本文为您介绍如何开发Java UDF,分别提供UDF、UDAF、UDTF的代码示例,并提供了通过三种方法开发UDF的完整流程。
背景信息
MaxCompute的UDF包括UDF、UDAF和UDTF,这三种函数被统称为UDF,更多信息请参见MaxCompute UDF概述。
Java UDF的开发可以通过MaxCompute Studio实现,详情请参见 开发UDF。
UDF示例
通过MaxCompute Studio开发字符小写转换功能的UDF步骤如下:
- 准备工具环境并创建Java Module。
您需要完成准备工作,包括安装Studio并在Studio上创建MaxCompute项目连接以及创建MaxCompute Java Module。
- 编写代码。
- 在Project区域,右键单击Module的源码目录(即),选择。
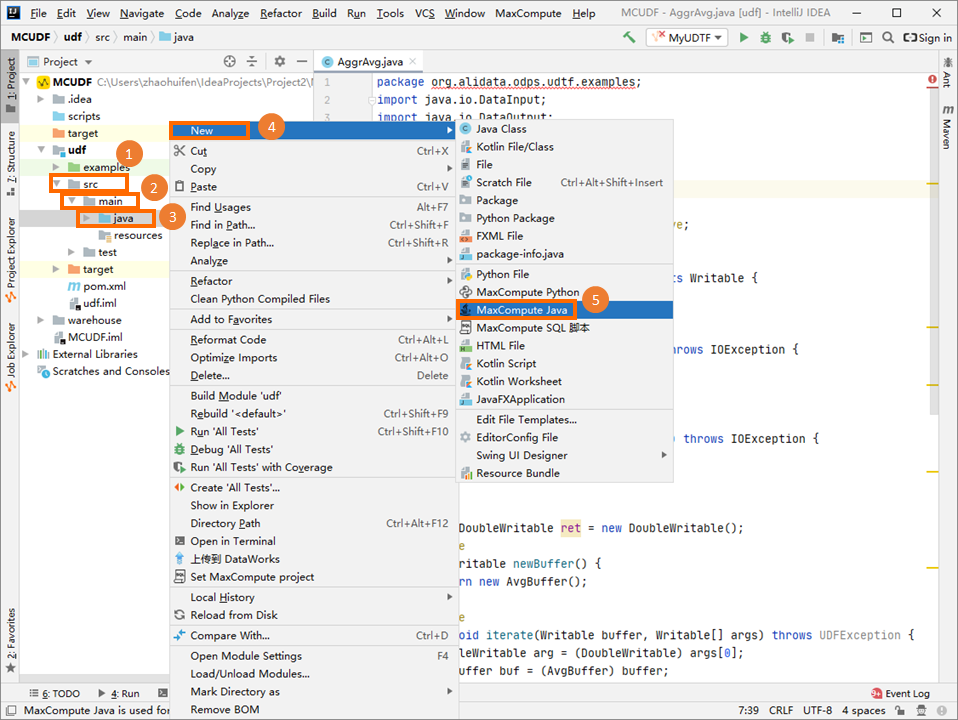
- 在Create new MaxCompute java class对话框,配置Name和Kind,单击OK。
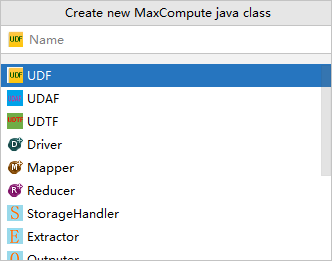
- Name:创建的MaxCompute Java Class名称。如果还没有创建Package,在此处填写packagename.classname,会自动生成Package。
- Kind:选择类型为UDF。支持的类型包含自定义函数(UDF、UDAF和UDTF)、MapReduce(Driver、Mapper和Reducer)和非结构化开发(StorageHandler、Extractor和Outputer)等。
- 创建成功后,编辑代码如下。
package <package名称>; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }说明 如果需要本地调试Java UDF,请参见开发和调试UDF。
- 在Project区域,右键单击Module的源码目录(即),选择。
- 注册MaxCompute UDF。
右键单击UDF的Java文件,选择Deploy to server...。在Package a jar and submit resource对话框中配置参数。配置完成,单击OK。
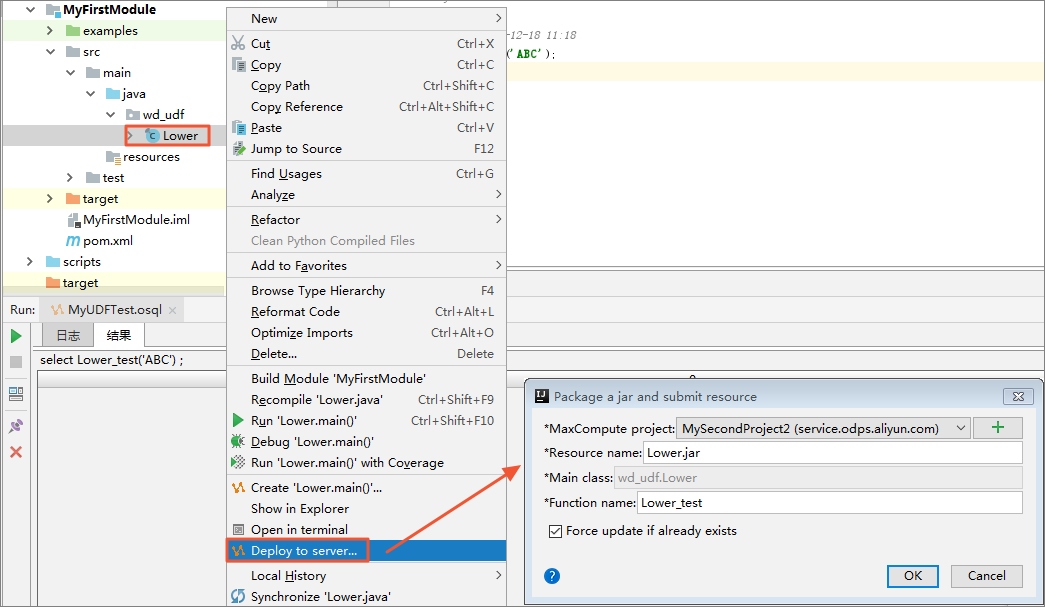
- MaxCompute project:UDF所在的MaxCompute Project名称。
- Resource name:输入注册的资源名称。
- Function name:输入注册的函数名称。
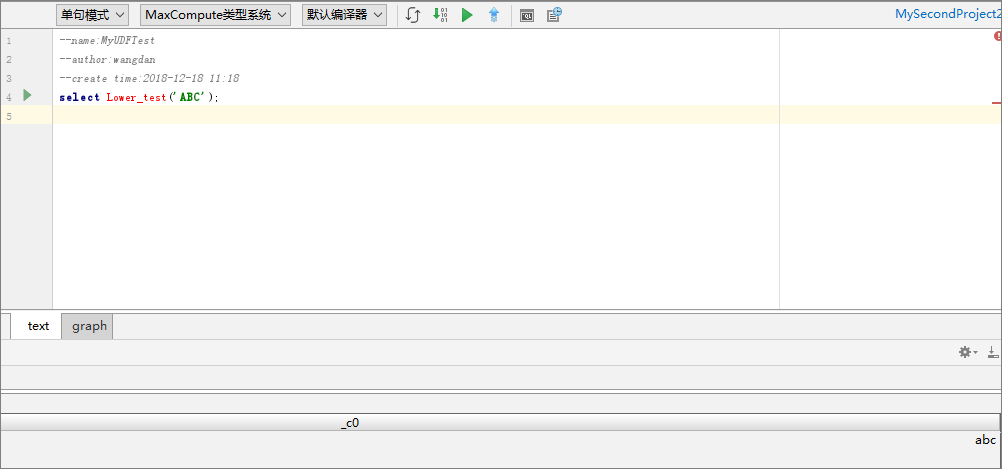
- 试用UDF。
UDAF示例代码
UDAF的注册方式与UDF基本相同,使用方式与内建函数中的聚合函数相同。计算平均值的UDAF的代码示例如下。
package org.alidata.odps.udf.examples;
import com.aliyun.odps.io.LongWritable;
import com.aliyun.odps.io.Text;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
