本文将通过示例,为您介绍导出MaxCompute SQL计算结果的方法。
本文中所有SDK部分仅以Java举例。
概述
SQLTask方式导出
SQLTask使用SDK方法,直接调用MaxCompute SQL的接口SQLTask.getResult(i),可以很方便地运行SQL并获得其返回结果。使用方法请参见SQLTask。
使用SQLTask时,请注意:
SQLTask.getResult(i)用于导出SELECT查询结果,不适用于导出show tables等其他MaxCompute命令操作结果。
SELECT语句返回给客户端的数据条数可以通过READ_TABLE_MAX_ROW进行设置,详情请参见项目空间操作。
SELECT语句最多返回1万条数据至客户端。即如果在客户端(包括SQLTask)直接执行SELECT语句,相当于在SELECT语句最后加了Limit N。
Tunnel方式导出
如果您需要导出的查询结果是某张表的全部内容(或者是具体的某个分区的全部内容),可以通过Tunnel来实现,详情请参见命令行工具 和基于SDK编写的Tunnel SDK。
此处提供一个Tunnel命令行导出数据的简单示例,Tunnel SDK的编写适用于Tunnel命令行无法支持的场景,详情请参见批量数据通道概述。
tunnel d wc_out c:\wc_out.dat;
2016-12-16 19:32:08 - new session: 201612161932082d3c9b0a012f68e7 total lines: 3
2016-12-16 19:32:08 - file [0]: [0, 3), c:\wc_out.dat
downloading 3 records into 1 file
2016-12-16 19:32:08 - file [0] start
2016-12-16 19:32:08 - file [0] OK. total: 21 bytes
download OKSQLTask配合Tunnel方式导出
SQLTask不能处理超过1万条数据,而Tunnel方式可以,两者可以互补,因此可以基于两者实现超过1万条数据的导出。
代码实现的示例如下。
Odps odps = OdpsUtils.newDefaultOdps(); // 初始化Odps对象。
Instance i = SQLTask.run(odps, "select * from wc_in;");
i.waitForSuccess();
//创建InstanceTunnel。
InstanceTunnel tunnel = new InstanceTunnel(odps);
//根据instance id,创建DownloadSession。
InstanceTunnel.DownloadSession session = tunnel.createDownloadSession(odps.getDefaultProject(), i.getId());
long count = session.getRecordCount();
//输出结果条数。
System.out.println(count);
//获取数据的写法与TableTunnel一样。
TunnelRecordReader reader = session.openRecordReader(0, count);
Record record;
while((record = reader.read()) != null)
{
for(int col = 0; col < session.getSchema().getColumns().size(); ++col)
{
//wc_in表字段均为STRING,这里直接打印输出,或者用户可以直接写出到本地文件
System.out.println(record.get(col));
}
}
reader.close();DataWorks数据同步方式导出
DataWorks支持运行SQL并配置数据同步任务,以完成数据生成和导出需求。
登录DataWorks控制台。
在左侧导航栏,单击工作空间列表。
单击相应工作空间操作列的快速进入 > 数据开发。
新建业务流程。
右键单击业务流程,选择新建业务流程
输入业务名称。
单击新建。
创建SQL节点。
右键单击业务流程,选择。
填写节点名称为runsql,单击确认。
配置ODPS SQL节点,配置完成后单击保存。
创建数据同步节点。
右键单击业务流程,选择。
填写节点名称为sync2mysql,单击确认。
选择数据来源以及去向。
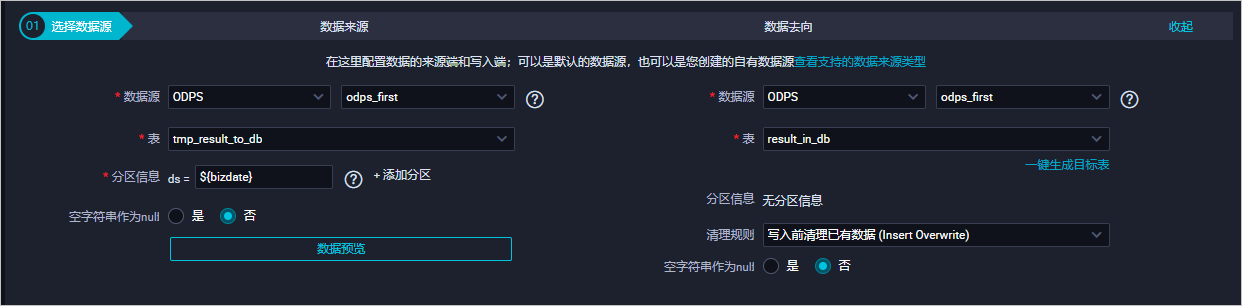
配置字段映射。

配置通道控制。
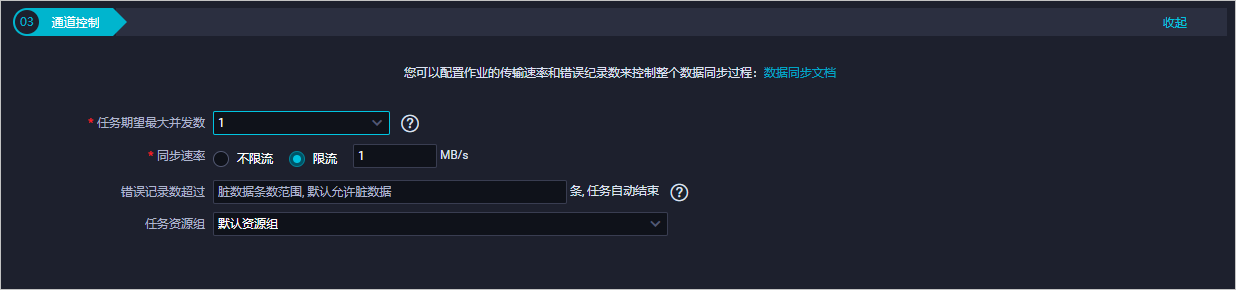
单击保存。
将数据同步节点和ODPS SQL节点连线配置成依赖关系,ODPS SQL节点作为数据的产出节点,数据同步节点作为数据的导出节点。
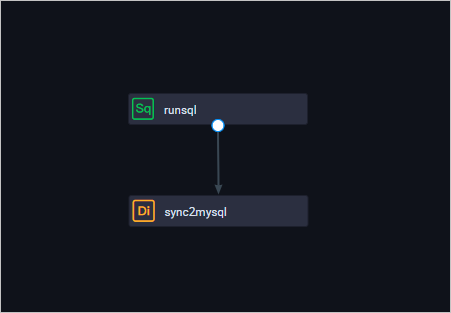
工作流调度配置完成后(可以直接使用默认配置),单击运行。数据同步的运行日志,如下所示。
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34 任务结束时刻 : 2016-12-17 23:43:46 任务总计耗时 : 11s 任务平均流量 : 31.36KB/s 记录写入速度 : 1668rec/s 读出记录总数 : 16689 读写失败总数 : 0执行如下SQL语句查看数据同步的结果。
select count(*) from result_in_db;
- 本页导读 (1)