数据迁移完成后,您还需要配置CDH上的HDFS服务、YARN服务、Hive服务、Spark服务、HBase服务,才能使用文件存储 HDFS 版。
配置Cloudera Management服务
执行以下命令,将最新的文件存储 HDFS 版Java SDK复制到Cloudera Management服务的lib目录下。集群中的每台机器都需要在相同位置添加文件存储 HDFS 版Java SDK。
cp aliyun-sdk-dfs-x.y.z.jar /opt/cloudera/cm/lib/cdh6/其中,
x.y.z为文件存储 HDFS 版Java SDK版本号,请根据实际值填写。重启服务。
登录CDH6的Cloudera Manager管理页面。
在主页页面,选择状态页签。
在左侧Cloudera Management Service区域,单击Cloudera Management Service右侧的
 图标 > 重启,重启服务。
图标 > 重启,重启服务。
配置HDFS服务
登录CDH6的Cloudera Manager管理页面。
在主页页面,选择配置 > 高级配置代码段,进入高级配置代码段页面。
在搜索框中输入core-site.xml进行搜索,在搜索结果HDFS的core-site.xml的群集范围高级配置代码段(安全阀)区域中,单击
 ,添加如下配置。
,添加如下配置。名称:fs.defaultFS。
值:dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290
其中
f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com为您的文件存储 HDFS 版挂载点地址,请根据实际情况进行修改。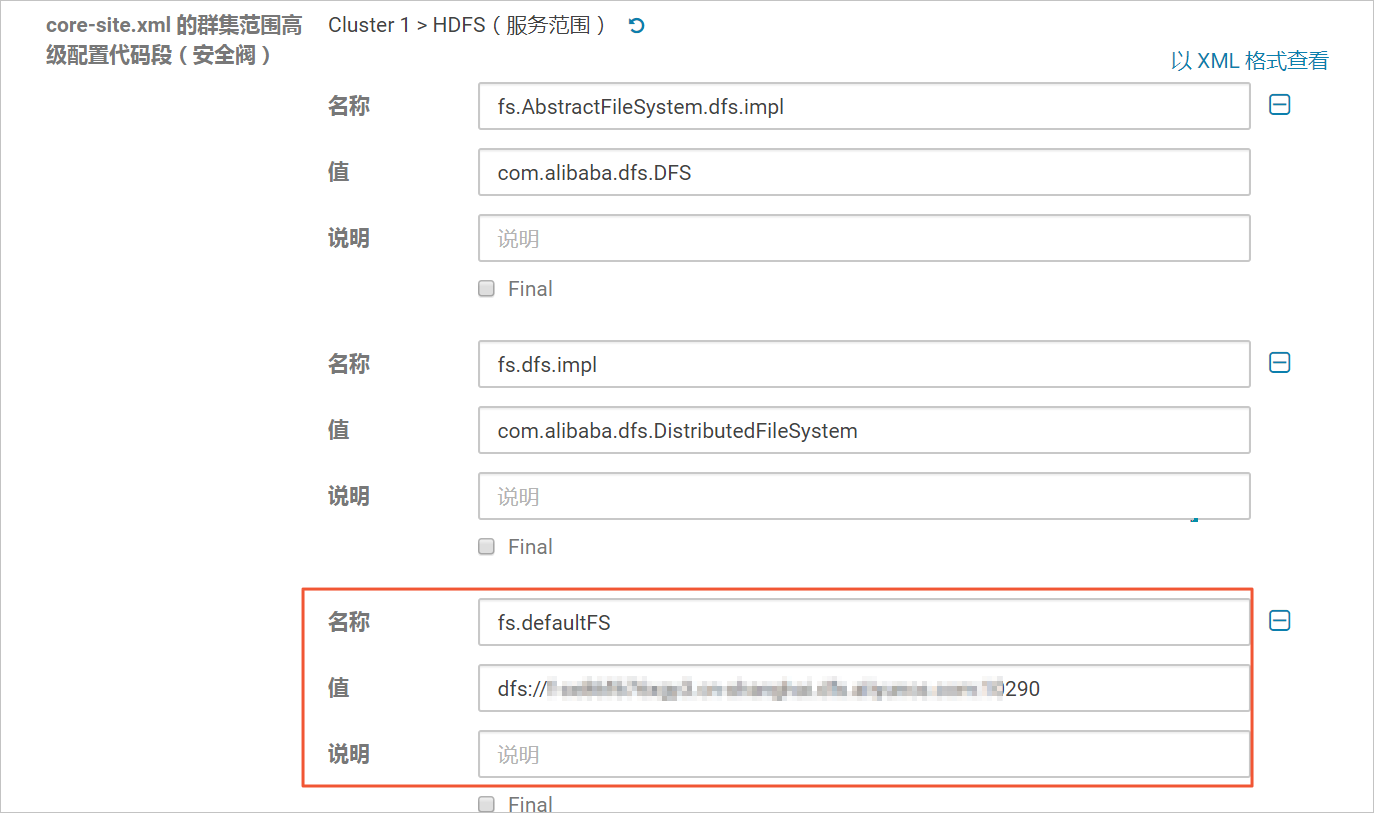
单击保存更改。
配置YARN服务
检查mapreduce.application.classpath配置。
登录CDH6的Cloudera Manager管理页面。
在主页页面,选择状态页签。
在左侧集群组件列表中,单击YARN(MR2 Included)右侧
图标 > 配置,进入YARN(MR2 Included)配置页面。在搜索框中输入mapreduce.application.classpath进行搜索,在搜索结果的MR应用程序Classpath区域中,检查确认已添加$HADOOP_HDFS_HOME/*配置。
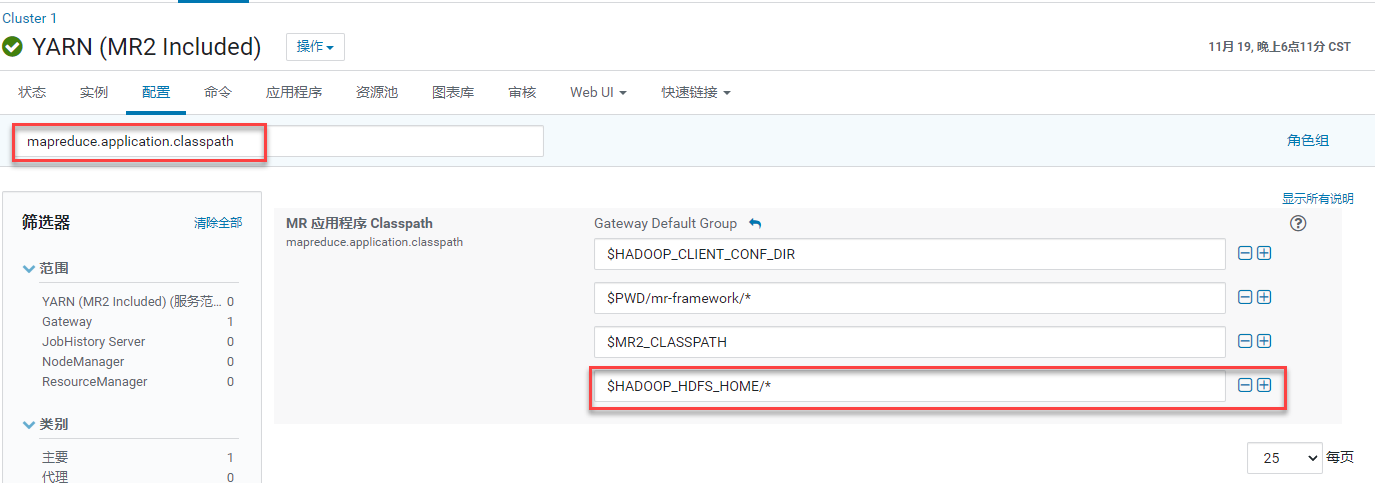 如果上述区域中没有$HADOOP_HDFS_HOME/*配置,请单击
如果上述区域中没有$HADOOP_HDFS_HOME/*配置,请单击 添加,然后单击保存更改。
添加,然后单击保存更改。
配置mapred-site.xml。
在搜索框中输入mapred-site.xml进行搜索。在搜索结果的YARN(MR2 Included)的YARN服务MapReduce高级配置代码段(安全阀)区域中,单击
添加如下配置项。名称:mapreduce.application.framework.path。
值:dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/user/yarn/mapreduce/mr-framework/3.x.x-cdh6.x.x-mr-framework.tar.gz#mr-framework。
其中,
f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com为您的文件存储 HDFS 版挂载点地址;3.x.x-cdh6.x.x-mr-framework为CDH MR框架文件,请根据实际情况进行修改。说明如果文件存储 HDFS 版实例中的
3.x.x-cdh6.x.x-mr-framework.tar.gz文件不存在,可能是因为此文件还没有从CDH的HDFS服务同步到文件存储 HDFS 版。您需要将HDFS服务/user/yarn目录下的所有内容同步到文件存储 HDFS 版上。具体操作,请参见CDH6数据迁移。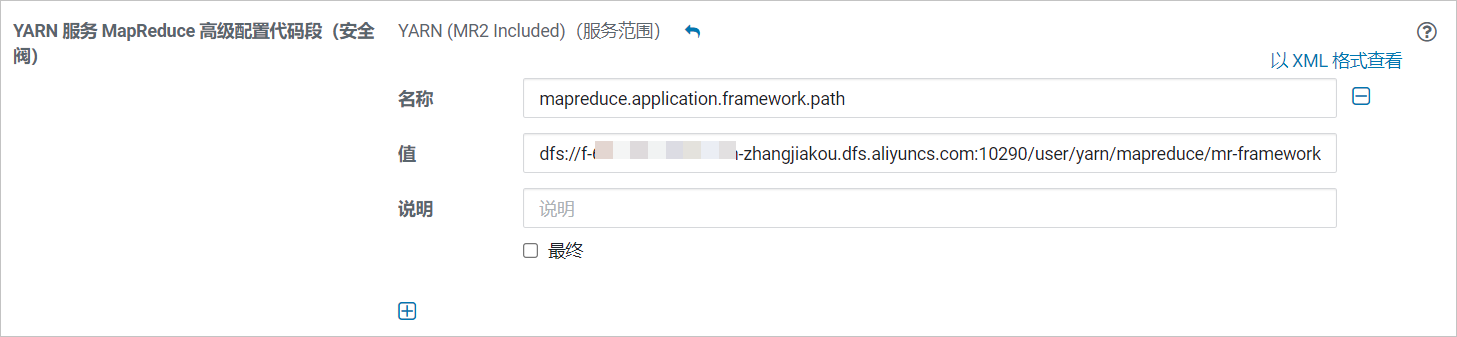
单击保存更改。
部署新配置并重启服务。
返回主页页面,选择状态页签。在左侧集群组件中,单击YARN(MR2 Included)右侧的
 图标,进入过期配置页面。
