DataX是异构数据源离线同步的工具,支持多种异构数据源之间高效的数据同步。Dataphin系统内嵌了DataX组件,支持通过构建Shell任务调用DataX,实现数据同步。本教程以RDS MySQL数据库为例,为您介绍基于Dataphin如何调用DataX同步数据。
前提条件
- 已开通RDS MySQL实例,且RDS MySQL实例的网络类型为专有网络。如何开通RDS MySQL实例,请参见创建RDS MySQL实例。
- 已创建RDS MySQL实例的数据库和账号,创建过程中需要您记录数据库名称、用户名和密码。如何创建数据库和账号,请参见创建数据库和账号。
背景信息
Dataphin系统内嵌了DataX组件,在Dataphin中创建和运行DataX任务(Shell任务)即可将DataX调用起来,以实现数据同步。
DataX支持同步数据的数据源包括MySQL、Oracle、SQL Server、PostgreSQL、HDFS、Hive、HBase等。DataX的更多信息,请参见DataX。
使用限制
Shell任务不支持通过内网地址访问RDS MySQL实例。
操作流程
| 功能 | 描述 |
|---|---|
| 步骤一:连通RDS MySQL实例与Dataphin间的网络 | 在您开始同步数据前,首先需要连通RDS MySQL实例和Dataphin间的网络。 |
| 步骤二:创建数据同步的源表和目标表 | 登录至RDS MySQL实例,创建本教程中用于数据同步的源表和目标表。 |
| 步骤三:下载并配置DataX任务的代码模板 | 下载并配置DataX任务的代码模板后,保存为datax.json。 |
| 步骤四:上传datax.json文件至Dataphin | 上传DataX任务代码文件至Dataphin平台后,DataX任务即可调用。 |
| 步骤五:创建DataX任务 | 在开发环境创建并运行同步数据的DataX任务。 |
