本文为您介绍构建MaxCompute数据仓库的流程。
构建MaxCompute数据仓库的整体流程如下。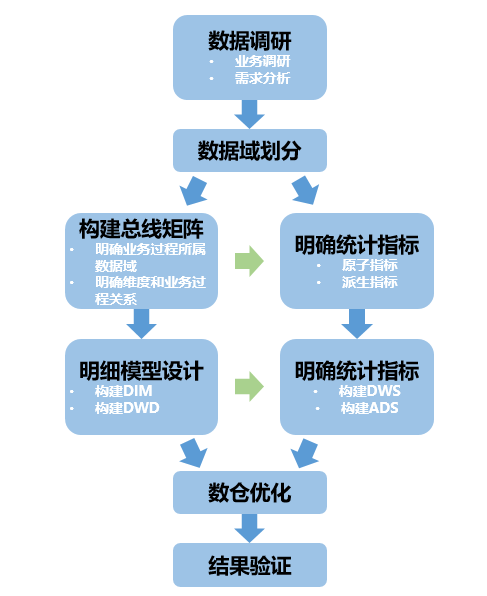

基本概念
在正式学习本教程之前,您需要首先理解以下基本概念:
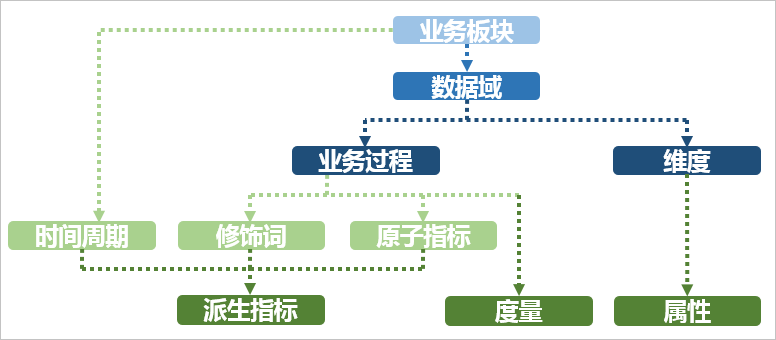
- 业务板块:比数据域更高维度的业务划分方法,适用于庞大的业务系统。
- 维度:维度建模由Ralph Kimball提出。维度模型主张从分析决策的需求出发构建模型,为分析需求服务。维度是度量的环境,是我们观察业务的角度,用来反映业务的一类属性。属性的集合构成维度,维度也可以称为实体对象。例如,在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
- 属性(维度属性):维度所包含的表示维度的列称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
- 度量:在维度建模中,将度量称为事实,将环境描述为维度,维度是用于分析事实所需要的多样环境。度量通常为数值型数据,作为事实逻辑表的事实。
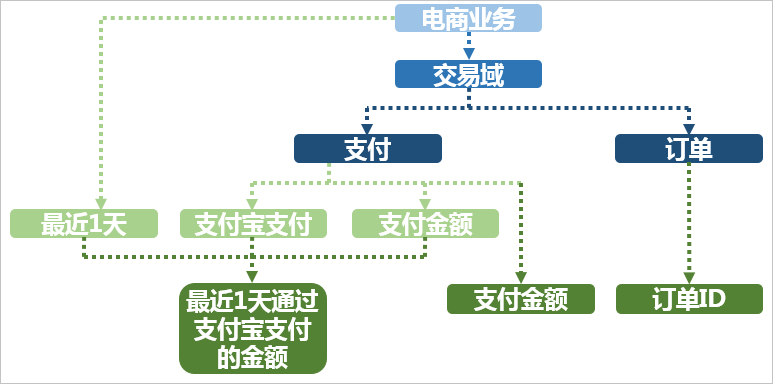
- 指标:指标分为原子指标和派生指标。原子指标是基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,是具有明确业务含义的名词,体现明确的业务统计口径和计算逻辑,例如支付金额。
- 原子指标=业务过程+度量。
- 派生指标=时间周期+修饰词+原子指标,派生指标可以理解为对原子指标业务统计范围的圈定。
- 业务限定:统计的业务范围,筛选出符合业务规则的记录(类似于SQL中where后的条件,不包括时间区间)。
- 统计周期:统计的时间范围,例如最近一天,最近30天等(类似于SQL中where后的时间条件)。
- 统计粒度:统计分析的对象或视角,定义数据需要汇总的程度,可理解为聚合运算时的分组条件(类似于SQL中的group by的对象)。粒度是维度的一个组合,指明您的统计范围。例如,某个指标是某个卖家在某个省份的成交额,则粒度就是卖家、地区这两个维度的组合。如果您需要统计全表的数据,则粒度为全表。在指定粒度时,您需要充分考虑到业务和维度的关系。统计粒度常作为派生指标的修饰词而存在。

