在项目中,您可以通过创建作业来进行任务开发。本文为您介绍如何创建作业、设置和删除作业。
前提条件
创建作业
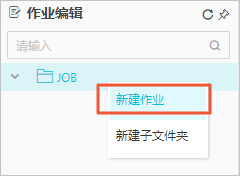
- 在作业编辑区域,在需要操作的文件夹上单击右键,选择新建作业。
设置作业
新建作业时、或者新建作业后,可对作业进行以下设置。
- 在作业设置页面,设置基础信息。
参数 描述 作业概要 作业描述:可修改作业的描述。 运行资源 单击右侧的  图标,添加作业执行所依赖的JAR包或HDFS等资源。您需要将资源先上传至OSS,然后在运行资源中直接添加即可。
图标,添加作业执行所依赖的JAR包或HDFS等资源。您需要将资源先上传至OSS,然后在运行资源中直接添加即可。
配置参数 指定作业代码中所引用的变量的值。您可以在代码中引用变量,格式为${变量名}。 单击右侧的
图标,添加Key和Value。其中,Key为变量名,Value为变量的值。另外,您还可以根据调度启动时间在此配置时间变量,详情请参见作业日期设置
删除作业
创建作业后,不再需要当前作业时可删除。
- 在项目空间页面,单击待操作项目所在行的删除。
- 在删除对话中,单击确定。