| 步骤六:运行生产环境中的DataX任务 | 在生产环境运行DataX任务,保障生产环境业务数据的正常产出。 |
步骤一:连通RDS MySQL实例与Dataphin间的网络
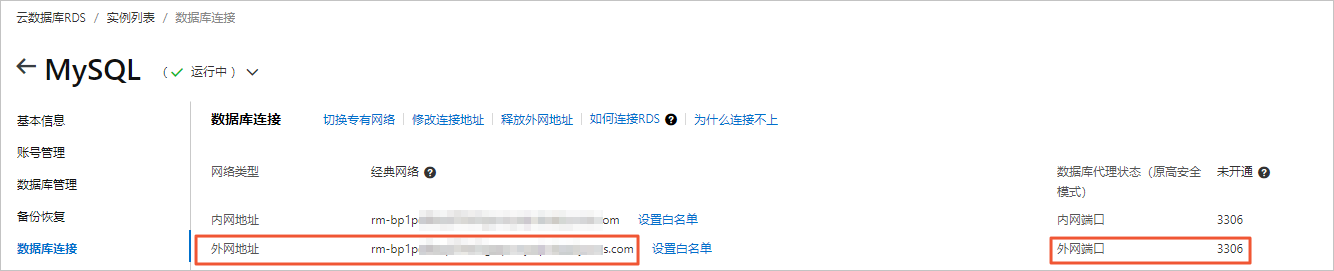
- 在数据库连接页面,获取RDS MySQL实例的外网地址和端口。
步骤二:创建数据同步的源表和目标表
使用命令行方式连接RDS MySQL实例,请参见方法三:使用命令行方式连接实例。创建同步数据的源数据表和目标数据表:
- 创建源数据表的代码示例如下。
create table datax_test1( area varchar(255),province varchar(255) ); insert into datax_test1 values('华北','山东省'),('华南','河南省'); - 创建目标数据表的代码示例如下。
create table datax_test2( area varchar(255),province varchar(255) );
步骤三:下载并配置DataX任务的代码模板
步骤四:上传datax.json文件至Dataphin
- 在数据处理页面的左侧导航栏,单击
 资源管理图标。
资源管理图标。 - 在资源管理页面,单击资源管理后的
 图标。
图标。 - 在新建资源对话框中,配置参数后,单击提交。
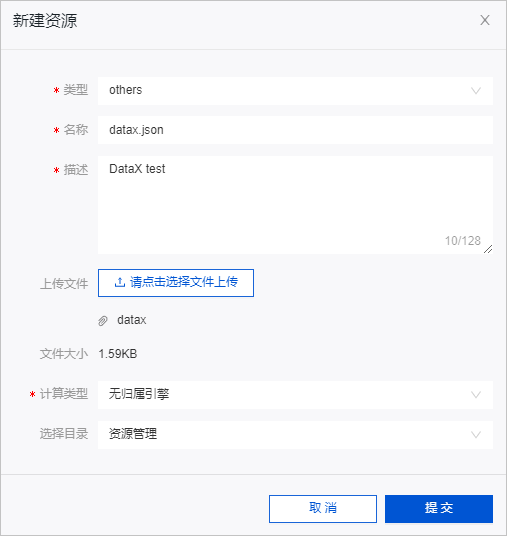
参数 描述 类型 本教程中需要上传的文件格式为JSON,则类型选择others。
系统支持选择的类型包括file、jar、python和others,适用场景说明如下:- 上传的文件格式为XLS、DOC、TXT、CSV,则类型选择为file。
- 上传的文件格式为JAR,则类型选择为jar。
- 上传的文件格式为PY,则类型选择为python。
- 上传的文件格式非XLS、DOC、TXT、CSV、JAR、PY,则类型选择为others。
