机器学习开发示例
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何使用阿里云 Databricks 数据洞察的Notebook进行机器学习开发。
首次使用DDI产品创建的Bucket为系统目录Bucket,不建议存放数据,您需要再创建一个Bucket来读写数据。
DDI访问OSS路径结构:oss://BucketName/Object
BucketName为您的存储空间名称。
Object为上传到OSS上的文件的访问路径。
例:读取在存储空间名称为databricks-demo-hangzhou文件路径为demo/The_Sorrows_of_Young_Werther.txt的文件
// 从oss地址读取文本文档
val dataRDD = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")开发流程
在本教程中,您将执行以下步骤:
创建集群并通过knox账号访问Notebook
创建Notebook、加载样本数据
准备ML算法数据
建立模型、运行线性回归模型
评估线性回归模型
可视化线性回归模型
步骤一:创建集群并通过knox账号访问Notebook
创建集群参考: 创建集群,需注意要设置ram子账号及保存好knox密码,登录WebUI时候需要用到。
步骤二:创建Notebook、加载样本数据
开始进行机器学习的最简单方法是使用对象存储工作区中可访问的文件夹中的示例Databricks数据集 。例如,要访问将城市人口数量与房屋平均价格进行比较的文件,您可以通过oss路径访问文件。例如:oss://databricks-datasets/samples/data_geo.csv。
1.加载oss数据,并缓存
%pyspark
path="oss://databricks-datasets/samples/data_geo.csv" # 根据oss路径;
# 加载样本数据并打印;
data = spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.csv(path) \
data.cache() # 缓存数据以加快重用2.数据展示,打印schema
%pyspark
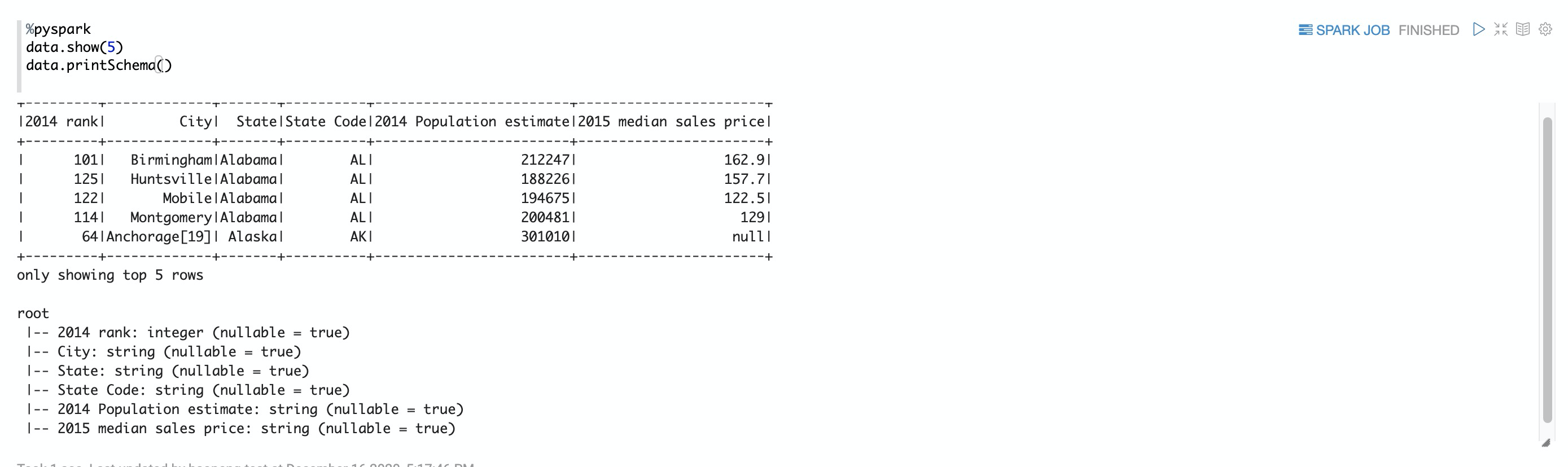
data.show(5)
data.printSchema()数据打印
步骤三:准备ML算法数据
在监督学习(例如回归算法)中,通常需要定义标签(lable)和一组要素(features)。在此线性回归示例中,标签为2015年中位数销售价格(lable),特征为2014年人口估计(features)。您使用特征来预测标签(售价)。
1.数据类型转换,删除缺少值的行,然后重命名特征和标签列,并用"_"替换空格
%pyspark
from pyspark.sql.functions import col
from pyspark.sql.types import DoubleType
