特征工程是机器学习训练过程中必不可少的环节,旨在找出对模型结果有益的特征交叉关系,通常需要算法工程师耗费大量精力去尝试。针对该场景,PAI推出智能特征交叉组件,帮助您锁定有意义的特征交叉。您可以根据返回的特征交叉结果,对这些特征进行组合,以提升模型效果。本文介绍智能特征交叉组件的使用方法。
流程图
智能特征交叉基于深度学习框架TensorFlow开发,底层有大量并行化计算的工作,需要使用GPU。目前只有华北2(北京)和华东2(上海)两个地域支持该功能。
总流程图如下所示。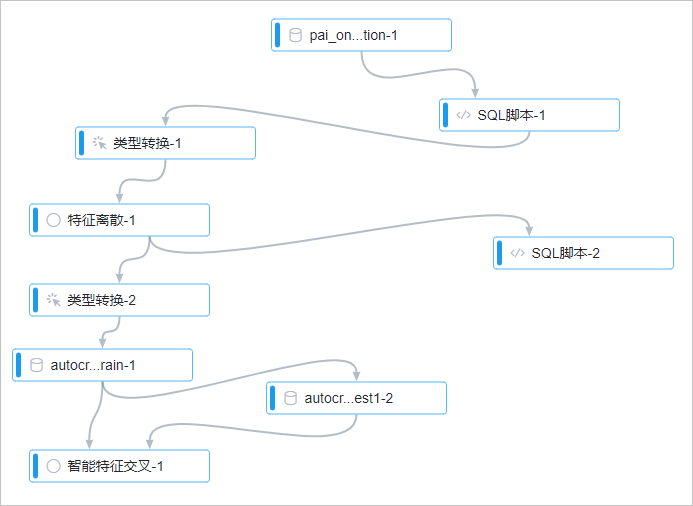
说明 使用首页的模板列表创建项目时,需要修改智能特征交叉组件的模型输出路径为您自己的OSS地址。
1.开通GPU和OSS访问权限
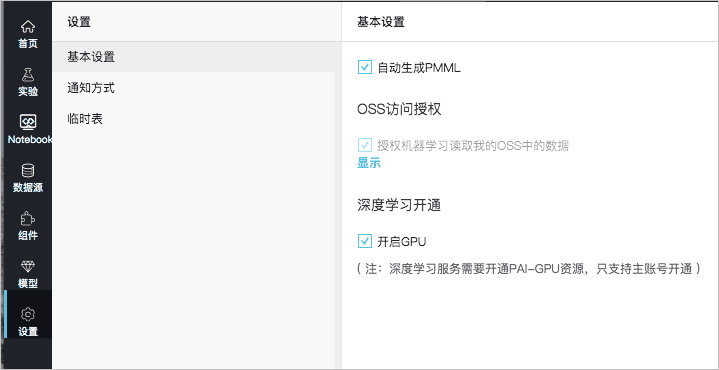
- 登录PAI控制台,并进入旧版可视化建模(Studio)页面,具体操作步骤,请参见使用DataWorks离线调度Studio实验。
- 单击左侧导航栏设置,在基本设置处开通GPU和OSS访问权限。
2.数据分桶
目前智能特征交叉组件只支持BIGINT型的数据交叉,考虑到平时业务中的原始数据通常是如下图所示的Double类型:
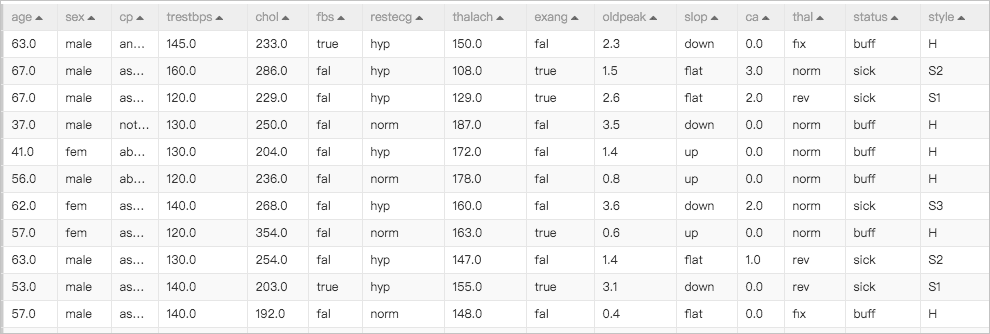
所以使用SQL组件或Onehot组件将字符型数据转为BIGINT型,另外需要使用特征离散组件进行特征分桶,将不同区间的特征按照分布的不同划分到不同的数据桶之中。数据经过分桶之后变为如下形态:
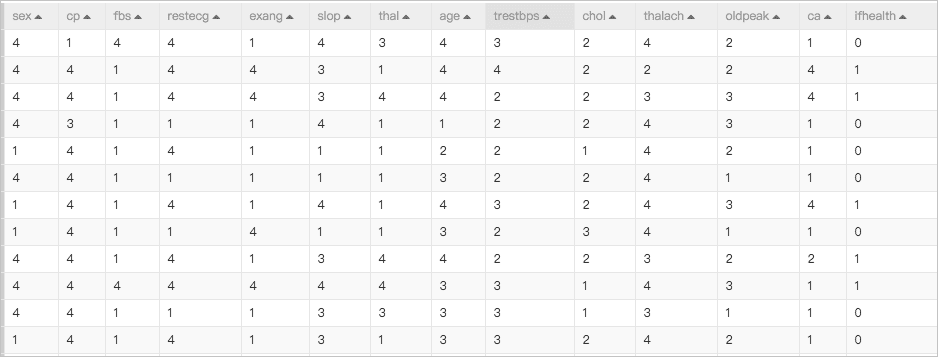
3.确定特征范围
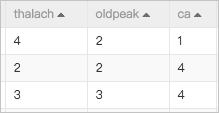
特征交叉的基本原理是将特征先按照向量空间展开,然后做特征间的相互交叉验证,最终挑选出合理的特征组合方式。在计算之前需要知道每个特征的空间的最大值,如下面这组数据:
- thalach的特征最大值为4
- oldpeak的特征最大值为3
- ca的特征最大值为4
执行如下SQL语句获取最大值。
select max(feature) from table;在本实验样例数据中,所有分桶完的特征的最大值均为4。

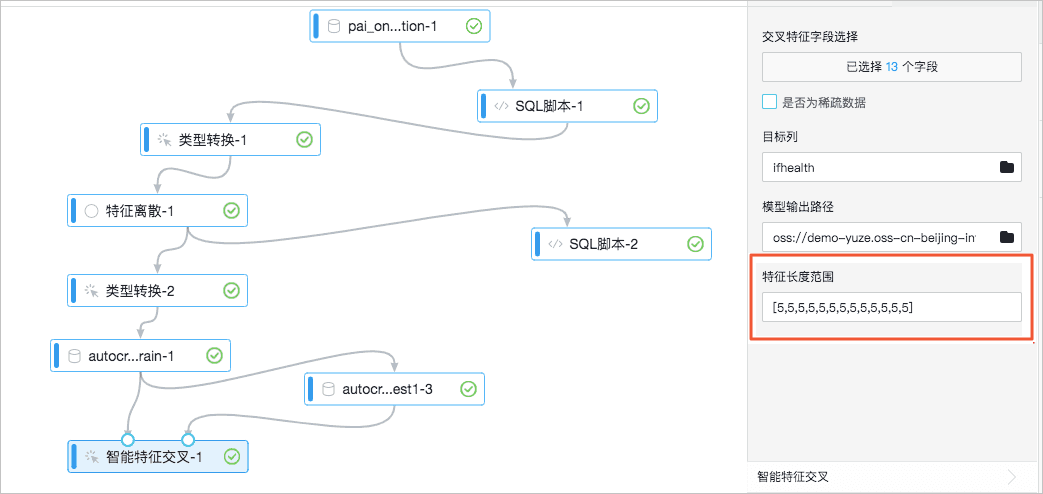
于是智能特征交叉的特征长度范围要写成如下图样式。其中5表示开区间[0,5),包含4。
4.生成训练和测试数据
本实验使用的训练数据和测试数据是相同的表,实际使用中也可以把测试数据替换成跟训练数据字段相同的不同表。