名称 本教程中的名称为datax.json。 本教程名称的命名规则如下:- 名称必须以.json结尾。
- 字母、数字、下划线(_)或半角句号(.)组合组成。
- 不能以数字开头。
描述 填写资源的描述,例如DataX test。 上传文件 选择步骤三:下载并配置DataX任务的代码模板中保存至本地的datax.json文件。 计算类型 本教程中上传的资源(datax.json)用于DataX代码任务中引用,因此选择无归属引擎。 计算类型用于定义资源文件是否需要上传至计算引擎的存储层。Dataphin系统支持的计算类型包括MaxCompute、Flink和无归属引擎,适用场景说明如下:- 自定义MaxCompute类型的函数时,计算类型选择为MaxCompute。
- 自定义Flink类型的函数时,计算类型选择为Flink。
- 代码任务引用的资源文件,计算类型选择为无归属引擎。
选择目录 默认为资源管理。 - 发布资源文件至生产环境。
- 在数据处理页签,单击datax.json资源的操作列下的
 图标。
图标。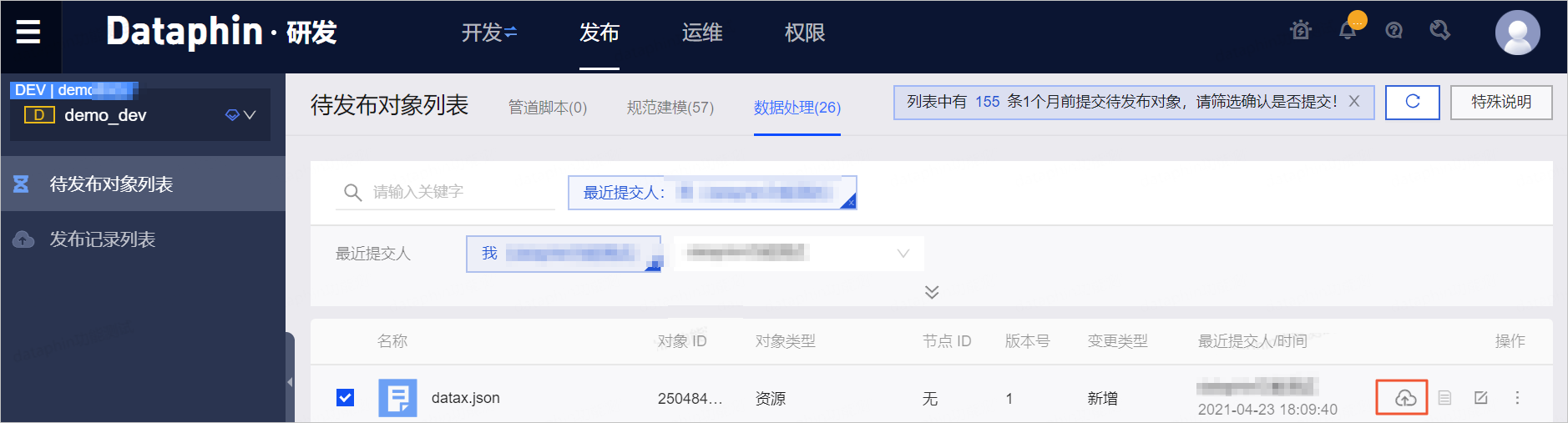
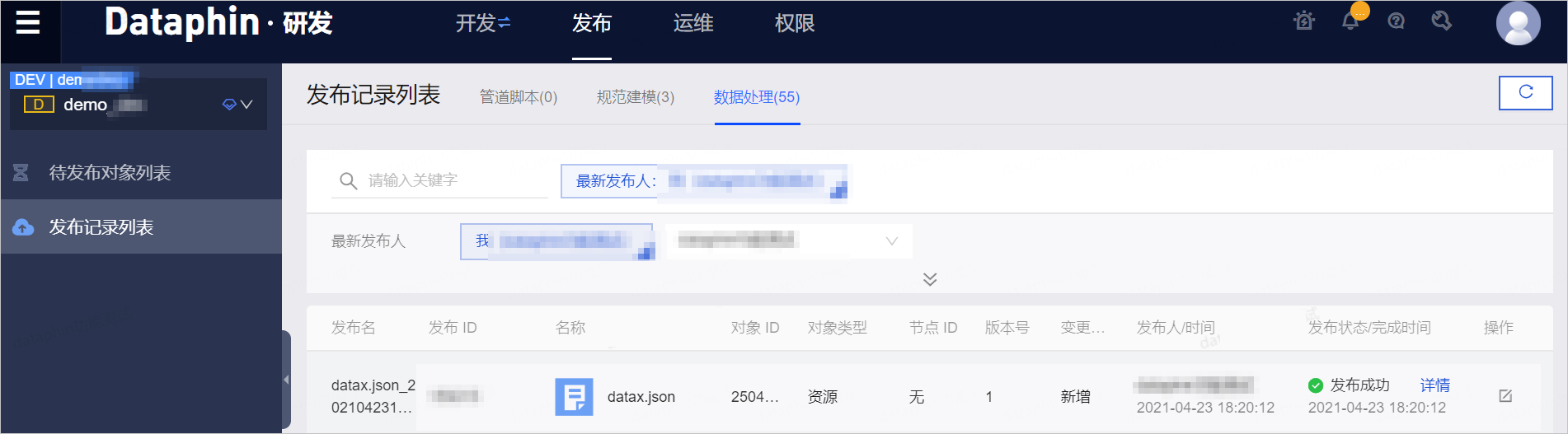
- 单击左侧导航栏的发布记录列表。在发布记录列表页面,查看资源文件的发布状态为发布成功即可。
- 在数据处理页签,单击datax.json资源的操作列下的
步骤五:创建DataX任务
- 在数据处理页面,单击左侧导航栏
 计算任务图标。
计算任务图标。 - 在计算任务页面,单击计算任务后的图标,选择。
- 在新建文件对话框,配置参数后,单击确定。
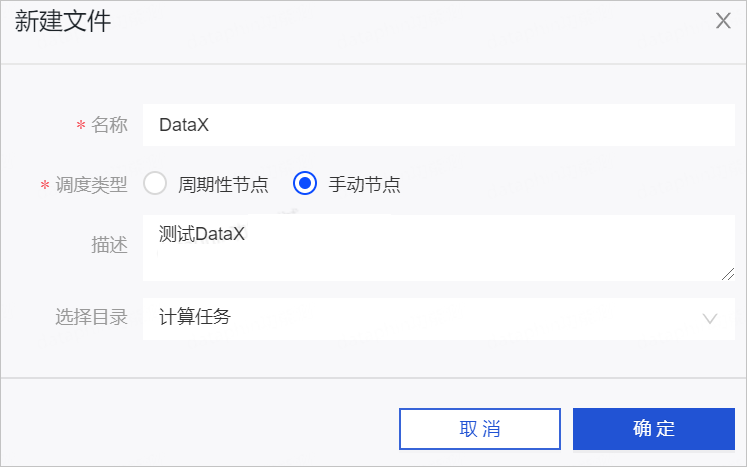
参数 描述 名称 本教程中的名称为DataX。 调度类型 本教程中选择任务的调度类型为手动节点。 调度类型用于定义任务发布至生产环境的调度方式。Datpahin系统支持的调度类型包括周期性节点和手动节点,适用场景说明如下:- 任务需要参与系统的周期性调度,且需要依赖上游节点,则调度类型选择为周期性节点。