#数据类型转换
datat=data.select(col("2014 rank"),col("city"),col("state"),col("State Code"),col("2014 Population estimate"),col("2015 median sales price").cast(DoubleType()))
#删除缺少值的行
datat = datat.dropna()
#重命名特征和标签列,并用"_"替换空格
exprs = [col(column).alias(column.replace(' ', '_')) for column in datat.columns]2.为了简化特征的创建,请注册UDF以将特征(2014_Population_estimate)列向量转换为VectorUDT类型并将其应用于该列
%pyspark
from pyspark.ml.linalg import Vectors, VectorUDT
# 定义UDF函数,数据向量化处理;
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
ml_data = datat.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
3.数据展示
%pyspark
# 数据展示
ml_data.show()ML算法数据打印

步骤四:建立模型、运行线性回归模
在本部分中,您将使用不同的正则化参数运行两个不同的线性回归模型,以基于人口(features)确定这两个模型中的任何一个对销售价格(label)的预测程度。
1.建立模型
%pyspark
from pyspark.ml.regression import LinearRegression
# 定义LinearRegression算法
lr = LinearRegression()
# 建立模型
modelA = lr.fit(ml_data, {lr.regParam:0.0})
modelB = lr.fit(ml_data, {lr.regParam:100.0})
2.使用该模型并作出预测,您可以使用transform()函数进行预测,该函数会添加新的预测列。例如下面的代码采用第一个模型(modelA),并根据特征(features)向您显示标签(原始销售价格)和预测(预测销售价格)
%pyspark
# 运行线性回归模型,并展示数据
predictionsA = modelA.transform(ml_data)
predictionsA.show(10)数据打印
步骤五:评估线性回归模型
要评估回归分析,请使用RegressionEvaluator来计算均方根误差 。
在机器学习中我们用计算测试值和预测值之间出现的误差的均方根的平均值来查看模型的准确性。
%pyspark
from pyspark.ml.evaluation import RegressionEvaluator