5.智能特征交叉
- 字段设置
输入桩左侧是训练数据,右侧是测试数据。
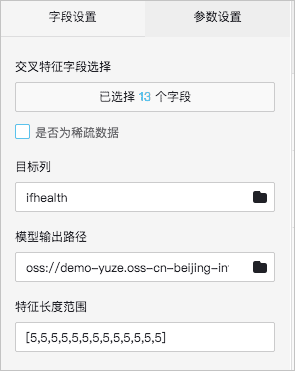
- 交叉特征字段选择:选择需要交叉验证的特征字段。
- 是否为稀疏数据:默认不选中。表示稠密数据。
- 目标列:选择目标列字段。
- 模型输出路径:生成的模型存于您的OSS中。
- 参数设置
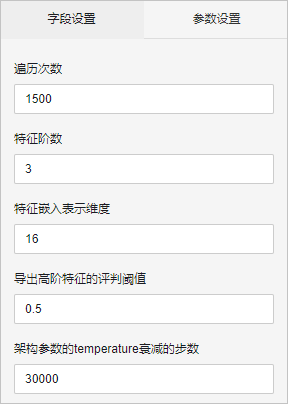
- 遍历次数:迭代次数。
- 特征阶数:指特征交叉阶数。如3,表示结果最多计算出3个特征之间的交叉。
PAI命令:
PAI -name fives_ext -project algo_public
-DlabelColName="ifhealth" //目标列
-Dmetric_file="metric_log.log" //日志
-Dfeature_meta="[5,5,5,5,5,5,5,5,5,5,5,5,5]"
-DtrainTable="odps://项目名/tables/表名"
-Dbuckets="oss://{oss_bucket}/"
-Dthreshold="0.5"
-Dk="3"
-DossHost="oss-cn-beijing-internal.aliyuncs.com" //区域
-Demb_dims="16"
-DenableSparse="0"
-Dtemp_anneal_steps="30000"
-DfeatureColName="sex,cp,fbs,restecg,exang,slop,thal,age,trestbps,chol,thalach,oldpeak,ca" //特征
-DtestTable="odps://项目名/tables/表名"
-Darn="acs:ram::********:role/aliyunodpspaidefaultrole" //rolearn
-Depochs="1500"
-DcheckpointDir="oss://{oss_bucket}/{path}/";结果查询
在OSS根目录下,亦即Dbuckets路径下找到interactions.json文件。
文件显示的是各种组合的关系,如下图所示。
结果显示的是一些启发性的特征交叉组合方式,您可以按照该特征进行特征组合,举例如下:
- [0,1]代表着第一个特征和第二个特征组合会有效果,特征顺序跟输入表的特征顺序一致。
- [8, 6, 5]代表一个三阶特征组合关系。第七个、第五个、第四个这三个特征组合起来会有效果。