图标,进入过期配置页面。在过期配置页面,单击重启过时服务。
在重启过时服务页面,选中重新部署客户端配置后,单击立即重启。
在服务全部重启完成,并重新部署客户端配置后,单击完成。
配置Hive服务
配置HDFS服务完成后,才能配置Hive服务。
在配置Hive服务之前,请确认/user/hive/目录中的数据已完成全量迁移。具体操作,请参见步骤三:数据迁移。
修改元数据。
本文以修改Hive服务元数据存储在MySQL中的数据为例,修改DBS表和SDS表相应的存储系统的URL。
执行
use metastore;命令,进入存储Hive元数据的MySQL数据库。修改表DBS中的数据。
执行
SELECT * FROM DBS LIMIT 5;命令,查询表DBS中的数据。返回结果示例如下:+-------+-----------------------+----------------------------------------------------------------------------+-----------------------------+------------+------------+-------------+ | DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CREATE_TIME | +-------+-----------------------+----------------------------------------------------------------------------+-----------------------------+------------+------------+-------------+ | 1 | Default Hive database | hdfs://cdh6-master:8020/user/hive/warehouse | default | public | ROLE | 1629164990 | | 1826 | NULL | hdfs://cdh6-master:8020/user/hive/warehouse/tpcds_text_2.db | tpcds_text_2 | hive | USER | 1629702940 | | 1828 | NULL | hdfs://cdh6-master:8020/user/hive/warehouse/tpcds_bin_partitioned_orc_2.db | tpcds_bin_partitioned_orc_2 | hive | USER | 1629703145 | +-------+-----------------------+----------------------------------------------------------------------------+-----------------------------+------------+------------+-------------+ 3 rows in set (0.00 sec)更新DBS表中原HDFS地址为文件存储 HDFS 版挂载点地址。示例命令如下:
UPDATE DBS SET DB_LOCATION_URI=REPLACE(DB_LOCATION_URI,'hdfs://cdh6-master:8020','dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290');执行
SELECT * FROM DBS LIMIT 5;命令,查看地址是否已更换。+-------+-----------------------+-----------------------------------------------------------------------------------------------------------------+-----------------------------+------------+------------+-------------+ | DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CREATE_TIME | +-------+-----------------------+-----------------------------------------------------------------------------------------------------------------+-----------------------------+------------+------------+-------------+ | 1 | Default Hive database | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/user/hive/warehouse | default | public | ROLE | 1629164990 | | 1826 | NULL | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/user/hive/warehouse/tpcds_text_2.db | tpcds_text_2 | hive | USER | 1629702940 | | 1828 | NULL | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/user/hive/warehouse/tpcds_bin_partitioned_orc_2.db | tpcds_bin_partitioned_orc_2 | hive | USER | 1629703145 | +-------+-----------------------+-----------------------------------------------------------------------------------------------------------------+-----------------------------+------------+------------+-------------+ 3 rows in set (0.00 sec)
修改表SDS中的数据。
执行
SELECT * FROM SDS LIMIT 5;命令,查询表SDS中的数据。返回结果示例如下:+-------+-------+------------------------------------------+---------------+---------------------------+--------------------------------------------------------------+-------------+------------------------------------------------------------+----------+ | SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID | +-------+-------+------------------------------------------+---------------+---------------------------+--------------------------------------------------------------+-------------+------------------------------------------------------------+----------+ | 5423 | 1846 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://cdh6-master:8020/tmp/tpcds-generate/2/store_sales | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5423 | | 5424 | 1847 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://cdh6-master:8020/tmp/tpcds-generate/2/store_returns | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5424 | | 5425 | 1848 