自动优化
自动优化是Delta Engine一组可选特性,当开启该组特性后,Delta Engine会自动合并对Delta表的多次写入产生的小文件,以牺牲部分写性能为代价,大幅提升查询性能。自动优化在这些场景下尤其有用:1)能接受分钟级时延的流式数据入湖;2)常使用Merge Into,Insert Into和Create table as select的场景。
详细内容可参考Databricks官网文章:自动优化
自动优化的工作原理
自动优化包含两个重要特性:
优化Delta表的写入
在开源版Spark中,每个executor向partition中写入文件时,都会创建一个文件进行写入,最终会导致一个partition中包含大量的小文件,导致delta表的查询性能恶化。在Delta Engine中,会有一个专门的executor负责partition的写入,对partition的写入进行合并,避免小文件产生;
小文件自动合并
在每次写入之后,delta engine会检查文件是否可以进一步压缩,如果可以会自动执行一些OPTIMIZE 作业,对包含大量小文件的partition进行压缩。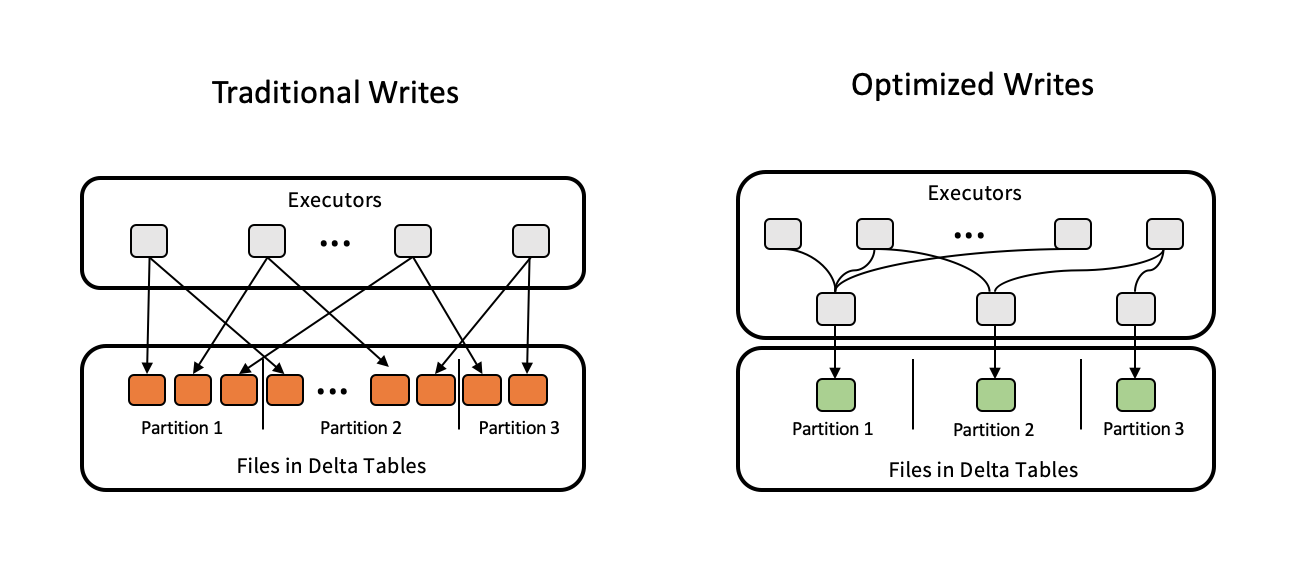 这两个特性:一个是对写入进行合并,防止小文件的产生并提高写数据的吞吐量,一个是对已经产生的小文件进行自动合并,优化查询性能,减少需要维护的元数据量。
这两个特性:一个是对写入进行合并,防止小文件的产生并提高写数据的吞吐量,一个是对已经产生的小文件进行自动合并,优化查询性能,减少需要维护的元数据量。
如何使用?
Auto Optimize需要在创建表时,显式指定:
优化表的写入过程:该特性由表属性
delta.autoOptimize.optimizeWrite控制自动执行小文件合并:该特性由表属性
delta.autoOptimize.autoCompact控制
创建表时指定:
%sql
CREATE TABLE student (id INT, name STRING)
TBLPROPERTIES
(delta.autoOptimize.optimizeWrite = true,
delta.autoOptimize.autoCompact = true)针对现存的表:
%sql
ALTER TABLE [table_name | delta.`<table-path>`]
SET TBLPROPERTIES
(delta.autoOptimize.optimizeWrite = true,
delta.autoOptimize.autoCompact = true)使用案例
在该案例中,我们创建一个新表,并使用一个for循环,不断的向该表中插入数据:
%sql
CREATE TABLE student (id INT, name STRING)
USING delta
LOCATION "oss://databricks-delta-demo/auto_optimize"
TBLPROPERTIES
(delta.autoOptimize.optimizeWrite = true,
delta.autoOptimize.autoCompact = true)%pyspark
import random
import string
for i in range(101):
name = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(20))
sql_query = f'INSERT INTO student VALUES ({i}, "{name}")'
spark.sql(sql_query)
print(f"Inserted {i + 1} entries.")在OSS browser里刷新,可以看到在向表中插入数据时产生了大量的小文件,在我们的代码里执行单行插入,对每一行都会生成一个单独的小文件,同时产生了两个delta log文件。
当插入了50条数据时,delta engine会自动的将前50个小文件进行合并,成为一个新的文件。自动小文件合并的阈值为50,即当发现表中有50个小文件才会进行合并。该阈值可以使用spark conf:spark.databricks.delta.autoCompact.minNumFiles进行控制。
何时启用写优化?
写优化的目的是为了提升写数据的吞吐量,它是通过减少被写入的文件数量来实现的,而代价就是降低了并行度。
并且由于写优化需要根据表的分区结构来对写入的数据进行额外的shuffle,额外的shuffle势必会引入额外的开销,但写入性能的提升一般可以抵消掉shuffle带来的开销,即使不能抵消,为了文件合并带来的查询性能提升,使用该特性也是值得的。
什么场景开启写优化?
能接受分钟级别时延的流处理场景;
频繁使用MERGE, UPDATE, DELETE, INSERT INTO, CREATE TABLE AS SELECT等SQL语句的场景。
什么场景关闭写优化?
当写入TB级及以上的数据。
何时启用自动压缩?
当对一张表成功写入之后,Delta engine会检查是否达到自动压缩阈值,如果达到,会同步执行一次自动压缩。自动压缩的一些特性:
自动压缩仅仅是做一些小文件合并,不会进行Z-Ordering优化;
手动执行Optimize命令时默认合并的文件大小为1GB,而自动压缩默认产生的文件大小为128MB(最大),可以使用spark conf:
spark.databricks.delta.autoCompact.maxFileSize进行控制;自动压缩会使用贪心算法,选择收益最大的一些partition来进行合并,具体的partition数量取决于集群配置,如果集群有更多的CPU,则更多的partition会被优化。
什么场景开启自动压缩?
能接受分钟级别时延的流处理场景;
没有周期性的对表进行优化。
什么场景关闭自动压缩?
当并发的对表执行DELETE,MERGE,UPDATE和自动压缩时,会导致这些作业的事务冲突,当自动压缩遇到事务冲突时,Delta engine不会进行重试。
- 本页导读 (0)