Notebook是由一个或多个Note单元组成的,每个Note是一个独立的Spark任务。本文介绍如何使用Notebook。
前提条件
开发Note
添加单元格
在DataInsight Notebook页面,将鼠标移动到任意已存在单元格的顶部或底部,单击+ Add Paragraph,即可在页面上添加新的单元格。
创建表
- 导入数据到数据库。
%spark.sql use db_demo; load data inpath 'oss://databricks-dbr/db_demo/bank/bank.csv' overwrite into table db_bank_demo; describe db_bank_demo;导入成功后,查看表信息如下所示。

删除单元格
- 在DataInsight Notebook页面,单击单元格右上角的
 图标。
图标。 - 选择Remove。
运行Note
在DataInsight Notebook页面,单击单元格右上角的![]() 图标,即可在Notebook内运行作业。
图标,即可在Notebook内运行作业。
查看可视化运行结果
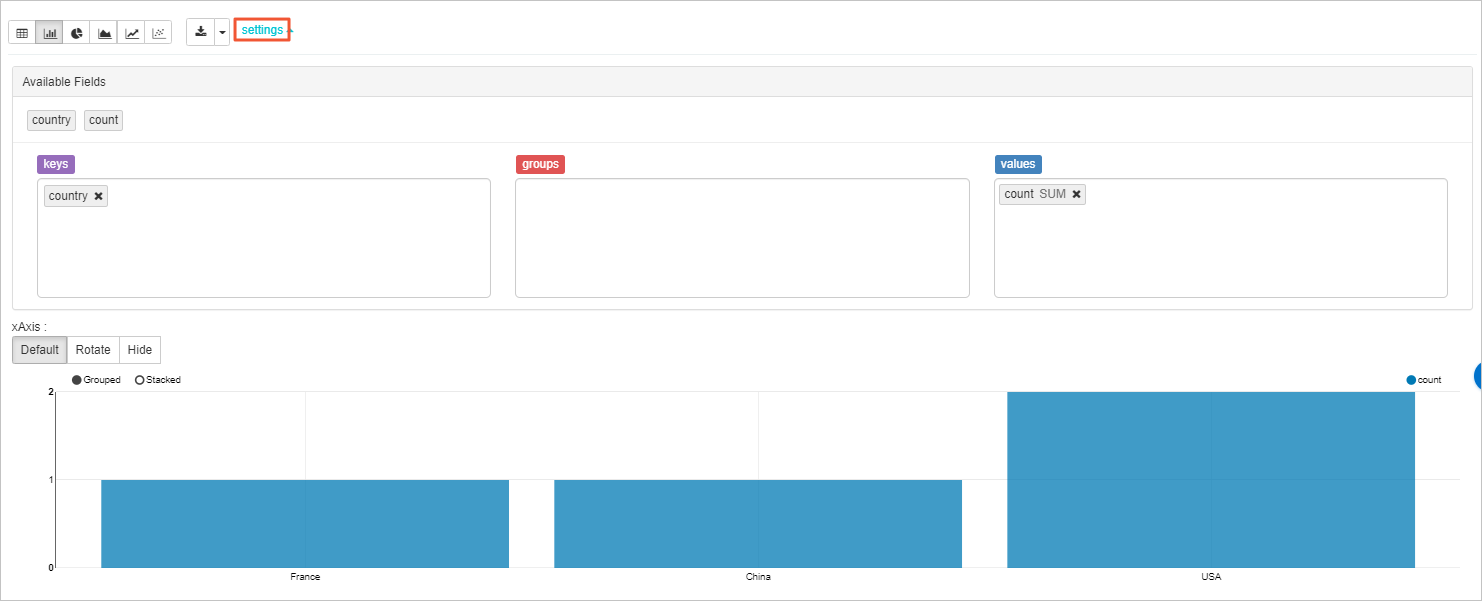
运行完Note后,在当前单元格中,可单击图形来查看运行结果。Notebook内置了多种图形来可视化Spark的DataFrame:Table、Bar Chart、Pie Chart、Area Chart、Line Chart、Scatter Chart,并且您可以单击settings对各种图形进行配置。
查看作业详情
修改Interpreter模式
默认情况下Spark Interpreter的绑定模式是Shared模式,即所有的Note都是共享同一个Spark App。如果是多用户场景的话,建议设置成Isolated Per Note,这样每个Note都有自己独立的Spark App,互相不会有影响。
- 在DataInsight Notebook页面,单击右上角的
 图标。
图标。 - 在Settings区域,单击Interpreter。
- 在spark区域,单击
 图标,按截图设置以下参数。
图标,按截图设置以下参数。
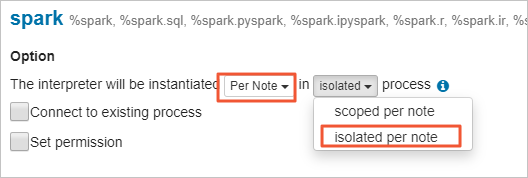
配置Interpreter
支持以下两种方式配置Interpreter:
- 配置全局的Interpreter。
- 在DataInsight Notebook页面,单击右上角的图标。
- 在Settings区域,单击Interpreter。
- 在spark区域,单击edit,修改相关的参数。
- 单击Save。
- 在弹出框中单击OK。
- 在DataInsight Notebook页面,单击右上角的
- 配置单个Note的Interpreter。
通过
%spark.conf来对每个Note的Spark Interpreter进行定制化,但前提是把Interpreter设置成isolated per note。在DataInsight Notebook页面的
%spark.conf区域,可修改相关的参数。%spark.conf SPARK_HOME <PATH_TO_SPARK_HOME> #set driver memory to 8g spark.driver.memory 8g #set executor number to be 6 spark.executor.instances 6 #set executor memory 4g spark.executor.memory 4g
问题反馈
您在使用阿里云Databricks数据洞察过程中有任何疑问,欢迎用钉钉扫描下面的二维码加入钉钉群进行反馈。