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://cdh6-master:8020/tmp/tpcds-generate/2/catalog_sales | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5425 | | 5426 | 1849 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://cdh6-master:8020/tmp/tpcds-generate/2/catalog_returns | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5426 | | 5427 | 1850 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://cdh6-master:8020/tmp/tpcds-generate/2/web_sales | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5427 | +-------+-------+------------------------------------------+---------------+---------------------------+--------------------------------------------------------------+-------------+------------------------------------------------------------+----------+ 5 rows in set (0.00 sec)更新SDS表中原HDFS地址为文件存储 HDFS 版挂载点地址。示例命令如下:
UPDATE SDS SET LOCATION=REPLACE(LOCATION,'hdfs://cdh6-master:8020','dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290');执行
SELECT * FROM SDS LIMIT 5;命令,查看地址是否已更换。+-------+-------+------------------------------------------+---------------+---------------------------+---------------------------------------------------------------------------------------------------+-------------+------------------------------------------------------------+----------+ | SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID | +-------+-------+------------------------------------------+---------------+---------------------------+---------------------------------------------------------------------------------------------------+-------------+------------------------------------------------------------+----------+ | 5423 | 1846 | org.apache.hadoop.mapred.TextInputFormat | | | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/tpcds-generate/2/store_sales | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5423 | | 5424 | 1847 | org.apache.hadoop.mapred.TextInputFormat | | | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/tpcds-generate/2/store_returns | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5424 | | 5425 | 1848 | org.apache.hadoop.mapred.TextInputFormat | | | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/tpcds-generate/2/catalog_sales | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5425 | | 5426 | 1849 | org.apache.hadoop.mapred.TextInputFormat | | | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/tpcds-generate/2/catalog_returns | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5426 | | 5427 | 1850 | org.apache.hadoop.mapred.TextInputFormat | | | dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/tpcds-generate/2/web_sales | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 5427 | +-------+-------+------------------------------------------+---------------+---------------------------+---------------------------------------------------------------------------------------------------+-------------+------------------------------------------------------------+----------+ 5 rows in set (0.00 sec)
重启服务。
登录CDH6的Cloudera Manager管理页面。
在主页页面,选择状态页签。
在左侧集群组件列表中,单击Hive右侧的
图标 > 启动。在启动确认框中,单击启动。
配置Spark服务
配置HDFS服务完成后,才能配置Spark服务。
配置Spark服务前,请确认/user/spark和/user/history目录中的数据已经完成了全量迁移。具体操作,请参见CDH6数据迁移。
执行以下命令将最新的文件存储 HDFS 版Java SDK复制到Spark服务的jars目录下。其中,x.y.z为文件存储 HDFS 版Java SDK版本号,请根据实际填写。
cp aliyun-sdk-dfs-x.y.z.jar /opt/cloudera/parcels/CDH/lib/spark/jars/集群中的每台机器都需要在相同位置添加文件存储 HDFS 版Java SDK。
配置HBase服务
配置HDFS服务完成后,才能配置HBase服务。
配置HBase服务前,请确认原HDFS集群HBase中的快照已迁移至文件存储 HDFS 版。具体操作,请参见HBase快照迁移。
登录CDH6的Cloudera Manager管理页面。
在主页页面,选择配置 > 高级配置代码段,进入高级配置代码段页面。
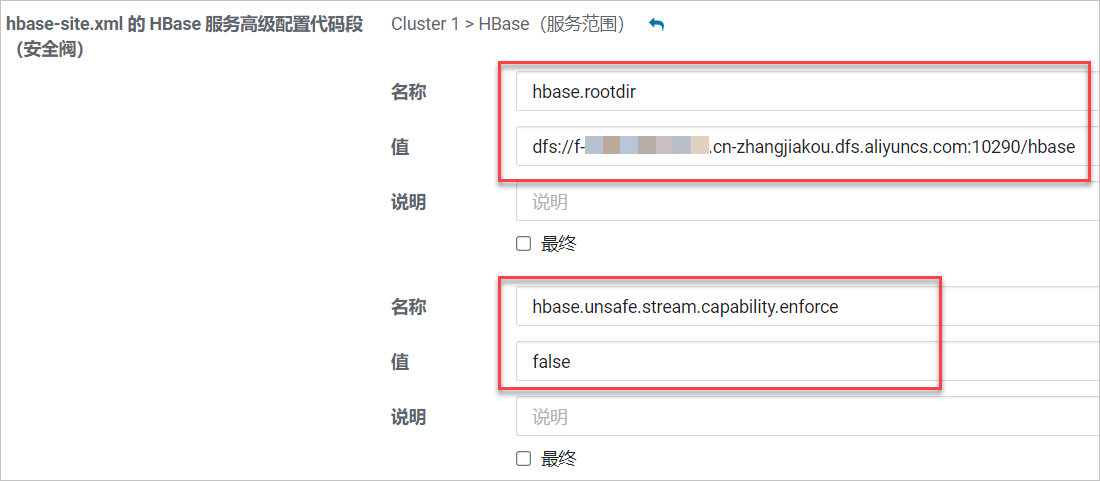
在搜索框中输入hbase-site.xml进行搜索。在搜索结果的hbase-site.xml的HBase服务高级配置代码段(安全阀)和hbase-site.xml的HBase客户端高级配置代码段(安全阀)区域中,均添加如下配置项。
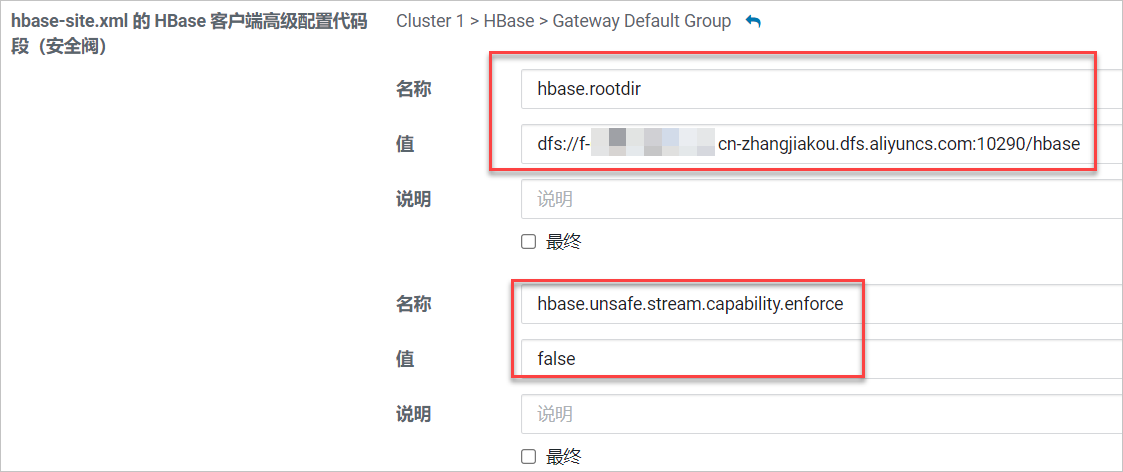
配置hbase.rootdir。
名称:hbase.rootdir
值:dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/hbase