- 任务不需要参与系统的周期性调度,且需要依赖上游节点,则调度类型选择为手动节点。该类型的任务在生产环境的运行需要您手动触发。
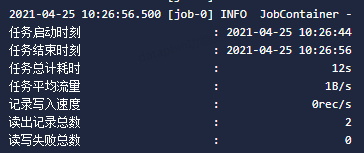
描述 填写对任务的简单描述,例如测试DataX。 选择目录 默认为计算任务。 - 单击页面右上角的执行,即可运行DataX任务。运行结果显示的读写失败总数为0时,表示DataX任务同步数据成功。
- 发布DataX任务至生产环境。
- 在数据处理页签,单击DataX任务的操作列下的图标。

- 单击左侧导航栏的发布记录列表。在发布记录列表页面,查看DataX任务的发布状态为发布成功即可。

- 在数据处理页签,单击DataX任务的操作列下的
步骤六:运行生产环境中的DataX任务
- 请参见步骤四:上传datax.json文件至Dataphin,进入数据开发页面。
- 在数据开发页面,单击顶部菜单栏的运维。
- 在运维中心,单击项目名称后的
 图标,切换至生产环境(
图标,切换至生产环境( )。
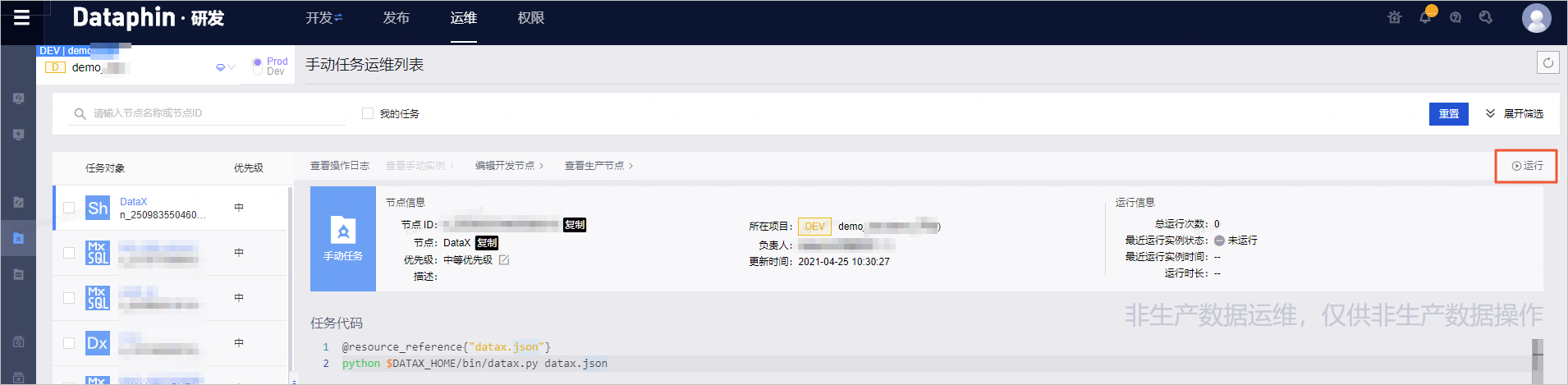
)。 - 在运维中心,运行DataX任务。
- 单击左侧导航栏的
 图标。
图标。 - 在DataX任务的详情页面,单击页面左上角的运行。
- 单击左侧导航栏的
- 查看DataX任务运行生成的实例运行日志。
- 单击左侧导航栏的
 图标。
图标。 - 在DataX任务的详情页面,单击页面上方的查看运行日志。

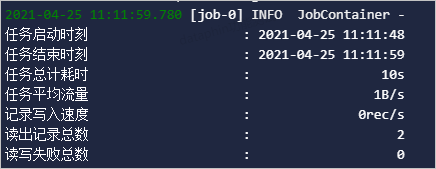
- 在运行日志页面,查看读写失败总数。运行日志显示的读写失败总数为0时,表示DataX任务在生产环境同步数据成功,即可保障生产环境业务数据正常产出。
- 单击左侧导航栏的