模式 | Spark-Submit和Driver端 | 进程情况 | |
|---|---|---|---|
| Yarn-Client模式 | 作业提交进程使用LOCAL模式 | Spark-Submit和Driver端是在同一个进程中。 | 作业提交进程是Header节点上的一个进程,不受YARN监控。 |
| 作业提交进程使用YARN模式 | 作业提交进程是Worker节点上的一个进程,占用YARN的一个Container,受YARN监控。 | ||
| Yarn-Cluster模式 | Driver端是独立的一个进程,与Spark-Submit不在一个进程中。 | Driver端占用YARN的一个Container。 | |