其中
f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com为您的文件存储 HDFS 版挂载点地址,请根据实际情况进行修改。
配置hbase.unsafe.stream.capability.enforce。
名称:hbase.unsafe.stream.capability.enforce。
值:false
配置zookeeper.znode.parent。
zookeeper.znode.parent默认配置为/hbase,HBase服务配置文件存储 HDFS 版时需修改该配置,否则会与存储在Zookeeper中的数据冲突。
在主页页面,选择状态页签。
在左侧集群组件列表中,单击HBase右侧的
图标 > 配置,进入HBase配置页面。在搜索框中输入zookeeper.znode.parent进行搜索,在搜索结果的ZooKeeper Znode父级区域中,配置新的HBase根Znode(例如/hbase_dfs)。

单击保存更改。
部署新配置并重启服务。
返回状态页签,在左侧集群组件列表中,单击HBase右侧的
图标,进入过期配置页面。在过期配置页面,单击重启过时服务。
在重启过时服务页面,单击立即重启。
等待服务全部重启完成,并重新部署客户端配置后,单击完成。
(可选)快照恢复。
将存储在原HDFS集群的(可选)步骤三:HBase快照迁移到文件存储 HDFS 版后,可通过在HBase Shell中执行以下命令查看和恢复文件存储 HDFS 版中已经迁移的快照。
执行
list_snapshots命令,查看快照信息。SNAPSHOT TABLE + CREATION TIME mock_table_0_snapshot mock_table_0 (2021-11-19 17:25:38 +0800) mock_table_1_snapshot mock_table_1 (2021-11-19 17:25:47 +0800) 2 row(s) Took 0.4619 seconds => ["mock_table_0_snapshot", "mock_table_1_snapshot"]执行以下命令,恢复快照。
restore_snapshot 'mock_table_0_snapshot'restore_snapshot 'mock_table_1_snapshot'
停止HDFS服务
完成上述各项服务配置后,集群的HDFS服务已经替换为文件存储 HDFS 版,建议您停止集群的HDFS服务。
您可以在主页页面,选择状态页签。在左侧集群组件中,单击HDFS右侧的图标 > 停止,停止HDFS服务。
停止HDFS服务前,请确认HDFS所有需要迁移的数据都已被迁移,停止HDFS服务后将无法迁移数据。具体操作,请参见CDH6数据迁移。
验证服务正确性
根据以下步骤,依次对YARN服务、Hive服务、Spark服务、HBase服务进行验证。如果数据无异常,则表示CDH中的服务已经迁移到文件存储 HDFS 版。
YARN服务验证
使用CDH Hadoop中自带包hadoop-mapreduce-examples-3.x.x-cdh6.x.x.jar进行测试,在/tmp/randomtextwriter目录下生成大小约为128 MB的文件,示例命令如下。
yarn jar \ /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-examples-*-cdh*.jar \ randomtextwriter \ -D mapreduce.randomtextwriter.totalbytes=134217728 \ /tmp/randomtextwriter执行以下命令验证YARN服务与文件存储 HDFS 版实例的连通性。
hadoop fs -ls dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/randomtextwriter如果看到_SUCCESS和part-m-00000两个文件,表示YARN服务与文件存储 HDFS 版实例连通成功。

Hive服务验证
数据迁移验证
本文以原HDFS集群TPC-DS的数据已迁移到文件存储 HDFS 版为例,进行数据迁移验证。
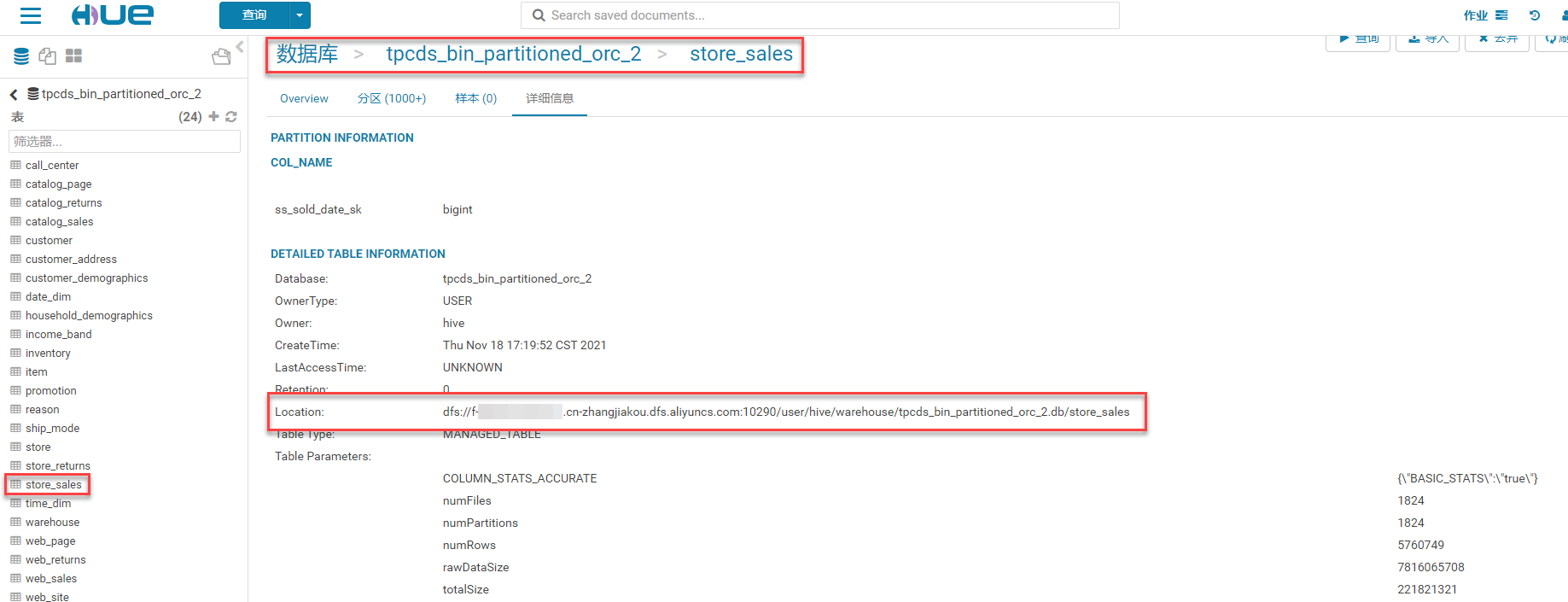