# 使RegressionEvaluator用来计算均方根误差 。
evaluator = RegressionEvaluator(metricName="rmse")
RMSE = evaluator.evaluate(predictionsA)
print("ModelA: Root Mean Squared Error = " + str(RMSE))
# ModelA: Root Mean Squared Error = 128.602026843
predictionsB = modelB.transform(ml_data)
RMSE = evaluator.evaluate(predictionsB)
print("ModelB: Root Mean Squared Error = " + str(RMSE))
# ModelB: Root Mean Squared Error = 129.496300193RMSE评估结果打印
我们的RMSE值约为128~130。 好的模型的RMSE值应小于180。如果您具有较高的RMSE值,则意味着您可能需要更改功能或调整超参数。
步骤六:可视化线性回归模型
可视化散点图,与许多机器学习算法一样使用matplotlib创建线性回归图以显示散点图和两个回归模型。
依赖库导入
当使用pyspark进行开发时候,依赖的库可以通过ddi库能力导入,具体见:Python库管理
这里示例导入matplotlib库,并做展示——先download下官方库安装包,在库功能下进行.whl文件的上传,在需要使用库的集群里进行安装
2.创建Python DataFrame 、使用matplotlib做图渲染 、图打印
%pyspark
#为展示效果,本实例对样本数据做了部分筛选;
import matplotlib.pyplot as plt
import numpy as np
# 创建 Python DataFrame
pop = ml_data.rdd.map(lambda p: (p.features[0])).collect()
price = ml_data.rdd.map(lambda p: (p.label)).collect()
predA = predictionsA.select("prediction").rdd.map(lambda r: r[0]).collect()
predB = predictionsB.select("prediction").rdd.map(lambda r: r[0]).collect()
# 图渲染
plt.scatter(pop,price, color='black')
plt.plot(pop,predA,color='blue', linewidth=2)
plt.plot(pop,predB,color='green', linewidth=2)
# 图打印
z.show(plt)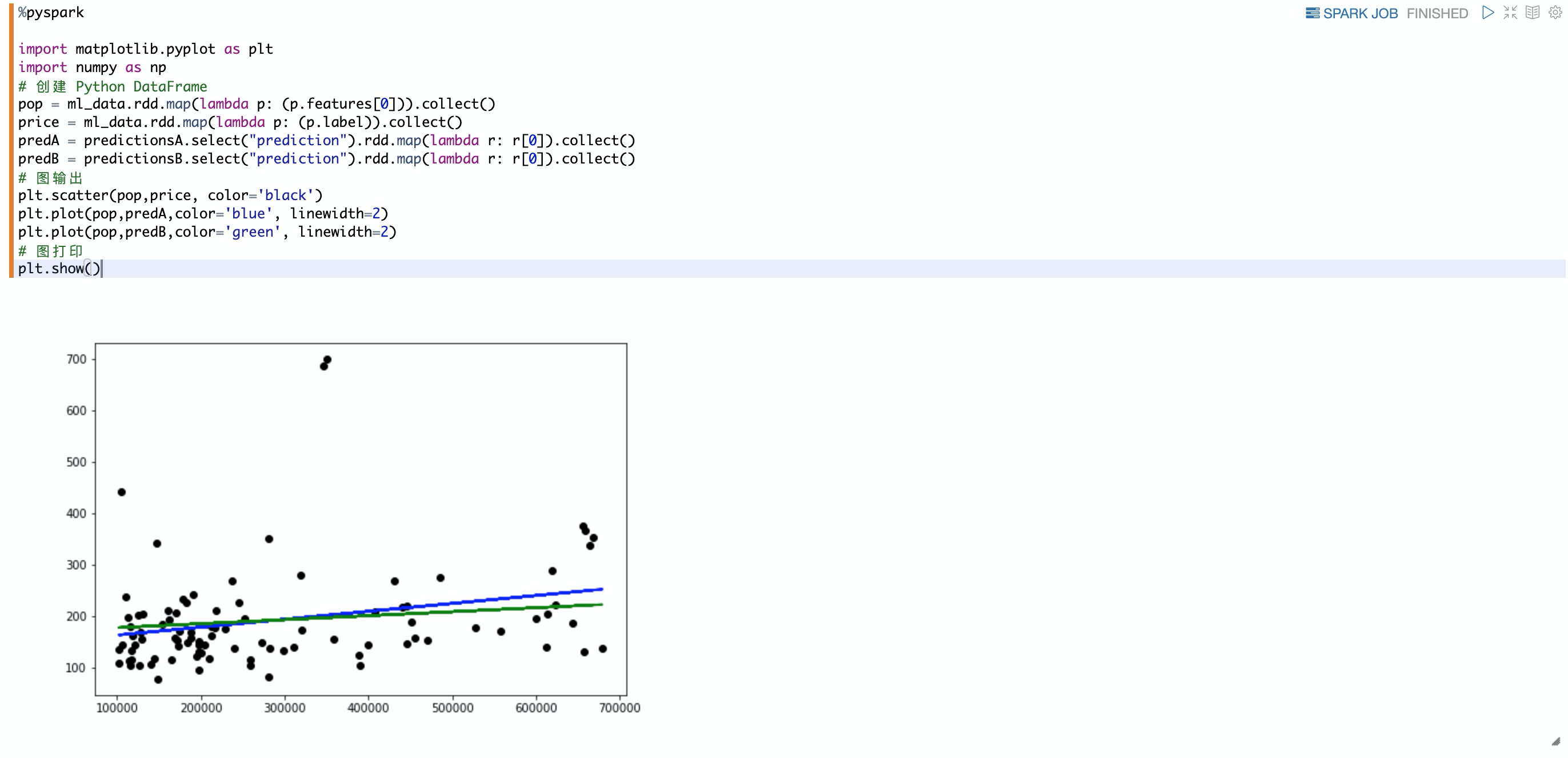
- 本页导读 (0)