/**
* project: example_project
* table: wc_in2
* partitions: p2=1,p1=2
* columns: colc,colb,cola
*/
public class UDAFExample extends Aggregator {
@Override
public void iterate(Writable arg0, Writable[] arg1) throws UDFException {
LongWritable result = (LongWritable) arg0;
for (Writable item : arg1) {
Text txt = (Text) item;
result.set(result.get() + txt.getLength());
}
}
@Override
public void merge(Writable arg0, Writable arg1) throws UDFException {
LongWritable result = (LongWritable) arg0;
LongWritable partial = (LongWritable) arg1;
result.set(result.get() + partial.get());
}
@Override
public Writable newBuffer() {
return new LongWritable(0L);
}
@Override
public Writable terminate(Writable arg0) throws UDFException {
return arg0;
}
}UDTF示例代码
UDTF的注册和使用方式与UDF相同,代码示例如下。
package org.alidata.odps.udtf.examples;
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.UDTFCollector;
import com.aliyun.odps.udf.annotation.Resolve;
import com.aliyun.odps.udf.UDFException;
// TODO define input and output types, e.g., "string,string->string,bigint".
@Resolve({"string,bigint->string,bigint"})
public class MyUDTF extends UDTF {
@Override
public void process(Object[] args) throws UDFException {
String a = (String) args[0];
Long b = (Long) args[1];
for (String t: a.split("\\s+")) {
forward(t, b);
}
}
}MaxCompute提供多种内建函数来满足您的计算需求,同时您还可以使用DataWorks创建注册MaxCompute函数来满足不同的计算需求。UDF更多示例请参考更多UDF示例。