登录Hue管理控制台,查看store_sales表详细信息中的Location是否已变更为配置Hive服务时修改的文件存储 HDFS 版挂载点地址。
执行一条SQL语句,验证Hive服务与文件存储 HDFS 版实例之间的连通性。
SELECT * FROM (SELECT i_manager_id , sum(ss_sales_price) sum_sales , avg(sum(ss_sales_price)) over (partition BY i_manager_id) avg_monthly_sales FROM item , store_sales , date_dim , store WHERE ss_item_sk = i_item_sk AND ss_sold_date_sk = d_date_sk AND ss_store_sk = s_store_sk AND d_month_seq IN (1211, 1211+1, 1211+2, 1211+3, 1211+4, 1211+5, 1211+6, 1211+7, 1211+8, 1211+9, 1211+10, 1211+11) AND ((i_category IN ('Books', 'Children', 'Electronics') AND i_class IN ('personal', 'portable', 'reference', 'self-help') AND i_brand IN ('scholaramalgamalg #14', 'scholaramalgamalg #7', 'exportiunivamalg #9', 'scholaramalgamalg #9')) or(i_category IN ('Women','Music','Men') AND i_class IN ('accessories','classical','fragrances','pants') AND i_brand IN ('amalgimporto #1','edu packscholar #1','exportiimporto #1', 'importoamalg #1'))) GROUP BY i_manager_id, d_moy) tmp1 WHERE CASE WHEN avg_monthly_sales > 0 THEN ABS (sum_sales - avg_monthly_sales) / avg_monthly_sales ELSE NULL END > 0.1 ORDER BY i_manager_id , avg_monthly_sales , sum_sales LIMIT 100;查看SQL结果。如果回显正常,则表示Hive服务与文件存储 HDFS 版实例之间的连通性正常。
新建数据表验证
在Hue中创建表并查看表信息。
DROP TABLE IF EXISTS user_info_test; CREATE TABLE user_info_test(user_id BIGINT, firstname STRING, lastname STRING, country STRING); INSERT INTO user_info_test VALUES(1,'Dennis','Hu','CN'),(2,'Json','Lv','Jpn'),(3,'Mike','Lu','USA');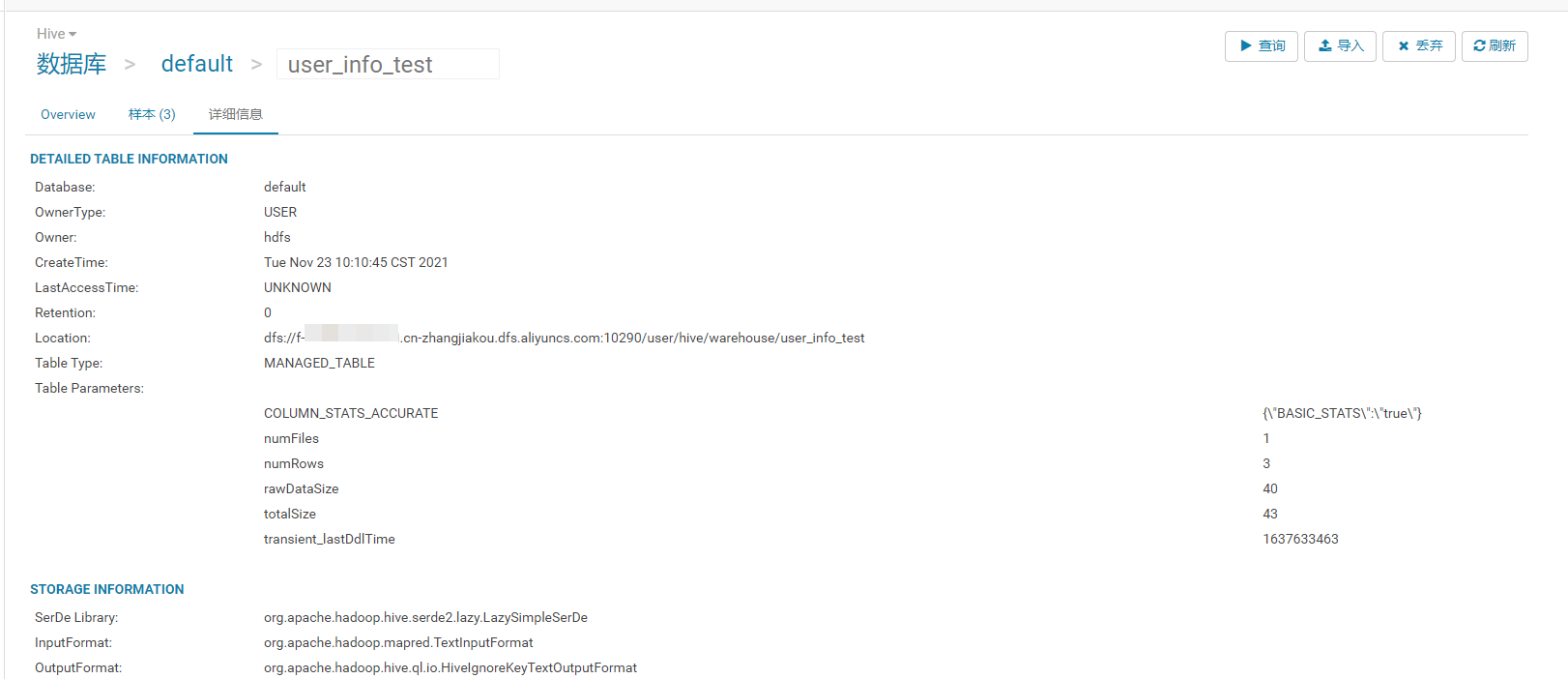
执行以下命令,查询SQL。
SELECT country,count(*) AS country_count FROM user_info_test GROUP BY country;如果回显正常,则表示Hive服务与文件存储 HDFS 版实例之间的连通性正常。
Spark服务验证
使用CDH Spark中自带包spark-examples_*-cdh*.jar从本地读取文件写入文件存储 HDFS 版实例。
spark-submit \ --master yarn \ --executor-memory 2G \ --executor-cores 2 \ --class org.apache.spark.examples.DFSReadWriteTest \ /opt/cloudera/parcels/CDH/jars/spark-examples_*-cdh*.jar \ /etc/profile /tmp/sparkwrite执行以下命令,查看是否写入成功。
hadoop fs -ls dfs://f-xxxxxxxx.cn-zhangjiakou.dfs.aliyuncs.com:10290/tmp/sparkwrite/*如果看到返回信息中包含如下信息,则表示写入成功。

HBase服务验证
数据迁移验证
查看迁移到文件存储 HDFS 版两张表的数据行数(表mock_table_0和表mock_table_1)。示例如下:
hbase(main):001:0> list TABLE mock_table_0 mock_table_1 2 row(s) Took 0.3587 seconds => ["mock_table_0", "mock_table_1"] hbase(main):002:0> count 'mock_table_0' Current count: 1000, row: 001637311398 ........ Current count: 100000, row: 991637311398 100000 row(s) Took 7.2724 seconds => 100000 hbase(main):003:0> count 'mock_table_1' Current count: 1000, row: 001637311398 ........ Current count: 100000, row: 991637311398 100000 row(s) Took 3.9399 seconds => 100000新建数据表验证
使用HBase Shell创建测试表(例如hbase_test)并插入数据。示例如下:
hbase(main):001:0> create 'hbase_test','info' Created table hbase_test Took 1.7688 seconds => Hbase::Table - hbase_test hbase(main):002:0> list TABLE hbase_test mock_table_0 mock_table_1 3 row(s) Took 0.0147 seconds => ["hbase_test", "mock_table_0", "mock_table_1"] hbase(main):003:0> put 'hbase_test','1', 'info:name' ,'Sariel' Took 0.2415 seconds hbase(main):004:0> put 'hbase_test','1', 'info:age' ,'22' Took 0.0053 seconds hbase(main):005:0> put 'hbase_test','1', 'info:industry' ,'IT' Took 0.0631 seconds hbase(main):006:0> scan 'hbase_test' ROW COLUMN+CELL 1 column=info:age, timestamp=1637636289233, value=22 1 column=info:industry, timestamp=1637636299912, value=IT 1 column=info:name, timestamp=1637636279553, value=Sariel 1 row(s) Took 0.0227 seconds在文件存储 HDFS 版上的HBase数据目录查看是否有新建的测试表。

常见问题
SecondaryNameNode服务停止。
根据文档操作步骤配置文件存储 HDFS 版后,CDH中的HDFS服务会报错,报错信息:SecondaryNameNode服务无法启动。这是由于SecondaryNameNode服务需要通过http get方式获取NameNode的fsimage与edits文件进行工作。而文件存储 HDFS 版不提供HTTP服务,所以SecondaryNameNode服务无法启动。此时,CDH内的Spark\Hive\Hbase服务已经使用阿里云文件存储 HDFS 版读写数据,CDH自身的HDFS服务问题不会影响系统运行和数据安全。
Hue服务文件浏览器不可用。
Hue是通过WebHDFS REST API访问HDFS上的文件。文件存储 HDFS 版暂不支持WebHDFS REST API,因此不可以在Hue上直接操作文件存储 HDFS 版实例上的文件。
后续步骤
- 本页导读 (1)